【2024CANN训练营】Ascend C笔记
昇腾AI处理器概述
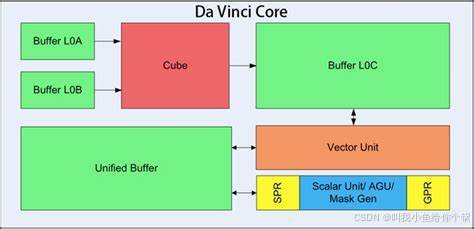
架构
- 自研达芬奇架构
- 高集成SoC设计,专为AI计算优化。
- 算力、内存、带宽的最优配比,提升整体性能。
- 16x16x16大Cube设计,高效矩阵乘法计算。
异腾CANN架构
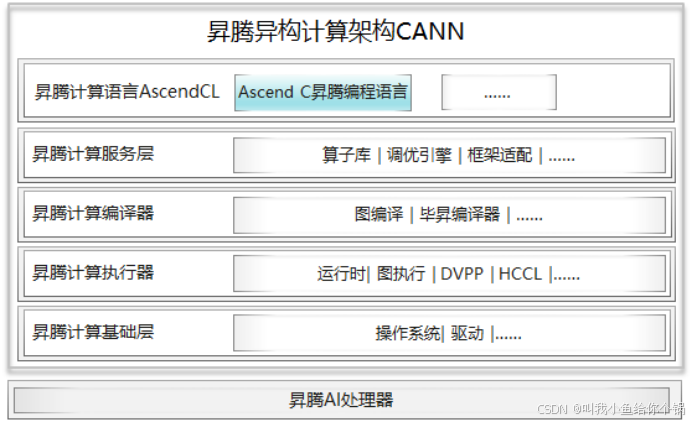
- 功能:支持大模型并行计算加速和高效原生开发。
- 兼容性:支持业界主流AI框架,如PyTorch、TensorFlow等。
- 开发周期:典型场景下,算子开发周期缩短至2人周以内。
CANN架构的兼容性与高效开发能力,极大地缩短了AI项目的开发周期。
- 协同:实现CPU与NPU的协同编码,提升计算能力。
- 资源管理:操作系统支持NPU资源管理与调度。
自动调优引擎AOE
AOE通过生成调优策略、编译、在运行环境上验证的闭环反馈机制,不断迭代,最终得到最佳的调优策略,从而更充分利用硬件资源,提升网络的性能。
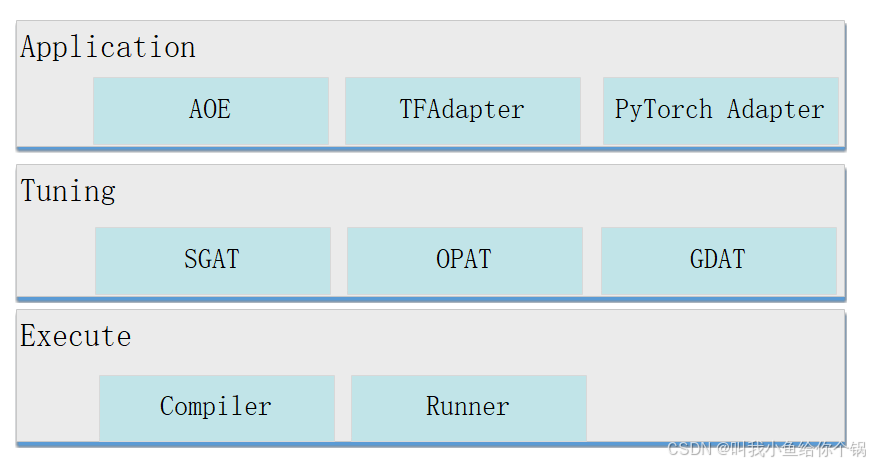
图片来源自动调优工具AOE,让你的模型在昇腾平台上高效运行
- 性能:实现性能与效率的双效提升。
- 优化效果:如ResNet50性能提升137%,调优时间缩短一倍。
高性能基础算子库
- 覆盖Transformer网络和多种深度学习算法。
- 包括DVPP、AIPP、BLAS和HCCL等算子库。
二进制算子库
- 优势:提供动态shape二进制算子包,消除编译耗时。
- 性能:根据输入shape选择最优调度模板执行。
异腾图优化引擎
- 技术:自动流水、算子深度融合、整图下沉等。
- 效果:减少数据搬运,提高内存使用率。
软硬协同优化技术
- 加速
训练加速和推理加速。
- 资源利用
充分利用内存和计算资源,减少Host/Device交互。
AscendC算子编程语言
- 简化:降低算子编程难度,提升开发效率。
- 特性:自动化流水并行调度,结构化核函数编程。
AscendC语言的自动化调度功能大大简化了开发流程,使得开发者可以更专注于算法本身。
AICore内部并行计算架构
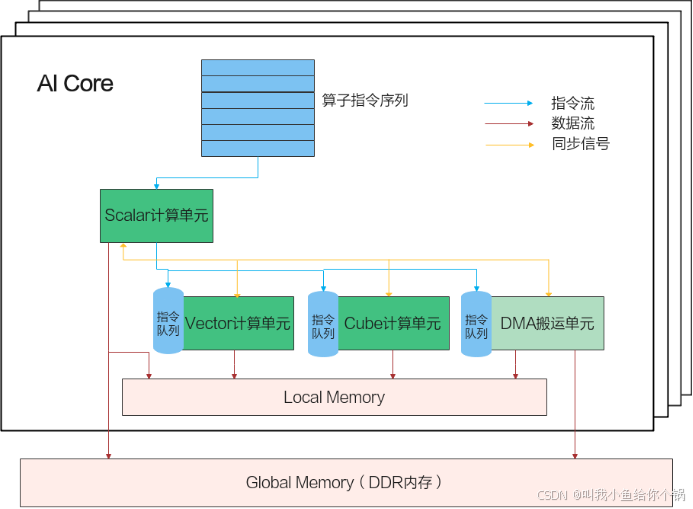
- 包含计算单元、存储单元、搬运单元。
- 异步指令流和数据流,同步信号确保正确执行。
AI Core内部的异步并行计算过程:Scalar计算单元读取指令序列,并把向量计算、矩阵计算、数据搬运指令发射给对应单元的指令队列,向量计算单元、矩阵计算单元、数据搬运单元异步并行执行接收到的指令。该过程可以参考上图中蓝色箭头所示的指令流。不同的指令间有可能存在依赖关系,为了保证不同指令队列间的指令按照正确的逻辑关系执行,Scalar计算单元也会给对应单元下发同步指令。各单元之间的同步过程可以参考上图中的橙色箭头所示的同步信号流。
编程范式
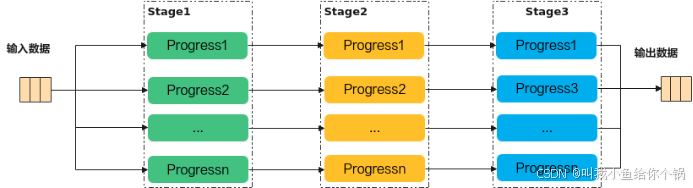
Ascend C编程范式是一种流水线式的编程范式,把算子核内的处理程序,分成多个流水任务,通过队列(Queue)完成任务间通信和同步,并通过统一的内存管理模块(Pipe)管理任务间通信内存。流水编程范式应用了流水线并行计算方法。
小结
昇腾AI处理器通过其自研达芬奇架构和高集成SoC设计,实现了高性能的AI计算。异腾CANN架构和自动调优引擎AOE进一步提升了开发效率和性能。软硬协同优化技术和计算图执行下沉技术,以及AscendC算子编程语言,共同为开发者提供了一个高效、易用的开发环境。二进制算子库和异腾图优化引擎等技术,确保了在不同场景下都能达到最优的性能。端到端的工具支持,使得从算子开发到模型部署的全流程更加高效。
算子
- 算子名称:网络中唯一标识,如Conv1、Pool1、Conv2等。
- 算子类型:决定算子实现的逻辑,如Convolution表示卷积运算。
- 数据容器:张量(Tensor),承载算子的输入和输出数据。
数学算子的引入使得神经网络能够进行复杂的非线性变换,正是这些算子让深度学习模型拥有强大的表达能力。
算子属性
- 轴(Axis):表示张量中维度的下标,可为负表示倒数维度。
- 形状(Shape):描述张量的维度和大小,如(4, 20, 20, 3)。
AscendC算子
- 定义
使用AscendC编程语言开发的算子。
- 优势
提供多层接口抽象、自动并行计算、高效调试等。
AscendC算子的多层接口抽象和自动并行计算,显著提高了开发效率和计算性能,为开发者带来了极大的便利。
Device模块
- 功能
管理计算设备,包括设备设置、资源分配和释放。
- 组件
包括Host、PCIE、NPU、AICORE、GlobalMem等。
小结
算子是神经网络中的基本单元,具有名称、类型和数据容器。AscendC算子通过AscendC编程语言实现,提供高效开发和调试。Device模块管理计算设备,而自定义算子开发适用于特定推理、训练和性能调优场景。
算子作为神经网络中的核心组件,其设计和优化直接关系到模型的性能和效率。通过华为昇腾的高效开发工具和优化技术,开发者可以更加专注于创新和应用的实现。
核函数编写与调用
变量类型限定符
- Global Memory
使用 gm 表示指针指向Global Memory。
使用宏 GM_ADDR_gmuint8_t* _restrict 简化定义。
函数类型限定符
- 核函数标识
使用 _global 和 _aicore 标识核函数,分别表示可被设备调用和在设备侧执行。
核函数调用
- 内核调用符
使用特殊的内核调用符 <<<...>>>,包括执行配置如 blockDim 和 stream。
示例:
extern "C" __global__ __aicore__ void add_custom(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z);
- extern "C"表示核函数按照类C的编译和连接规约来编译和连接
- __global__函数类型限定符表示它是一个核函数
- __aicore__函数类型限定符表示该核函数在device侧的AI Core上执行
- 参数列表中的变量类型限定符__gm__,表明该指针变量指向Global Memory上某处内存地址
算子开发基础
编程范式
- 流水任务
核函数内部通过 Stage 实现数据并行处理。
- SPMD模型
AscendC 采用 SPMD 模型进行数据并行,使用 block_idx 区分不同核。
类库API
AscendC 使用标准C++语法和类库API,包括数学库、基础API、内存管理等。
Device模块
- 管理设备
包括设置、重置、获取设备和运行模式。
自定义算子开发场景
- 需求
当遇到不支持的算子或需要性能优化时,需开发自定义算子。
编程范式详解
Ascend C编程范式
- 并行处理
- 通过 Stage 实现数据分片的并行处理。
Ascend C编程范式是一种流水线式的编程范式,把算子核内的处理程序,分成多个流水任务,通过队列(Queue)完成任务间通信和同步,并通过统一的内存管理模块(Pipe)管理任务间通信内存。
TPIPE范式
- 简化并行编程
- 通过队列实现任务间通信和同步。
SPMD并行编程-多核
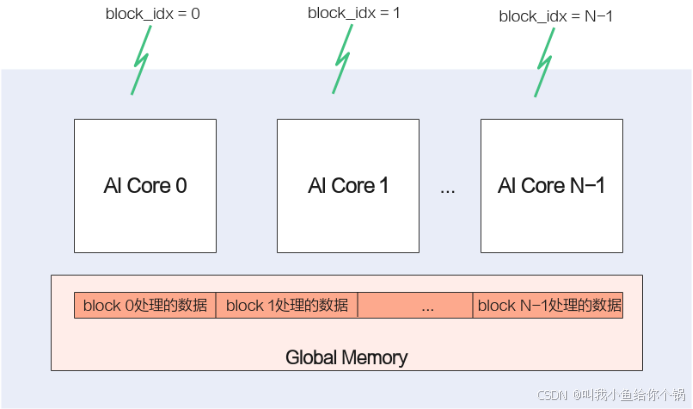
SPMD(Single-Program Multiple-Data)数据并行的方法,简单说就是将数据分片,每片数据经过完整的一个数据处理流程。这个就能和昇腾AI处理器的多核匹配上了,我们将数据分成多份,每份数据的处理运行在一个核上,这样每份数据并行处理完成,整个数据也就处理完了。
小结
以上内容涵盖了核函数编写与调用、算子开发基础、AscendC编程模型、算子类实现、编程范式、任务间通信以及AscendC算子的优势等多个方面。通过这些技术与工具,开发者能够高效地开发和调试AI算子,实现高性能的AI计算。
华为昇腾AI处理器及其相关开发工具不仅在硬件层面提供了强大的计算能力,还在软件层面通过多种优化技术和便捷工具,极大提升了开发者的工作效率和开发体验。通过这些技术的应用,AI技术的落地和应用变得更加快速和高效。