 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
从Lindorm的发展上我们可以看到其在技术架构上明确的构想。
即单模型独立提供基础服务,多模型间数据互联(南北互联),对外提供导入导出服务(东西互联),AI赋能 。宽表作为Lindorm的基本盘,把这些核心理念发挥到了淋漓尽致。
索引
Lindorm宽表支持四种索引:列存索引,全文索引,向量索引,二级索引
列存索引
列存索引核心思路为对每个行存的SSTable生成一个Parquet文件。
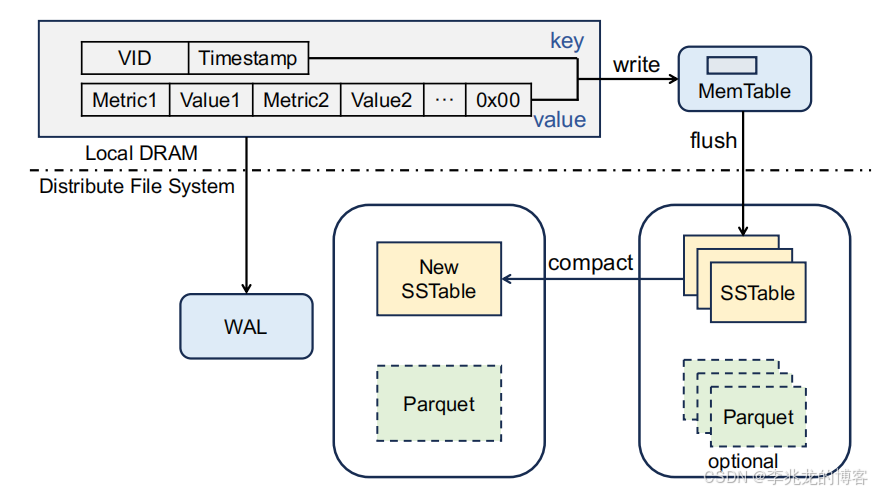
目的有两个:
- 减少从一小部分列中读取数据时的读取放大,用户可以为指标较少的查询指定为访问列索引文件,首先会根据该查询的车辆 ID 和时间范围过滤
SSTables,然后使用对应的Parquet文件检索目标列,因为行存中全部列的Value是拼接在一个MergeValue中的,所以少量指标读取Parquet做I/O 操作更少。 - 增强宽表中分析计算能力,不仅节省IO,列存中往往包含摘要,查询时间范围较长时有显著性能提升
全文索引
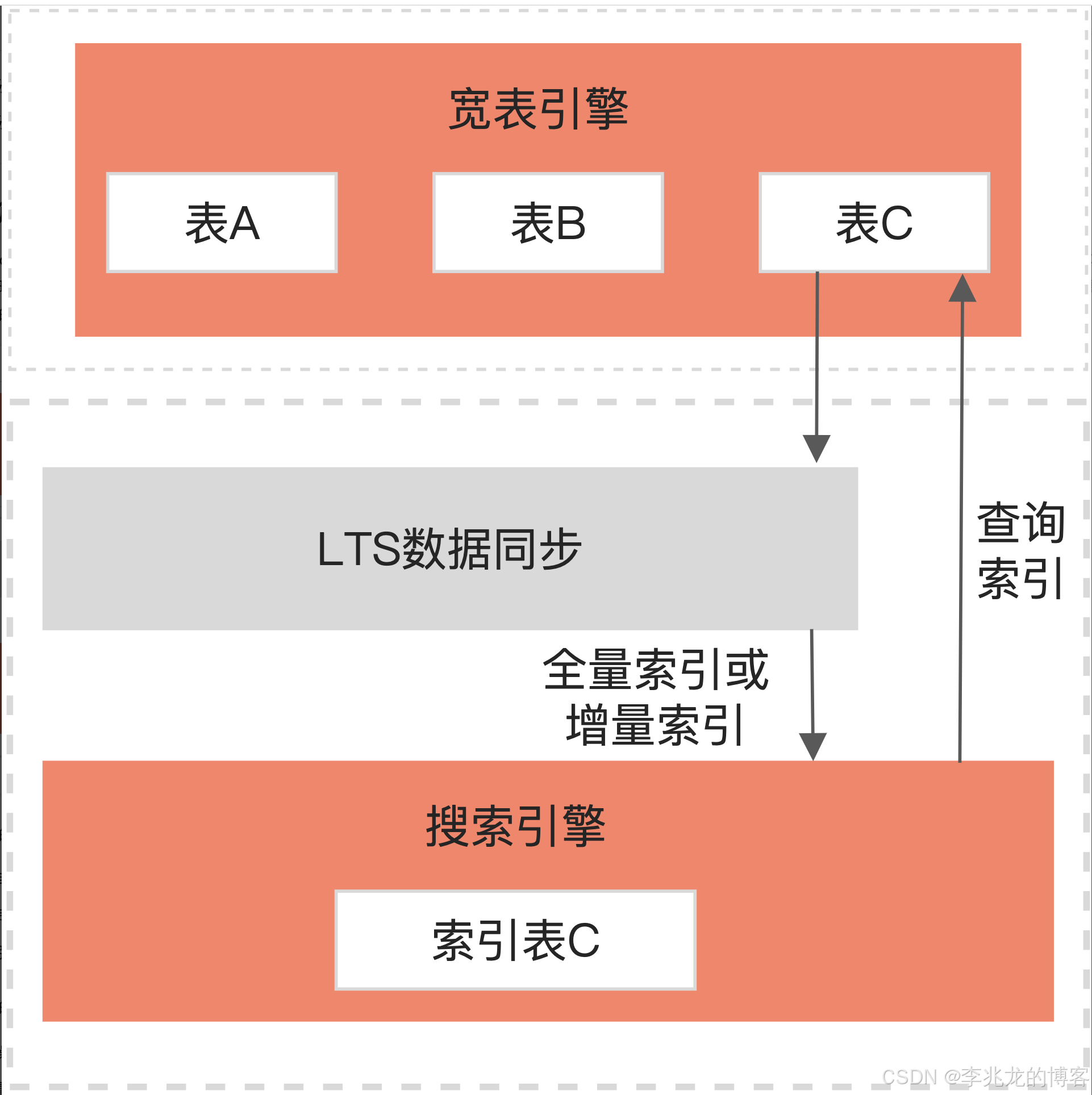
全文检索在Lindorm上发挥了多模的价值点,主要面向复杂的多维查询场景,能够覆盖分词、模糊查询、聚合分析、排序翻页等场景。
技术上不难理解,搜索引擎上和时序一样都支持全量的倒排索引(时间线爆炸时一般是稀疏的),对于二级索引无法完成的复杂检索可以轻松支持,而这一切不需要额外开发,只需要通过LTS服务将索引指定列写入到搜索引擎就可以了,架构大幅简化。
向量索引
目前Lindorm的向量索引是基于Tair做的,但是在2024下半年开始Lindorm已经在公有云上线了向量引擎,这其实也宽表的向量存储是一定要在内部闭环的,
二级索引
这里直接把官网的介绍拿过来:
Lindorm二级索引支持为单表建多个索引,每个索引在物理上映射为一张数据表,与主表相互独立,每个索引有不同的存储策略(如采用不同的压缩算法、冷热分离策略)等属性。写主表时,Lindorm会自动更新所有索引表,并确保主表和索引表数据的一致性。读数据时,您只需针对主表发起查询,Lindorm会根据WHERE条件和SCHEMA自动选择合适的索引(包括主表)执行查询操作(支持HINT来干预优化器行为)。
基本特性如下:
- 支持单个主表建多个索引。
- 支持组合索引(单列和多列)。
- 支持冗余索引,全冗余索引可自动冗余主表新增的列。
- 查询优化:根据WHERE语句自动选择索引,支持HINT来干预优化器的选择。
- Online Schema Change:索引变更不影响主表的正常读写,可以随时新增、删除、更新索引。
- 支持数据有效期(简称:TTL):索引表自动继承主表的TTL设置,主表和索引表数据同时过期。
- 支持动态列:支持写入动态列和冗余动态列。
- 支持自定义数据版本:自定义时间戳后自动写入数据。
冗余索引支持多种能力:
- 冗余指定的列:显式指定要冗余主表的哪些列。
- 冗余主表Schema中的所有列:当需要全冗余索引时,不需要在CREATE INDEX中将主表的每一列都显式添加进来,而是通过一个常量来描述冗余所有列,当主表新增列时,全冗余索引表会自动冗余这个新增列,无需重建索引。也无需担心新增列的查询会导致回查主表了。
- 冗余动态列:Lindorm支持固定Schema和SchemaLess。通过DYNAMIC冗余模式,索引表能够自动冗余主表中的所有动态列,也会冗余主表Schema中的所有列。
AI赋能
Lindorm目前的AI引擎只服务于时序和宽表。
时序
对于时序 Lindorm 聚焦于Time Series Forecasting与Anomaly Detection for Time Series,业界诸如IotDB也在时序内部用AI做Time Series Annotation。
AI引擎模型训练,推理路径如下:
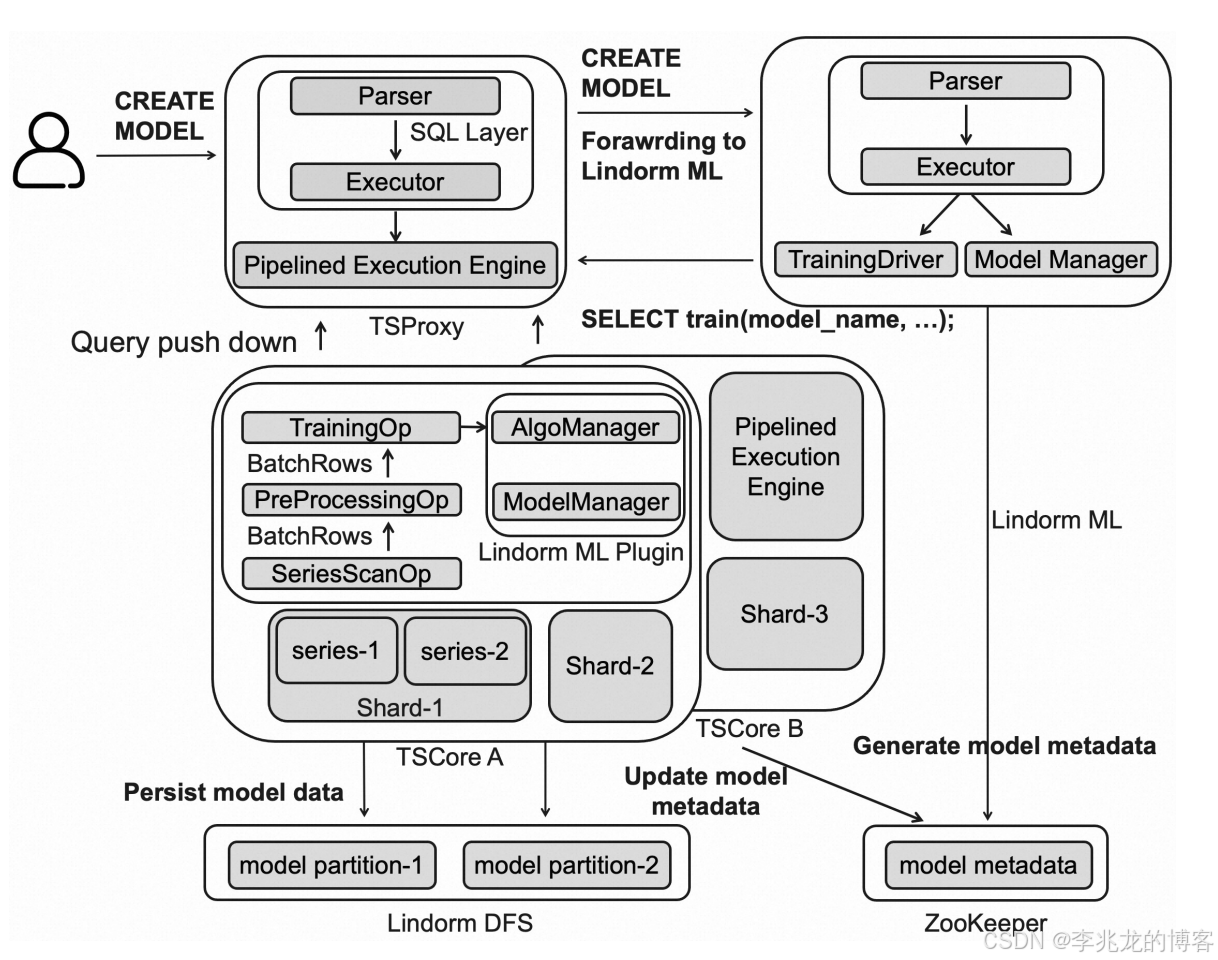
没有工程实现难点,核心步骤为:
Lindorm ML和TSDB节点通过底层的分布式文件系统和Zookeeper共享模型数据和元数据的管理。- 各种异常检测和时序预测算法由TSDB节点上的
Lindorm ML Plugin统一管理 - 利用 TSDB 数据的分布式存储和算子下推技术,
Lindorm ML可以实现批量、分布式并行和近实时数据训练优化
在进入训练运算符 TrainingOp 之前,流水线执行引擎分两步处理数据:
- SeriesScanOp: 运算符提取相关特征
- PreProcessingOp: 运算符执行必要的数据预处理。
宽表
Lindorm ML支持一站式模型导入,训练,推理,那支持这些功能就一点也不奇怪了。
| 特征提取 | FEATURE_EXTRACTION | 使用Embedding模型从数据(文本或图像等)中提取特征向量。 |
| 文生图 | TEXT_TO_IMAGE | 文本生成图像类AIGC任务。 |
| 语义检索 | SEMANTIC_RETRIEVAL | 在指定数据表中根据描述文本检索语义相似的文本。 |
| 基础问答 | QUESTION_ANSWERING | 使用大语言模型进行问答。 |
| 检索问答 | RETRIEVAL_QA | 使用指定数据表中的知识库结合大语言模型构建一个检索增强生成(Retrieval Augmented Generation,RAG)应用。 |
比如说支持RAG功能,一站式RAG能力业内标准做法是这样的:
- 构建行业知识库: 这部分表示从行业的相关文档中提取信息,然后将其组织成一个结构化的知识库。这一步骤通常包括文档预处理、信息抽取和知识表示等环节。
- 对输入进行预处理: 在这一步骤中,原始用户输入被转换为适合后续处理的形式。可能包括语言标准化、分词、去除停用词等操作。然后用经过处理的原始输入在已经构建的知识库中进行信息检索。
- 检索结果: 这是从行业知识库中检索出的相关片段及其相关性的列表。计算相关性,并根据定义好的权重获取片段。
- 检索片段输入: 经过检索后得到的相关片段会被整合进用户的原始输入中,形成一个新的Prompt。这个新的提示包含了来自知识库的上下文信息,有助于LLM更好地理解和生成响应。
- 通过大模型生成结果: 在这个阶段,经过预处理和增强的输入被传递给LLM,由其生成最终的输出结果。
这个过程至少涉及到:
- 模型上传
- 向量生成
- 向量存储
- 向量检索
- 多路召回,ReRanking
- LLM回答
在公开资料中我没有看到宽表是如何存储和检索向量数据的,虽然现在支持向量引擎,但是目前看AI能力的出现比向量引擎早多了。
LTS(Lindorm Tunnel Service)
我很喜欢这个名字,且认为一个强大的数据传输服务是多模数据库持续演进,发掘更多价值的核心模块。

目前看最新版本对外支持的功能有三个:
- HBase与Lindorm之间的全,增量数据同步
- MaxCompute/Hive -> Lindorm
- 数据订阅
- 备份恢复(猜测是流水备份)
- 主备容灾
阿里这里抽象做的确实很好,这些功能其实非常类似,即 pull/push 消费流,代码上是完全可以统一的。
官网中LTS的购买页也可以看到至少目前的向量检索和向量存储不是基于LTS做的。
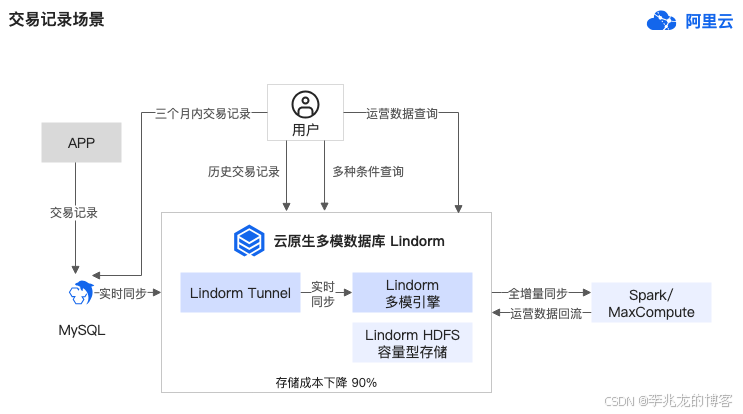
官网给了一个case,从Mysql中通过LTS将数据导入Lindorm,并允许外部系统订阅消费流。
总结
Lindorm各个模态的功能至少从介绍来看非常完善(宽表竟然还支持纠删码),而且大多数模态的思考和技术决策没有明显问题,基本上是属于把我能想到的事情都做了七七八八。
从[5]版本说明看,宽表19年,时序在21年已经在公有云服务,按照研发一年来算,至少18年就已经开始布局了。
对组织来讲可以认为是一个非常健康的王牌产品,这可以认为得益于长期的投入,阿里云稳定的基本盘带来的外部客户,和海量的内部业务的磨炼。
业务很重要,这可以解释为什么CosmosDB,Lindorm作为多模数据库(X-Stor其实做的也不错)领域领头羊但是支持的模态却基本完全不同。本质在于公司内部对应部门拥有哪些业务部门的支持,在2024年想拥有一种完全新的领域和业务线并不容易,尤其是我司这种6大BG都有基础架构组的情况,更多的是去吞并其他业务。
另外想聊聊近期比较火的数据智能话题,其实也就是数据库集成广义的AI能力,我的评价是虽然远不到“迈入数据智能新纪元”的地步,但是确实在小客户场景下有实际价值。想要有更多的故事长远来看需要改变对于普罗大众对于Pass的观念,定位更接近于Saas。
我司 Elasticsearch Service 做的就很好,因为并不是简单的做了RAG,而是对向量检索和全文检索做多路召回,显著的增强了查询的准确性,这对于人力不足的团队来说有很大实际价值,微信读书的AI问书功能就是很好的例子。
时序的异常检测和时序预测重要,但不是以目前的经验来看不是竞标的决定性因素。
至于在宽表上做检索问答和基础问答,我理解不是大客户的核心竞争力,因为人家可以自己做,而且使用公有云会考虑数据安全性问题,不会明文存储的。但是无疑对小客户是有吸引力的,当然是在基础性能,功能,成本达标的基础上。
所以清晰的知道团队处于那个阶段,清楚的知道追求的是营收还是人效比尤为重要,毕竟团队正收益才能持续发展,而且急躁也没用,复杂性是固有的,数据库内核开发,工作时间长效率低,工作时间短效率高,不会因为短时间发奋图强项目的进度总体就能往前赶多少,反而容易因为疲惫丧失好奇和创新,毕竟脑子和屁股,手一样重要。考虑运营提效,测试提效,考虑做事的核心价值,该冲就冲,该躺就躺,想到这里,倒也不觉得纠结了。
引用: