 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
引言
由组内大佬爽哥推荐的论文,sigmod2024的《TimeCloth: Fast Point-in-Time Database Recovery in The Cloud》阐述了一种在恢复表所在实例中基于PITR( Point-in-Time)的快速恢复方案。
先不讨论论文内容,但从这个功能来看存在哪些问题和哪些优化点。
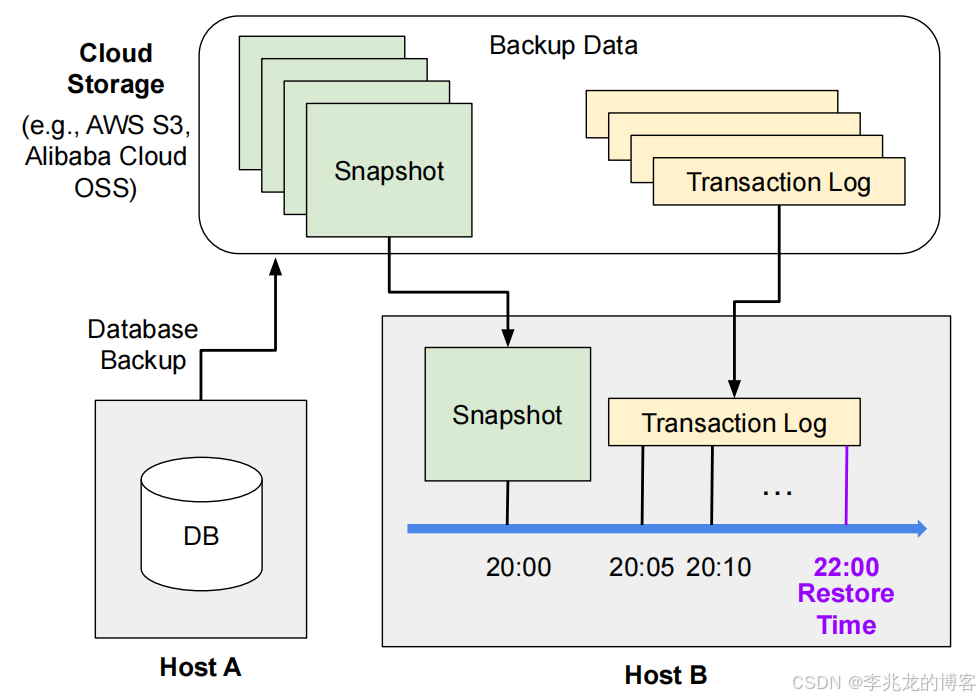
PITR一般我们也称之为流水备份,其基本思路非常清晰:
- 定期对数据库做全量冷备,并记录冷备的最后一个LSN。(一周三份,两周五份,一个月七份等冷备策略,值得一提的是冷备是对每个分片去做的,所以全局来看不能做到备份到某个时间点)
- 保存数据的WAL(写,删,修改,元数据操作),每条WAL记录LSN和混合时间时钟
- 冷备和流水备份上传对象存储
- 恢复时指定实例,先导入恢复时间前的一个冷备,然后再恢复冷备中每个分片最后一个LSN到指定时间的LSN
事实上这个过程有这么几个优化点:
- 恢复的表不是用户的表,用户要通过Join从新恢复的表去修正原始表,其实我认为有办法做到用户无感知直接恢复源表数据
- 针对表级别数据恢复(用户误操作),单分片中可能存在不同Collection的数据,Collection级别的恢复会扫描无用的数据,可以在流水备份文件中添加摘要信息,扫描的时候可以规避掉部分不需要的数据;
- 针对于实例级别的数据恢复(灰色错误导致数据损坏。之前遇到一例在写入存储引擎前内存跳变导致写坏一个字节,存储引擎的CRC已经算错了,最后是用户发现的错误,这种错误不做全局CRC是无法避免的;两副本硬盘损坏;),目前的导入过程是分片并发的,但是每个分片内部是重放全量的WAL,这个过程显然基于不同的数据模型有更快的恢复方案,比如合并部分修改结果,只保留最终结果;并行导入单分片中没有依赖关系的数据项,单分片也可以做到并发;
好了,回到论文的内容。
计算机工程领域,提出问题其实在很多情况下比其解决的过程更为重要,我们来看看本篇文章抽象出来的问题是什么。
论文提到 1w 个数据库实例中就有大约 700 次由用户发起的恢复。在这种由用户触发的恢复中,客户有两个基本需求:
- 希望将受影响的表回滚到某个历史时间点的一致状态
- 保持原始数据库实例正常运行,以满足写入查询
在这个过程中观察到客户经常对恢复的表进行频繁读取(如 SELECT 和 JOIN),以纠正原始表数据。在服务受到严重影响或纠正过程耗时过长的情况下,客户会优先考虑服务可用性,完全切换到已恢复的表( RENAME)。因此,论文确定了云中高效用户触发恢复的两个理想目标:
- Recovered data in situ:恢复后的后续用户操作通常涉及对恢复表的频繁读写。如果恢复的表位于当前实例之外的其他地方,则所有表访问都会因跨实例或跨节点通信而产生额外开销。因此,恢复表应位于同一数据库实例下,以实现良好的查询性能。
- Lower recovery time objective (RTO):在恢复期间,原始表和数据库实例都是实时的,因为可能会有新的事务到达。因此,较高的 RTO 可能会导致用户执行的恢复后数据校正任务量增加,从而提高操作复杂性。所以较低的 RTO 可以大大减少和简化恢复后的用户工作量。
所以可以看到,论文其实就是要在恢复表所在实例比传统方案更快速的恢复数据。
解决方案
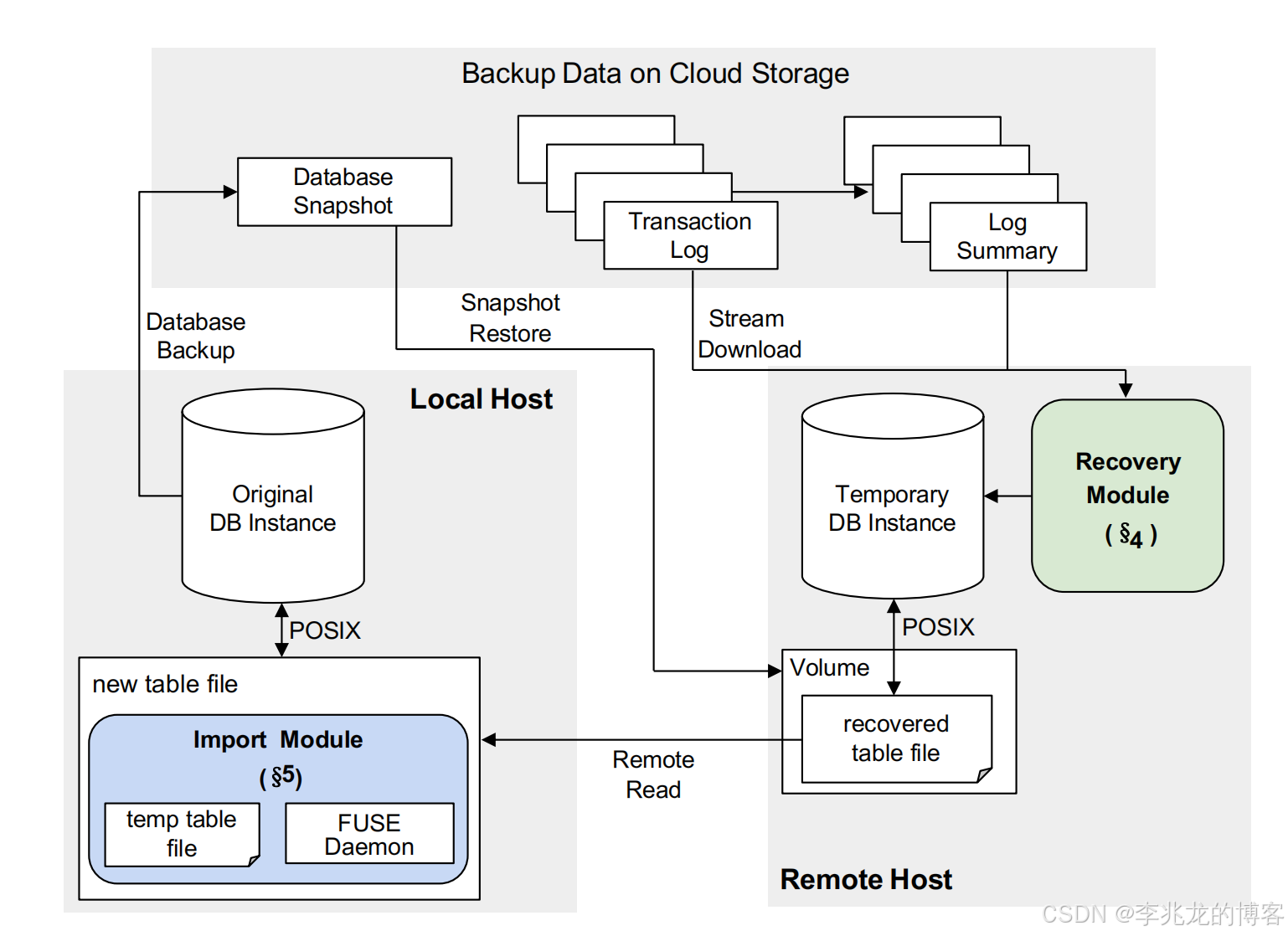
TimeCloth的解决方案分为两个方面:
- 在恢复实例外快速细粒度恢复数据
- 基于lazy loading的快速导入
FAST FINE-GRAINED PITR
Log Filter
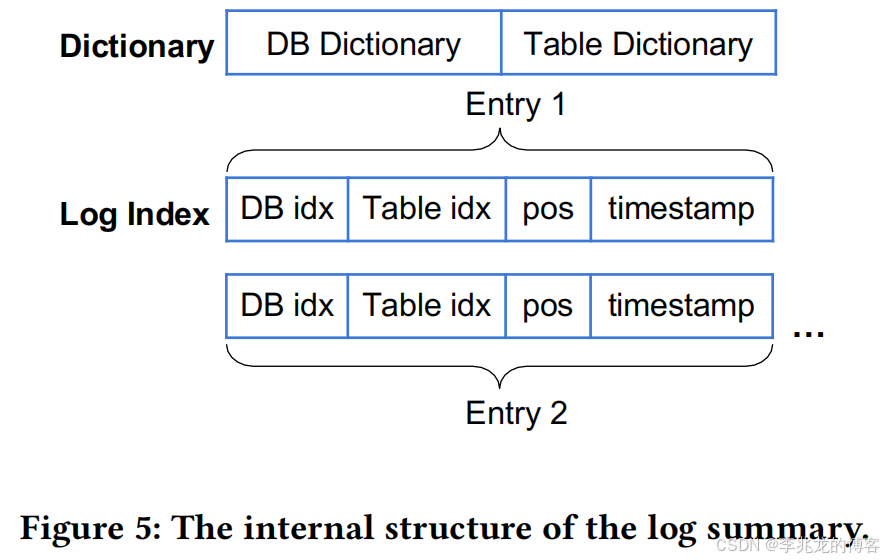
使用 Dictionary 将表名和数据库字典化为较短的字符,日志索引中的每个 entry 对应于原始事务日志中的一条日志。包含四项:
- 数据库名对应字典值
- 表名对应字典值
- 日志中的位置
- 时间戳
在恢复过程中,基于摘要可以快速识别相关日志记录。当然一般整个WAL文件还是要从对象存储拉下来的,一般这是一个对象。
Inter-Record Dependency Resolution
介绍了一种检测依赖关系的轻量级算法,可以识别出不同主键之间的依赖关系,判断哪些数据可以并行恢复。
总体思路不难,有兴趣的可以看看原文。
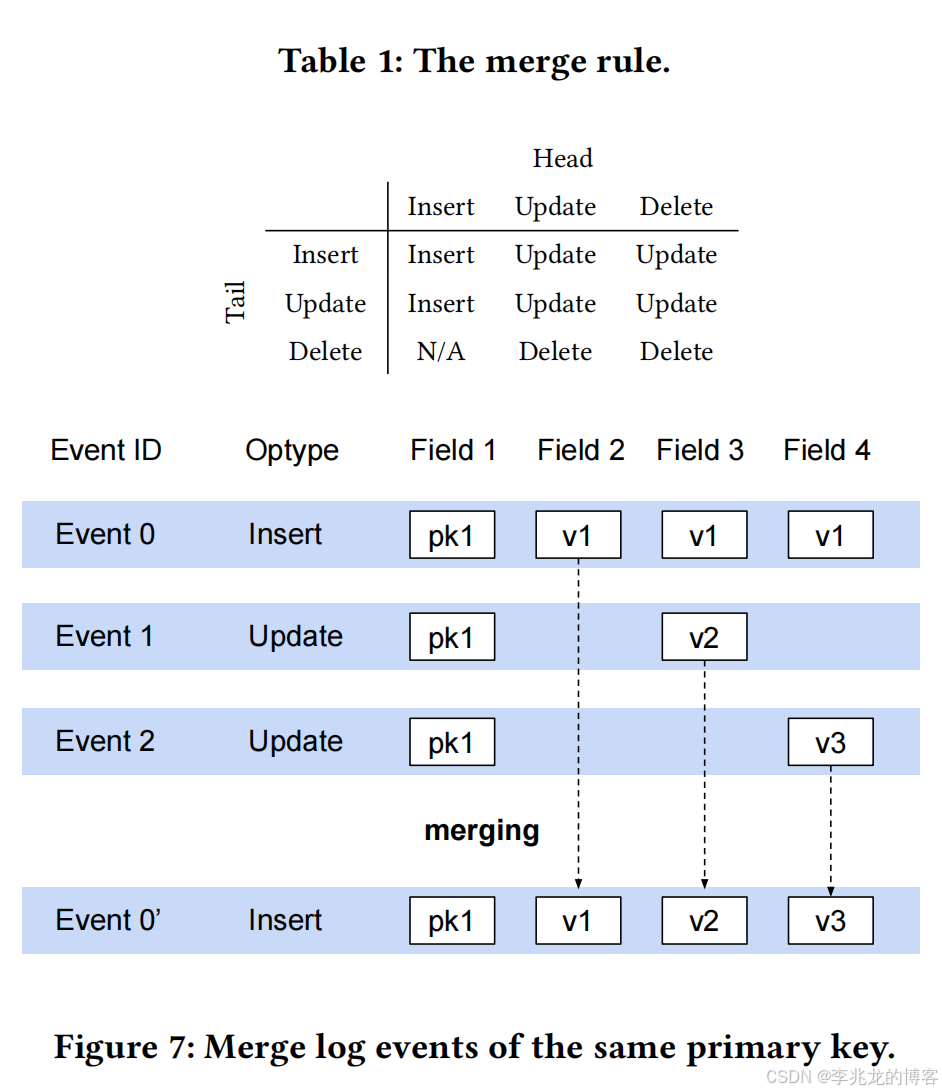
Log Merger
对于每一批不冲突的日志事件,可以通过合并主键相同的日志事件来进一步加快日志重放速度。原因是恢复方案只关注最终状态,因此只要不违反记录间的依赖关系,我们就可以安全地跳过中间状态,合并对同一行的操作。
基本规则如下图所示:
FAST IMPORT OF REMOTE TABLES
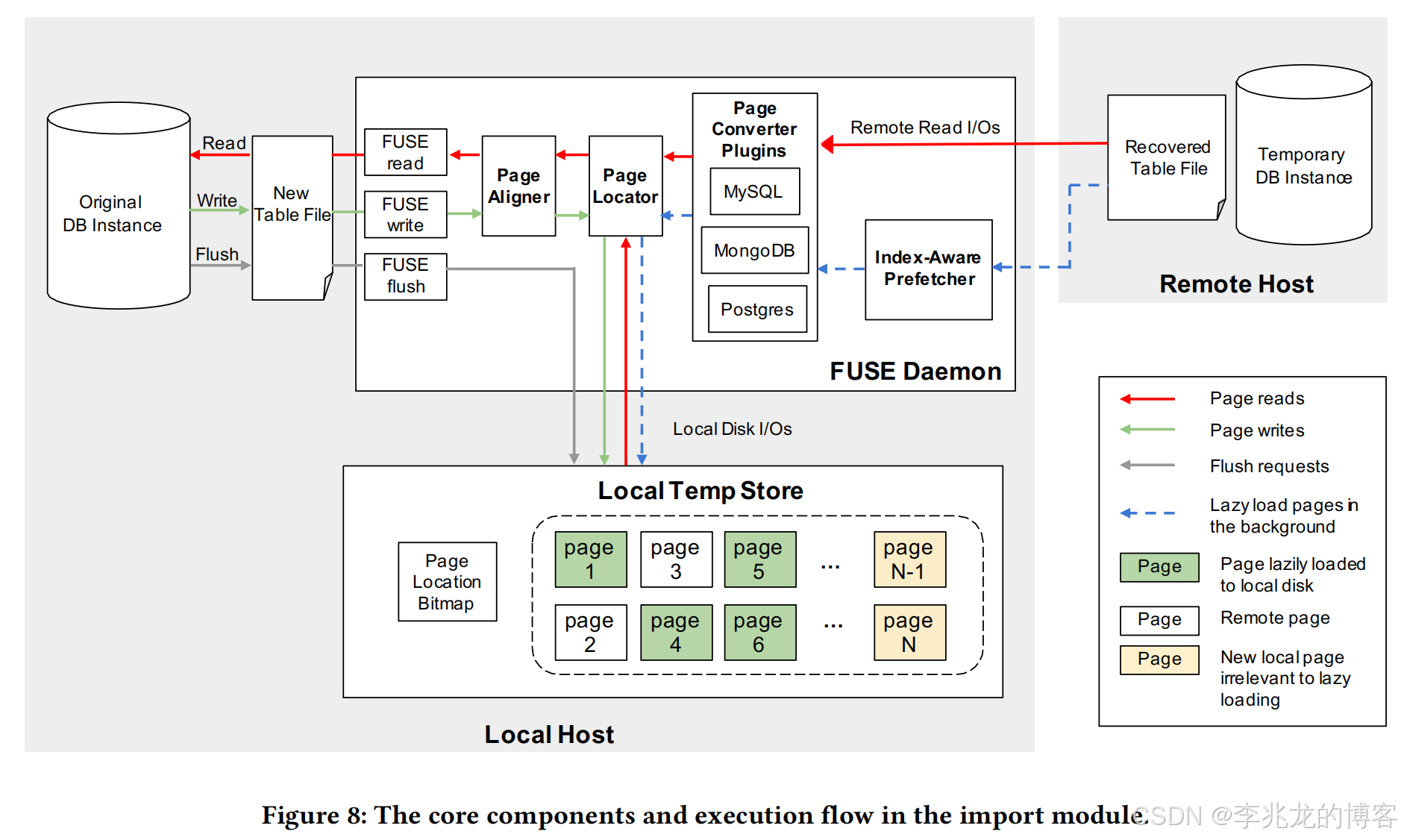
基本思路认为物理导入速度太慢,在完全导入实例前用户无法使用恢复表,所以使用 Lazy Loading。
步骤如下:
- 在一台远程主机上基于上一节提到的快速恢复方案恢复一个数据库实例
- 待恢复实例中创建一个 New Table file,此时用户可以认为恢复任务完成,但是实际数据还是在远程
- 创建一个临时表,使用FUSE文件系统接口,对上层数据库保持透明,拦截用户对于 New Table file的读取,先从本地检索是否存在,如果不存在则读取远程实例,并实时填充临时表
- 后台预取远程实例的页面
- 一旦复制了全部的页面,则用临时表替换New Table file
- 远程读取,表交换对用户来说的都是透明的
总结
在不同的数据模型下PITR拥有不同的目标,在这个基础上有不同的预期,从而诞生不同的解决方案;
话说回来都是锦上添花,不过这也是软实力的体现,要是团队都快养不起了自然都是扑杀在前线业务的功能和性能上,只有运营稳定,营收稳定且愿意投入才能有这样的收获。
不过基于hook的方式真的是很多小创新的高发地域,以下提到的东西我都至少见过一篇论文或者一篇专利23333:
- 用户函数的hook
- 文件系统的hook
- 用户态系统调用的hook
- ebpf的函数级别hook
- …