 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
Michael Stonebraker祖师爷和Andrew Pavlo大师合作的《What Goes Around Comes Around… And Around…》发表在sigmod2024上,作为二十年一个轮回的综述文章,这篇文章宏观上很好的概括了过去两个十年内数据模型和查询语言的演进,并由此引出几种典型系统的消亡史。
站在前人的肩膀上,我们得以审视自己所处细分领域内产品正处于历史前进中的哪个阶段,并由此看到哪个市场才是可以夺下的份额,并基于此判断用有限的人力投入到利益最大化的方向上,达到较优人效比,驱动团队不断进步。
论文概述
文章开篇分析了过去20年内典型的八种数据模型与对应的查询语言,并得出结论:object-relational已经统治了所有竞争者。
- MapReduce:MR系统已死,但是带来了共享磁盘架构的复兴,随后产生了开放源代码文件格式和数据湖;其次带来了像Spark,Flink这样新的数据处理平台。
- KV:文中将KV划分为分布式KV系统和单机KV存储引擎,并认为KV模型过于简单,很多系统都是从KV演进到其他更为复杂的关系模型,比如文档,
object-relational,所以文中看衰分布式KV;其次文中认为使用单机KV引擎可以加速DBMS的开发,从技术上可以长久发展。我和文中的看法不太一样,虽然事实[1]证明分布式KV并不适合作为统一的存储层,但是分布式KV最大的优势是可预测的性能和开箱即用的接口,内存KV更是有着无与伦比的性能优势,这些对于很多业务模型简单的业务来说有着很强的吸引力;但是确实增量市场疲软,没有明确的目标场景(所有业务都能用,也可以不用),大公司可以凭借存量市场养活团队,初创公司仅凭kv是完全不够的。 - 文档:SQL标准在2016年添加了JSON数据类型和操作[2],以及NoSQL DBMS开始支持SQL,后面这两种系统将会逐渐融合。
- Column-Family Database:在2010年代初期,谷歌在BigTable之上构建了RDBMS,包括MegaStore和Spanner的第一个版本,之后谷歌重写了Spanner,去除了BigTable的残余部分;其次Cassandra用CQL替换了Thrift-API,HBase推荐使用Phoenix SQL;
- Text Search Engines:文本数据本质上是无结构的,这意味着没有数据模型;虽然所有领先的RDBMS都支持全文搜索索引,但是将搜索操作集成到SQL中通常很麻烦,并且在不同的DBMS之间有所不同。所以仍旧有可观的市场。
- Array Databases:多维数组模型,时序模型其实也属于这个范畴,与关系型最大的不同是需要在多维度上实现高效的搜索性能,这意味着大量的索引数据,这通常在架构上要求独立的索引模块,对所有维度建立索引,而且存储引擎一般有独立的实现(业界目前的最优解决方案是双引擎)。一般这种数据库的开发人力不会很多,方言计算引擎投入人力太大,而且漏洞较多,市场上目前已经全面向SQL靠拢。
- Vector Databases:向量数据库本质上是具有专门 ANN 索引的数据库管理系统,这是一个特性,而不是一个新系统架构的基础。
- Graph Databases:一些关系数据库管理系统类似MsSQL 和 Oracle 提供了内置的 SQL 扩展,使存储和查询图数据更加容易,其他数据库管理系统使用关系之上的转换层来支持面向图的 API,Amazon Neptune 是 Aurora MySQL 上的面向图的表层。Apache AGE 在 PostgreSQL 之上提供了一个 OpenCypher 接口。图数据库本身市场足够庞大,专有图数据库的优势需要足够突出,得到性能,成本方面的口碑,以此拿到更多的客户,否则很容易被利用现有设施的小投入团队半道劫胡。且SQL:2023 引入了属性图查询(SQL/PGQ),用于在关系数据库管理系统中定义和遍历图[3]。
其次文中分析了这二十年间DBMS的新趋势:
- Columnar Systems:列式系统拥有专门的优化器、执行器和存储格式,因为卓越的性能,目前已经接管了数据仓库市场。
- Cloud Databases:随着对象存储的崛起,存算分离的优势被扩大,论文认为共享存储将主导DBMS架构,因此,文中不认为未来会出现shared-nothing架构。
- Data Lakes / Lakehouses:传统的数据仓库会把数据从各种专有数据库定期导入数仓,并在数仓中统一赋能企业;采用数据湖架构,应用程序将文件上传到分布式对象存储,绕过了通过DBMS的传统途径,通常使用开源的文件格式,例如Parquet,ORC,Tsfile等,然后用户使用支持从对象存储读取文件OLAP系统进行分析,值得注意的是这些系统通常提供了基于Python的notebook,DataFrame 来访问数据,而不是SQL。这一整套架构称为lakehouse。
- 硬件加速:在[5]中提到盘古团队的FPGA团队投入20个人/两年去做卸载CPU计算,并基于盘古让全公司收益。那篇论文中可以看到这是极其具有勇气的团队才可以作出的决策,因为硬件加速需要在动手钱判断产出,否则不具备经济效益。本篇文章持相同态度,并认为唯一能够成功使用定制硬件加速器的地方就是大型云供应商,其他厂商不具备大型商业化的能力,原因是:**一个仅生产硬件的公司必须找到某个DBMS添加对其加速器的支持。如果加速器是DBMS的可选附加组件,那么采用率将会很低,因此DBMS供应商不会愿意花费工程时间来支持它。如果加速器是DBMS的关键组件,那么没有供应商会将如此重要部分的开发外包给外部供应商。**当然定制硬件也是同样的道理,比如存储机型,计算机型的高度定制化。
- NewSQL,区块链两个章节读者可以自行翻阅文章。
对历史的总结非常有趣:
永远不要低估良好营销对糟糕产品的价值:数据库市场竞争激烈且利润丰厚,而且用户粘性较强,好的营销可以为产品带来更长的发展时间和场景磨练。- 要警惕大型非专业数据库供应商的产品:避免“not invented here”的大型公司会倾向于自研新系统,这会导致没有工程经验的团队开始构建新系统,我们应该警惕这样的系统,因为它们几乎总是不成熟的技术,且充满技术债,且不会拥有很长的生命周期。
- 不要忽视开箱即用的体验:简单清晰的入门教程和使用方式是巨大优势
- 人工智能/机器学习(AI/ML)对DBMS的影响将是巨大的:我其实不关心LLM在将自然语言转换为SQL的场景,目前来看参数调优才是一个很大的应用场景,随着系统的复杂,基于阈值判断的简易调度算法无法很好的预估复杂参数组合后对系统的影响。
从DBMS演化看时序数据库市场发展方向
二十年的经验告诉我们NoSQL领域的发展就是思考如何不被SQL抢走自己的市场的同时如何可以从SQL市场中抢下一块肉。
从我目前参与的KV和时序模型来看:
- 以Redis和兼容Redis的内存KV拥有精确的目标用户,并积极扩展模态试图以性能和易用性为刀刃扩大市场
- SSD KV瞄准易用性,价格与可预测的性能,目标为模型简单的业务,但是增量市场疲软
- 时序模态目标场景明确,且仍旧存在巨大的增量市场。从承载公司内时序数据入手打磨产品,且随着良好的营销,有机会从时序发力的业务领域入手,在云上抢下OLAP的部分市场。
时序数据库从近几年的发展来看不存在技术护城河,且随着开源模块化组件的发展,愿意投入基本上两年就可以达到一线的性能,压缩比水平。
不同的典型用户会有不同的功能需求,基于不同的开发语言,其中部分目前无法通过开源组件实现,即不同的功能是不同客户竞标的入场券,其次是成本和稳定性,最后才是性能(太差也不行)。
时序数据库的发展到现在整体架构已经非常类似数仓,上一代基于本地存储引擎的优化虽然拥有比对象存储+分析引擎更强的性能,但是成本仍旧较高,所以融合两者优势极其迫切;
其次对象存储+分析引擎本身可以做到和开源OLAP相同的功能与性能,伴随着特殊优化的更高效的近时查询,我认为未来物联网,工业物联网,车联网等等时序发力的领域将拿下OLAP的部分份额(这部分本来是EMR系统和宽表的)。
市场解决方案
TDengine
TDengine对自己产品的定位是物联网、工业大数据平台,其系统内部包含时序数据库,流式计算,缓存,消息队列等独立功能,边云协同,基于此提供解决方案。

官网对自己功能的定义也只有四个数据清洗,存储,分析,导出,从这里就可以看出Tdengine是想成为时序领域的数仓。当内部存储完全使用对象存储降低成本后,俨然成为了Lakehouses。

涛思数据的官网阐述了六种行业解决方案,事实上从技术的角度讲其实就只有三种:
独立节点级别边云协同: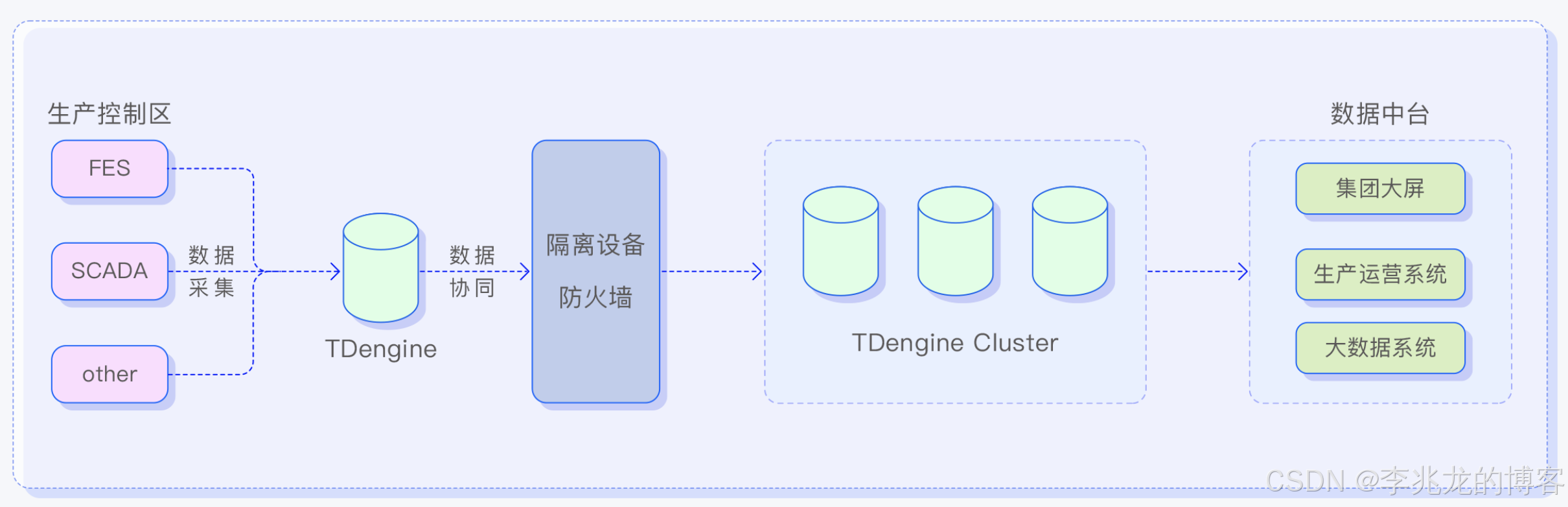
集群级别边云协同:
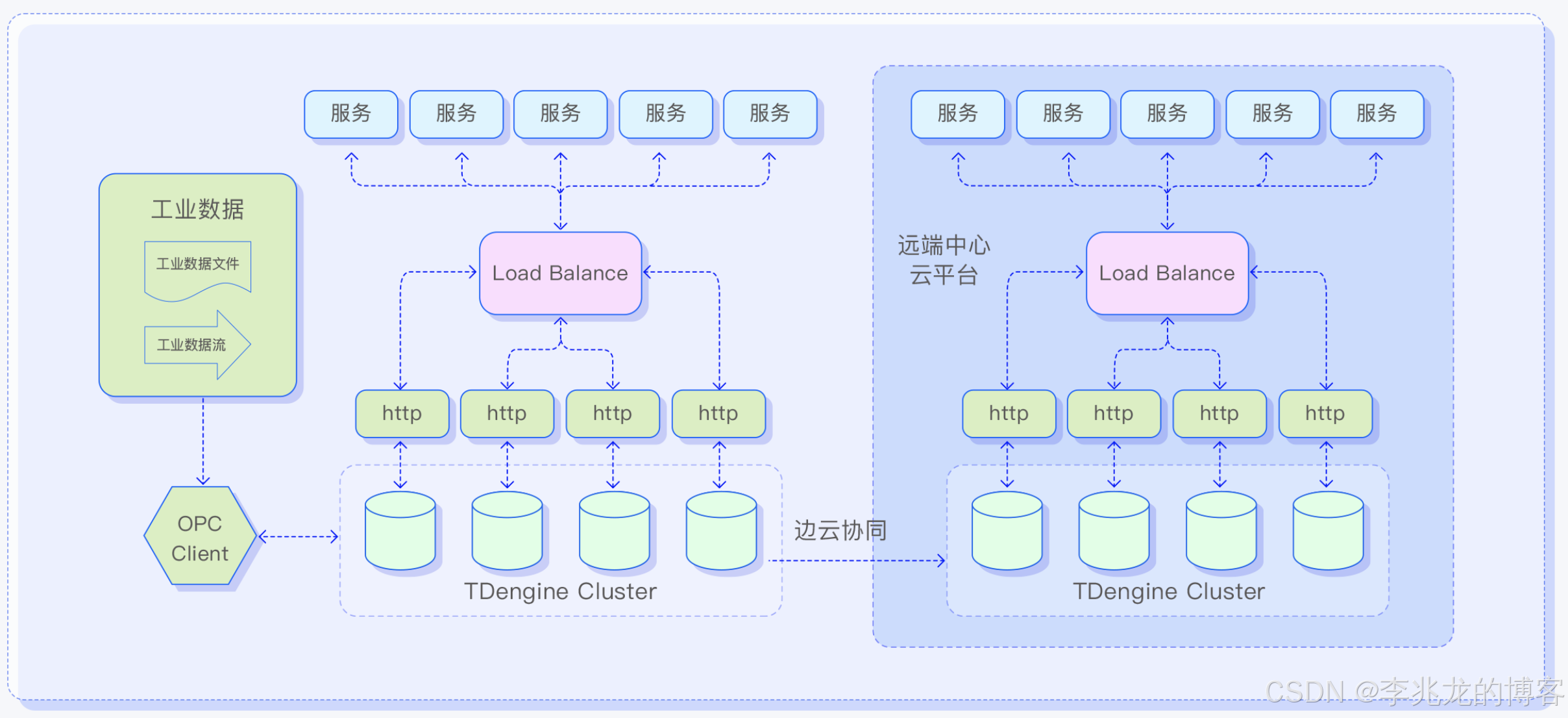
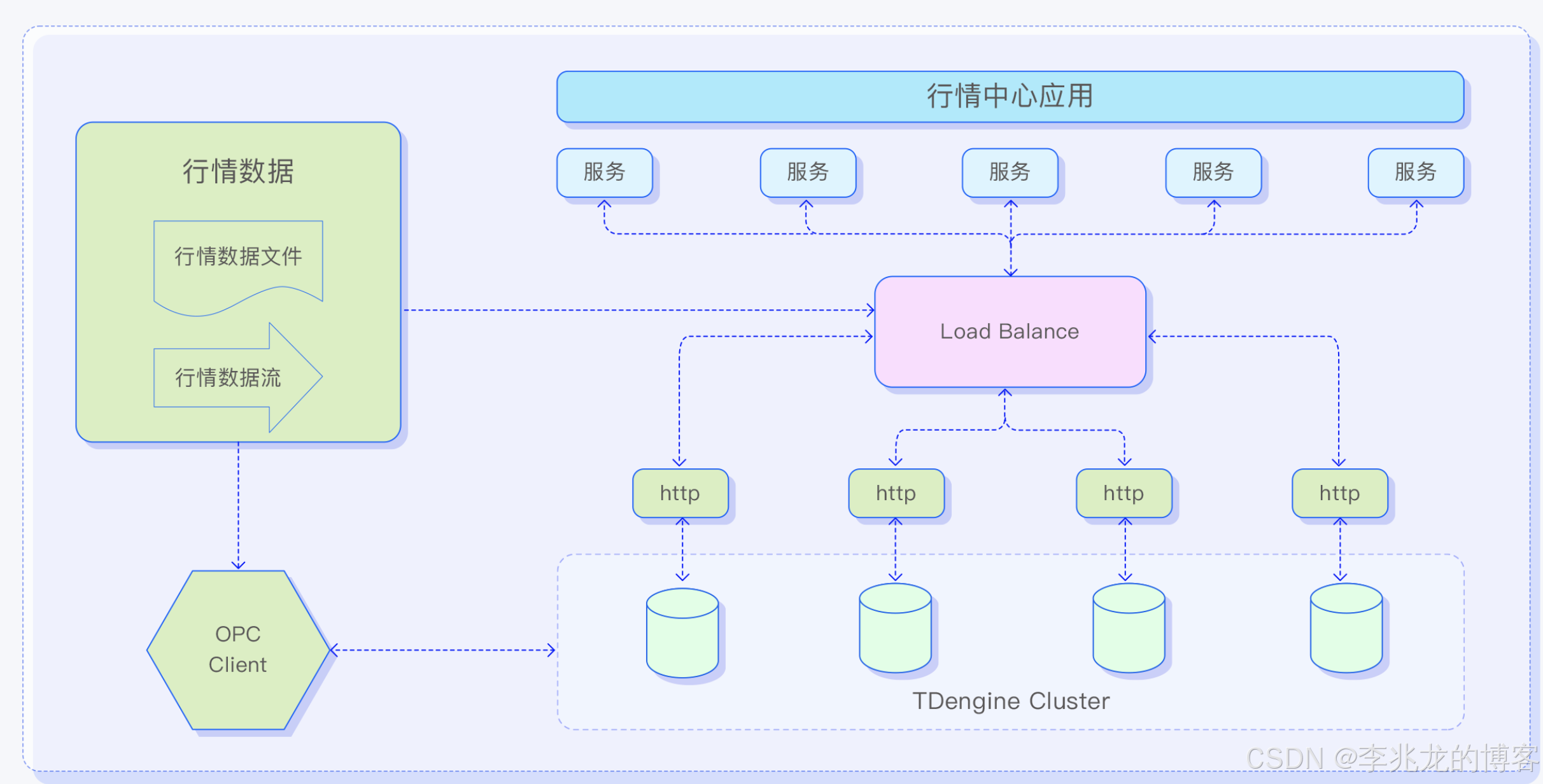
单集群独立部署:
GreptimeDB
Tison大师目前所在的公司。
GrepTimeDB的愿景其实非常贴近解决现实问题,系统的多引擎,基于对象存储+DataFusion的设计也非常优秀,就是新系统的稳定性是存疑的,这需要更好的营销来换取更长的存活时间,以打磨质量,就像前面提到的。
Greptime 边云一体解决方案本质上没有新东西,但是对于时序数据库来说不需要新东西,基础能力做到达标即可。

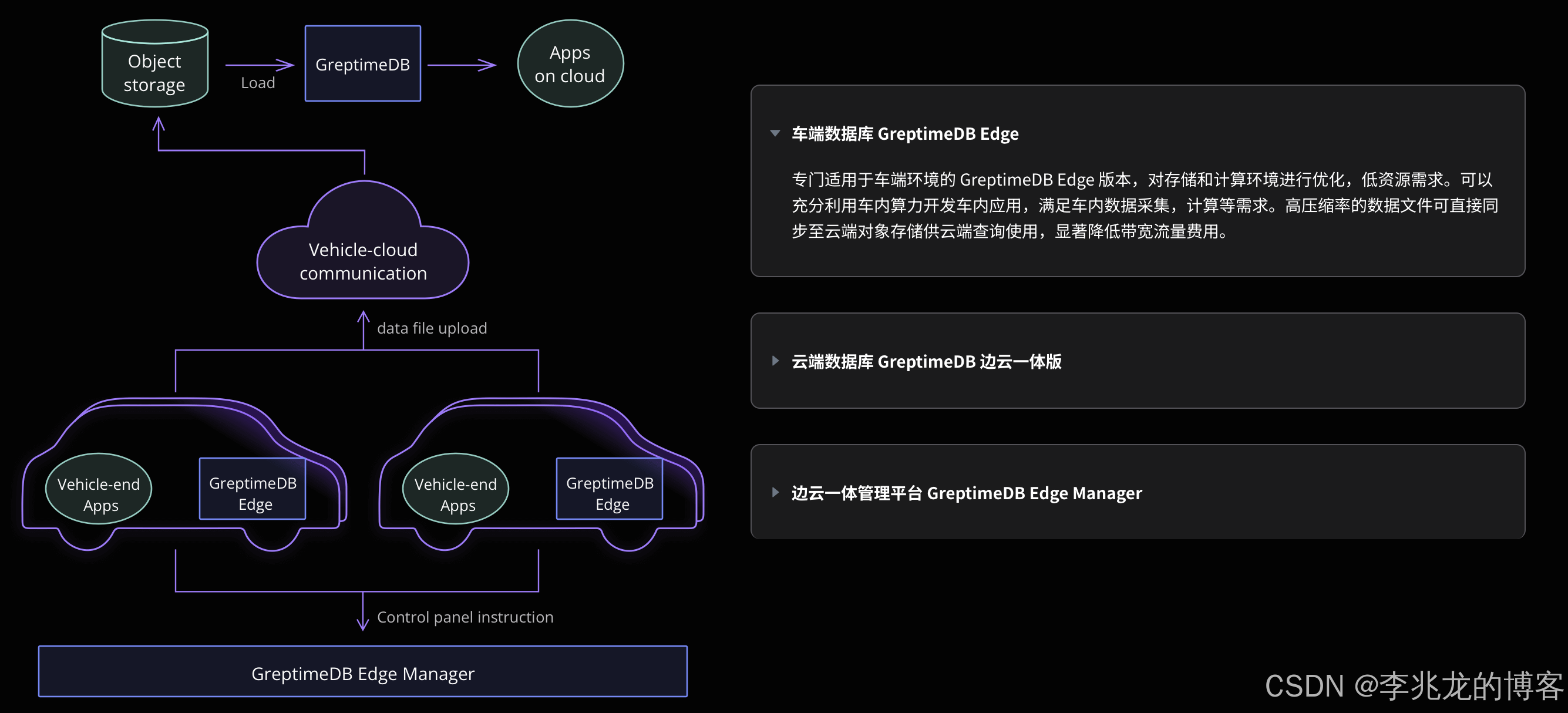
对于企业版增值功能也基本上是五脏俱全,但是还缺少业务场景上的分析类的增值功能。

总结
依托于大型公有云厂商,我们得天独厚的优势是:
- 大量便宜的高密物理机型
- 成本价的对象存储使用权
- 超低折扣的CVM
- 流程规范的软件工程实践(变更,运维,数据安全保障)
- 没有技术护城河的市场
- 大概率不会跑路
引用:
- 从一到无穷大 #29 ByteGraph的计算,内存,存储三级分离方案是否可以通用化为多模数据库
- The new and improved sql: 2016 standard
- Duckpgq: Efficient property graph queries in an analytical rdbms
- 一文读懂:什么是数据仓库
- 从一到无穷大 #30 从阿里云盘古的屠龙之术看使用blob storage作为统一存储层的优势
- TDengine 官网
- greptime官网
- What Goes Around Comes Around… And Around… sigmod2024