 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
由华为云数据库创新实验室在sigmod2024发表的《ESTELLE: An Efficient and Cost-effective Cloud Log Engine》阐述了一种针对于日志存储中前缀查询,AND查询和直方图查询特殊优化索引结构的日志存储引擎。
其需要面对的挑战如下:
- Heavy and Skewed Log Writes:日志总量大,且一天的写入可能集中在几个小时内。
- Low Frequency and Heavy Log Queries:绝大多数日志可能从未被查询过,其次在实际执行扫描大规模数据的查询中可接受的延迟也尤为重要。
- Various Log Queries and Important Log Aggregations:集中典型的日志场景查询需要支持,包括不限于:全文检索,多AND条件查询,前缀查询,高频词的直方图查询。
- Low-Cost Log Engine System:在可接受的查询时间范围内,使用较少资源对数据写入,存储,查询,其实核心点在索引结构的构造上,因为业界压缩算法基本透明,列存数据文件压缩比玩不出花来,但是用奇巧的索引结构来加速查询却是一个可以基于业务特征各显神通的地方。
文章有参考意义的贡献点其实我认为有两个:
- ESTELLE Log Bloom filter
- Approximate Inverted Index
就这两个结构来看可以认为是十分巧妙的微创新。除此之外其实在整体系统架构上没有比较新颖的地方,这样的架构基本上是业界通用,在分析领域,Influxdb IOX,Amazon Timestream,Apache Druid的架构基本和 ESTELLE 一模一样。不过这正说明了ESTELLE在架构上是优秀的。
因为这样的架构可以做到:
- 支持查询调度和分布式查询:性能高
- 读写节点分离:读写物理隔离,不互相影响
- 允许读读节点分离:在线读离线读分离,优先级分离
- 存算分离:成本低
其次因为SFS和OBS提供了高可用性,本身系统的实现也少了很多麻烦。
在[4]中我提到,Apache Arrow Datafusion,Apache Arrow Acero,Velox,Apache Calcite等项目推动了高性能基础架构领域组件化发展,这意味着开发一个世界顶级的OLAP系统的门槛下降了一个台阶,开发团队应该将更多的人力投入到增值功能上去;
其次因为SQL的对多种模态的统一[5],目前各个数据模型,系统间的核心差异化竞争应该集中在存储引擎针对于不同场景的索引定制化上,更彻底的就像[6]阿里云盘古这样从用户态内核栈,定制服务器,定制加速硬件入手了。
但是真正的重点是看清市场规模和投入比,很多事情并不是我有能力做我就要做,而是要看预期内有机会拿下的市场份额和人力投入。
时序数据库其实是个很好的市场。
从可观测领域来看,三大基石Metric,Logging,Traceing分别对应三种不同的时序存储引擎形态,其他所有模块共享:
- Metric:全量倒排索引 + KV列式存储
- Logging:轻量级倒排索引 + 行列混存
- Traceing[2]:行列混存
而从物联网,工业互联网等蓬勃发展的市场来看仍旧处于一片蓝海,充满机遇,而且也基本可以归结在上面所说的三种引擎形态中。
光Metric领域,目前看到的已经是时序模型压缩后20P以上的盘子了。
Architecture
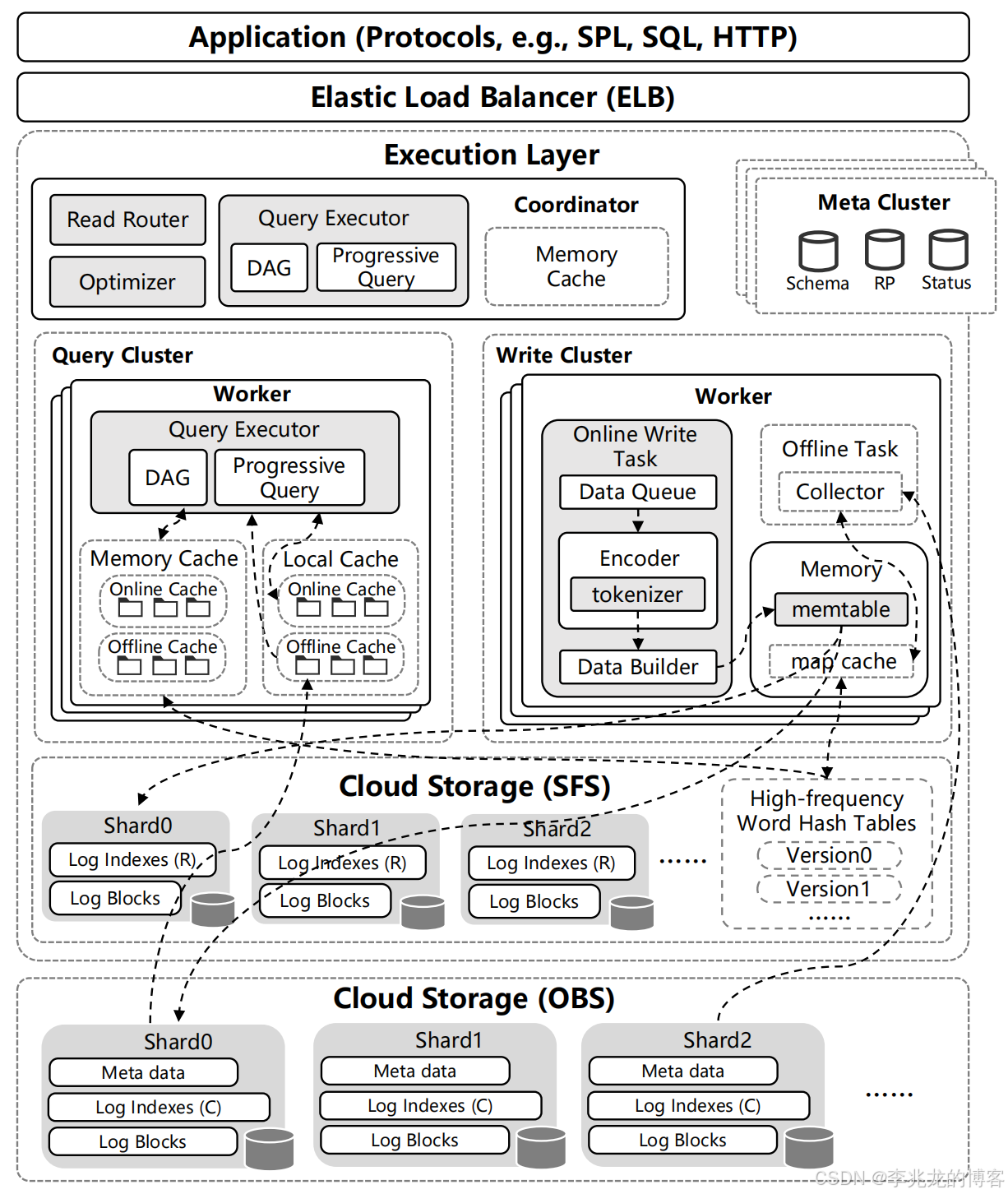
整体架构较为清晰:
- Meta Cluster:负责存储database schema, table schema, permissions information, Retention Policy
- Execution Layer:执行查询和写入操作,读写集群分离
- Object Storage Service:数据与索引的数据存储
- Scalable File Service:当写入状态节点内存中的日志数据量尚未达到一个块的量,但收到用户的刷新命令或超过 30 秒没有写入日志条目时,这些日志数据就会被临时写入 SFS。这避免了频繁刷新到 OBS 所带来的性能损失。SFS 还用于存储高频字哈希表。
LOG INDEX FRAMEWORK
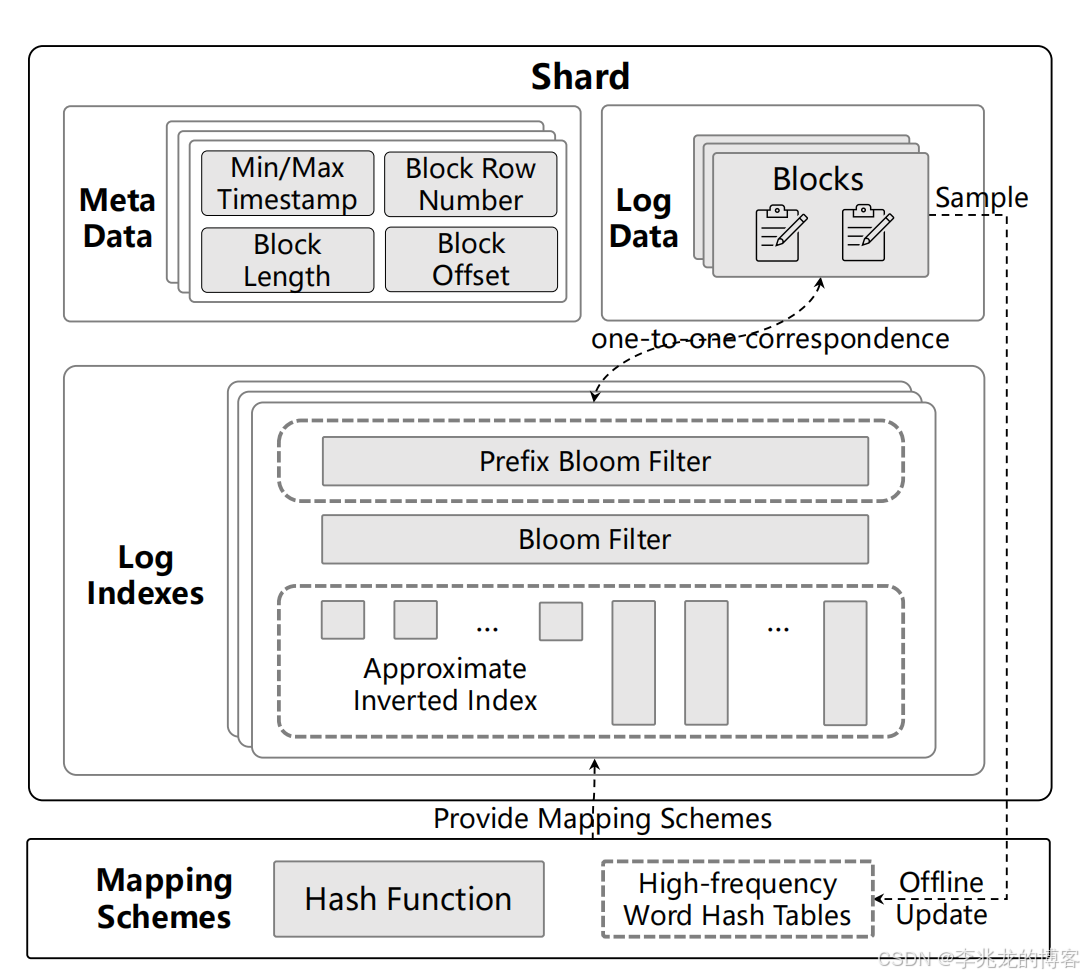
上图展示了一个独立时间范围,分片内存储引擎的内部数据分布,索引数据主要包含如下:
- Meta Data:包含 Min/Max Timestamps,Block Lengthes and Block Offsets,Block Row Numbers;这里的优化[7]和Parquet的摘要信息+Page index+Offset Index比较像,只不过Parquet的摘要是min/max/count等聚合算子的摘要
- ESTELLE Log Bloom filter(EL-BF):相对于普通布隆过滤器的优势是只需要一次IO操作就可以获取到多个page中一个word是否存在的所有信息,用于一次跳过多个不相关的page。
- Prefix Bloom filter:本质是一个专门用于存储词前缀的 EL-BF。这种方法不仅能保持日志写入的效率,还能通过控制前缀布隆过滤器的大小和设置写入该过滤器的前缀长度上限,在成本和效率之间进行权衡。
- Approximate Inverted Index:用于优化高频词的直方图查询和低频词的AND条件查询。
ESTELLE Log Bloom filter
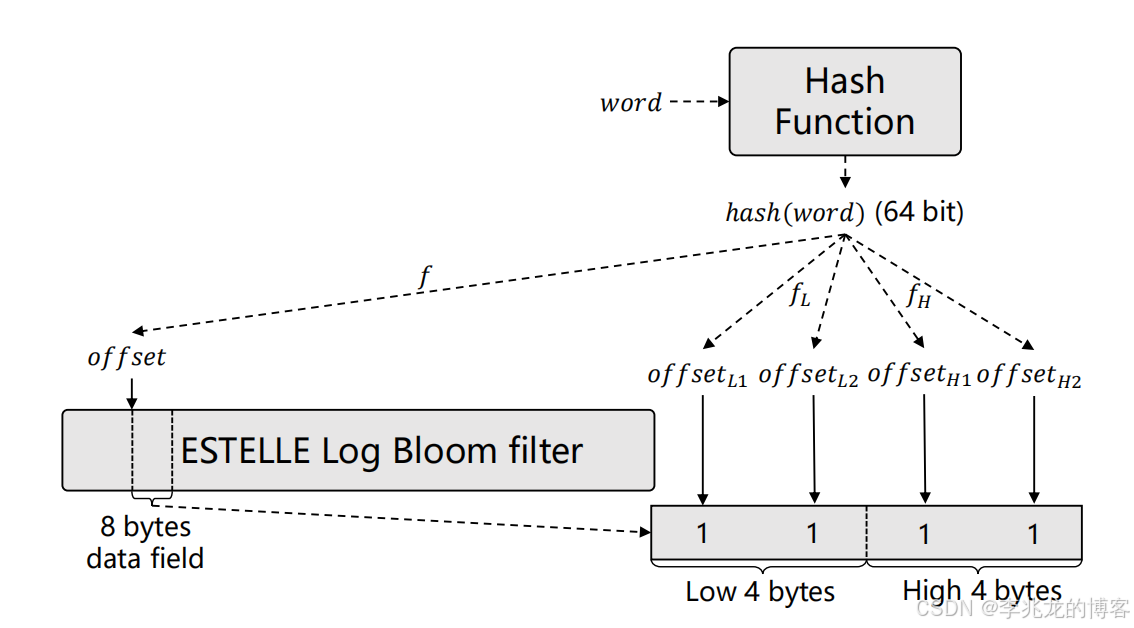
上图展示了 EL-BF 的算法工作流程,基本流程描述如下:
- 使用MurmurHash3把word转换为ℎ𝑎𝑠ℎ(𝑤𝑜𝑟𝑑)
- function 𝑓 used extract the first 𝑥 bits of ℎ𝑎𝑠ℎ(𝑤𝑜𝑟𝑑) as an 𝑜𝑓𝑓𝑠𝑒𝑡 on EL-BF
- 从 𝑜𝑓𝑓𝑠 𝑒𝑡 开始,通过检索 EL-BF 中下一个 8 字节,就能得到一个 8 字节的数据字段。随后,所有与 𝑤𝑜𝑟𝑑 相关的操作都将在该数据字段上进行,并将其标记为 𝑓𝑑
- 𝑓𝐻 用于提取 𝑤𝑜𝑟𝑑 的 𝑥 + 1 至 𝑥 + 9 位,并根据这些位通过indexing pre-set array 获得两个偏移量,即 𝑜𝑓𝑓𝑠𝑒𝑡𝐻1 和 𝑜𝑓𝑓𝑠𝑒𝑡𝐻2
- 𝑓𝐿 用于提取 𝑤𝑜𝑟𝑑 的 𝑥 + 10 至 𝑥 + 18 位,并根据这些位通过indexing pre-set array 获得两个偏移量,即 𝑜𝑓𝑓𝑠𝑒𝑡𝐿1 和 𝑜𝑓𝑓𝑠𝑒𝑡𝐿2
- 将 𝑤𝑜𝑟𝑑 加入 EL-BF 时,如果四个offset相对应的位被置 1,则认为包含
其序列化的过程也很有趣:
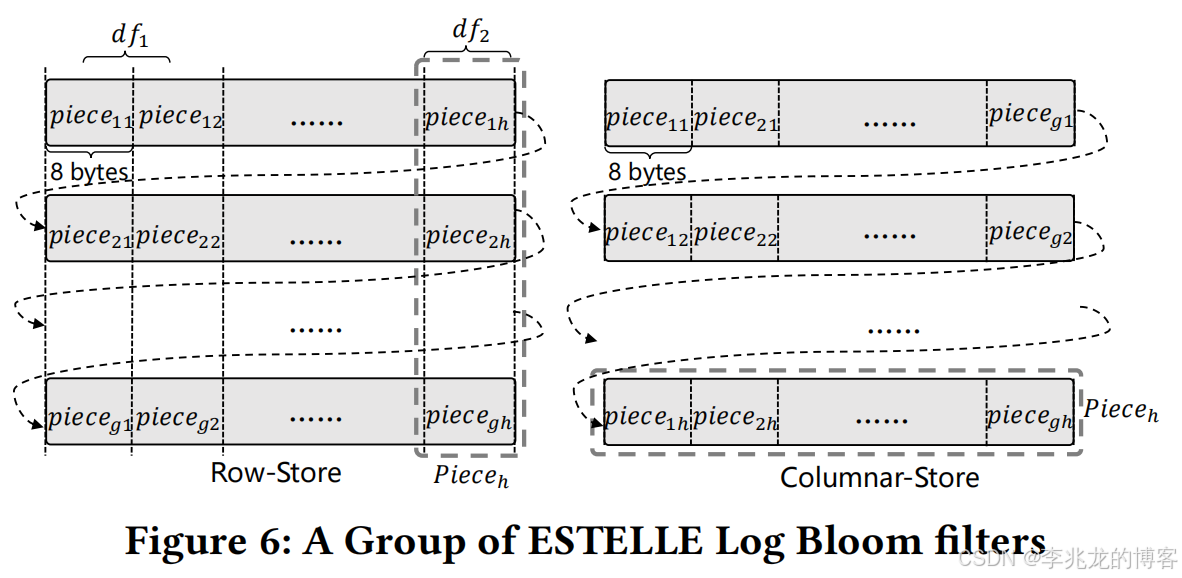
可以看到在ESTELLE中多个布隆过滤器被存储在一个page中,且block之间是列存。因为ESTELLE Log Bloom filter的算法确保了一个word的判断标准在一个八字节内,多个page同时检查是否存在某个word只需要一次顺序IO操作。不得不说还是非常巧妙的。是一个可以被参考的优秀思路。
Approximate Inverted Index
Approximate Inverted Index 用于优化高频词的直方图查询和低频词的AND条件查询,这两个场景分别存在以下挑战:
- 高频词的直方图查询通常会带来巨大的 I/O 开销和查询延迟:在大多数情况下用户通常感兴趣的是近似的汇总结果,而不是极其精确的数值。因此,ESTELLE 日志引擎将直方图查询设计为渐进模式。收到直方图查询请求后,日志引擎会快速返回一个近似的直方图结果,用户可以选择在此时停止查询,从而减少扫描量并节约成本。对于需要极其精确的直方图查询结果的情况,如生成统计报告,日志引擎在向用户返回近似直方图结果后,会通过多轮迭代精炼结果,以提供精确值。然而,要实现渐进式近似直方图查询,快速返回相当精确的近似结果至关重要。
- 对于低频词的 AND 查询,往往会出现大量误报:在只包含一个 EL-BF 的基本索引集中,如果两个低频词同时出现在一个数据块中,但不在同一日志数据行中,那么该数据块仍会被加载到内存中进行扫描,从而带来明显的扫描延迟。不过,在日志写入过程中,将低频词在块中出现的行号记录在倒排索引中,可以在 AND 查询时快速交叉相应的反转列表。这样就能快速确定块中是否存在同时包含这两个词的日志数据行。此外,它还能快速返回块内满足 AND 查询条件的数据行的行号,从而避免了部分逐行扫描过程。但直接为每个数据块创建反转索引会导致索引大小与数据块大小相当。这不仅会增加索引的存储成本,还会在查询过程中带来巨大的 I/O 开销。
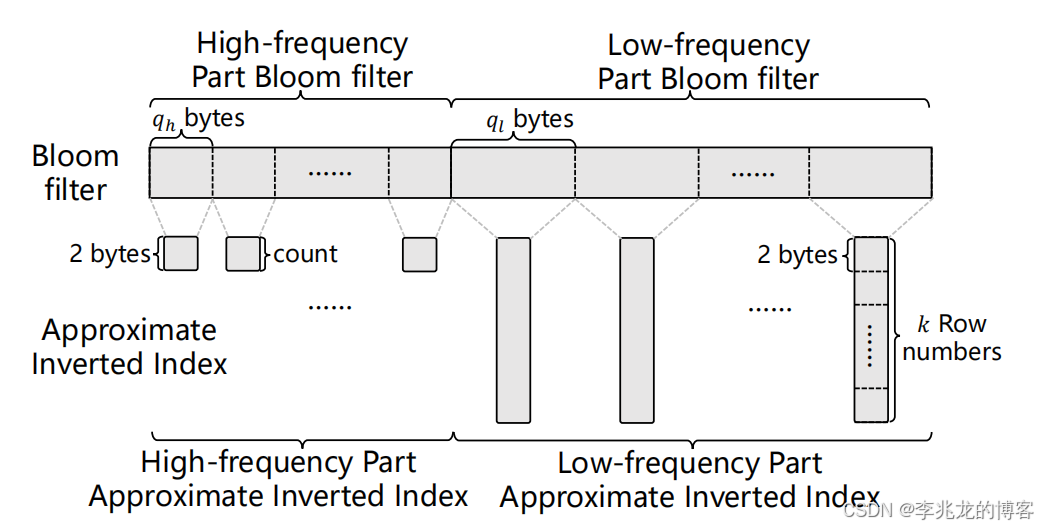
Approximate Inverted Index结构如上图所示,文中又叫Frequency Division Bloom filter,可以说非常形象了。
实际是由两个 EL-BF 连起来的,高频部分小于低频部分:
- 高频部分:每qh个字节对应一个近似倒排列表。每个列表只存储一个 2 字节的计数值,表示有多少哈希值被映射到该近似反向列表中。
- 低频部分:每 ql 个字节对应一个approximate inverted list。每个列表存储固定长度的行号。每个行号由 2 字节组成,记录了word对应的row在page中的那一行。
确实也是比较巧妙的利用了布隆过滤器的优势,即没有使得倒排索引大幅膨胀,又相对增加了查询的性能,这个思路也可以用在其他地方。
结束语
日志存储具有明显的时间特质,以时序数据库目前的架构来看完全可以在添加一个日志引擎的情况下支持高效日志存储,查询,借助于各种类似于本文各种特化的索引和业界成熟的计算组件服务,可以很轻松的达到加入这个市场的能力。
参考:
- 《ESTELLE: An Efficient and Cost-effective Cloud Log Engine》 sigmod2024
- Tracing with InfluxDB IOx
- Acero: A C++ streaming execution engine
- 从一到无穷大 #25 DataFusion:可嵌入,可扩展的模块化工业级计算引擎实现
- 从一到无穷大 #31 Stand on the shoulders of those who came before and not on their toes,从DBMS演化看时序数据库市场发展方向
- 从一到无穷大 #30 从阿里云盘古的屠龙之术看使用blob storage作为统一存储层的优势
- Parquet Page index