cas和vector clock 都是以时间戳,作为并行的检测手段,那么时间戳为什么可以表现出并行或因果时序呢?
在1978年的lamport论文Time Clocks and the Ordering of Events in a Distributed System就论述了时间戳的原理。
以下是我读完这篇论文的一些自己的理解(不是论文翻译),因为很喜欢物理,所以对这个问题也格外感兴趣。如果有不对的地方还请指正。在1967年召开的第13届国际度量衡大会对秒的定义:铯-133的原子基态的两个超精细能阶间跃迁对应辐射的9,192,631,770个周期的持续时间。这或许让人大跌眼睛,时间流逝居然是有物质变化定义的。这和我们所了解的绝对时间有很大的出入。
那么分布式的时间又是由什么事物的变化定义的?
就像薛定谔的猫一样,当我们观察猫的时候,猫的状态就确定了,可是当我们不去观察它的时候,它的生死却是不确定的,那么我们可以知道,先后(因果)关系,必须要观察才能得到。
而在分布式中,任何计算机上的事务都可能并行生,那么什么样的事件是可以观察并且用来确定两台计算机上事务的因果(先后)发生?
HAPPEN BEFORE的偏序关系
把happen before简写为“->” ,
那么:分布式系统上事件集合上有一个“->”关系,满足以下条件(以下条件可以推倒出先后关系):
(1)如果a和b是同一个进程中的事件,并且a在b前面发生,那么a->b。
(2)如果a代表某个进程的消息发送时间,b代表另一进程针对这同一个消息的接受时间,那么a->b。
(3)如果a->b且b->c,那么a->c。这个条件是有传递性的,但却没有自反性,这也是只能用时间戳偏序的原因。
我们再定义一个关系:如果不能确定a在b之前发生或b在a之前发生,那么我们说他们并行发生。即:a(!->)b且b(!->)a,a和b并行发生。
下面是lamport论文里的一张图:
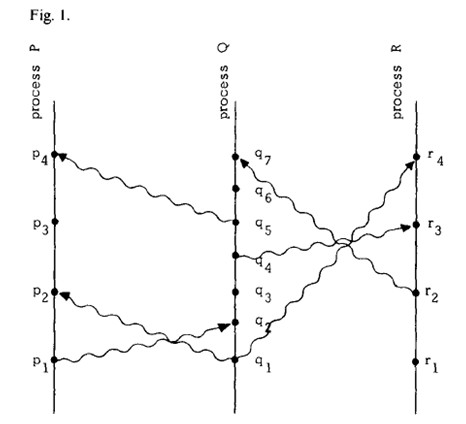
横轴代表了不同进程,纵轴代表了时间,点代表时间,垂直线就是进程,曲线就是消息。
从图上我们可以看出,a->b就意味着a导致了b的发生,也就是a和b之间有因果关系,如果没有因果关系,那么我们就认为他们并行发生。比如图中的p3和q3,虽然二者发生的物理时间上有先后,但是进程P在P4时候收到消息之前,根本不知道进程Q什么时候执行了q3,在p3时刻,P进程不知道p3发生与否,因为P进程没有观察到Q进程的当前情况。相对论中,时间的顺序可以通过被发送的消息定义(人眼看到的世界和光作为媒介传递的消息)。狭义相对论中存在因果关系的事件,他们的发生顺序在不同的观察者眼中是一样的,
我们先定义每个进程的每个事件有一个时间戳,本进程内如果时间a早于b发生,那么C(a)>C(b)
我们定义一种顺序(因果关系):如果事件a发生在b之前,那么a发生的时间应该早于b。形式话表达:任意事件a,b:如果确定a->b,那么C(a)<C(b);
但是如果时间戳C(a)<C(b)却不能确定a->b!
因为我们可以知道C(a)<C(b)的时候,可能二者发生在不同进程,而且并行发生,这在分布式系统中是无法比较先后的,因为并行事件代表事件之间是没有因果关系的,而在进程的行为上来说,两个进程之间时间戳的大小,除非通过消息传递互相通知,不然没有比较的意义。
C1:如果a和b都是进程Pi里的时间,并且a在b之前,那么Ci(a)<Ci(b)
C2:如果a是进程Pi里关于某个消息的发送事件,b是另一个进程Pj里关于该校西德接收事件,那么Ci(a)<Cj(b)
假设进程的始终“ticks”(滴答)会穿过所有数字,同时滴答发生在进程的事件之间。也就是说,条件C1意味着在同一进程中任意事件之间存在一条滴答线(把进程中先后发生的两个时间用不同的时间戳表示其先后关系),于此同时条件C2意味着每条消息线一定会跨越一条滴答线(消息的发送事件的时间戳要大于消息接受事件),这两个条件可以让clock condition成立。
图2
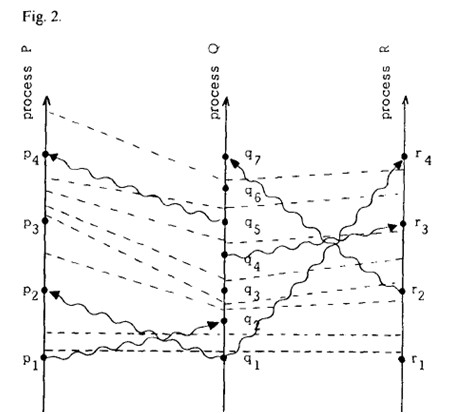
而为了满足clock condition,我们定义一个逻辑时钟,表示全局中可以比较先后的事件和并行发生事件,如图3所示。
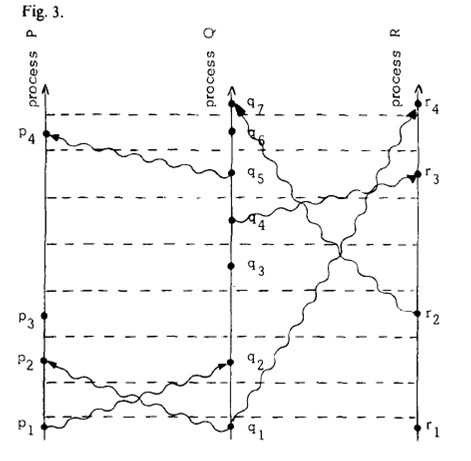
进程Pi的时钟是由Ci来表示,那么Ci(a)就表示事件a发生时Ci的值。
那么需要满足两个条件:IR1.每个进程Pi在任意连续的两个时间之间会增加Ci的值。
IR2(a)如果事件a代表了进程Pi发送消息m的事件,那么消息包含的时间戳Tm=Ci(a)
(b)在收到消息m后,进程Pj会设置Cj的值使得它大于等于它的当前值并大于Tm。
我们目前为止定义了一种偏序关系,只是没有意义的,因为偏序就以为着有不可比较的事件。而分布式的顺序一致性需要全序,这意味着,每一台机器上,对所有事件的发生的顺序的判定都是一致的。
注意:我这里说的是判定,虽然我们有了一致的选择标准,但是,由于异步时间模型,消息的到来是不可知的,所以,每个机器在同一物理时间上看到的可选事件是不同的,这就是并行冲突发生的原因,由此,引出了两种解决并行冲突的方式,一种是悲观(阻塞)的方式,一种是乐观(回滚)的方式。
接下来,就是如何定义一种全序关系了:
lamport说,我们只需要对机器排序就行了,如果Ci(a)=Cj(b){二者逻辑上并行发生},那么我们只需要比较一下他们的机器编号Pi和Pj就可以确定先后关系,这就解决了事件判定的一致性问题了,并且我们把这种关系定义成“=>”。
但是怎么解决统一时间数据不一致问题?
lamport使用了阻塞的方式,这种方式实现简单,但是代价太高,容易造成一台当机,整个集群不可用的问题,而且使得集群串行化。不过,这个方式确实解决了数据的一致性问题。首先,他定义了三个条件:
(1)已经获得资源授权的进程,必须在分配给其他进程之前释放掉它;(2)资源请求必须按照请求发生的顺序进行授权;
(3)在获得资源授权的所有进程最终释放资源后,所有资源请求都已被授权。
算法要满足这三个条件,那么我们首先假定消息的传递是顺序的(TCP可以满足),且消息不管过多长时间都是可以给最终收到。
每个进程维护一个私有的请求队列。算法由如下五个规则定义,每个事件是原子的:
1.为请求该项资源,进程Pi发送一个Tm:Pi资源请求给其他进程,并将消息放入自己的请求队列,在这里Tm代表了消息的时间戳。
2.当进程Pj收到Tm:Pi资源请求消息后,把它放到自己的请求队列中,并发送一个带时间戳的确认给Pi(如果Pj已经发送了一个时间戳大于Tm的消息则可以不发送)
3.释放该资源时,Pi从自己消息队列中删除所有Tm:Pi资源请求,同时给其他进程从发送一个带有时间戳的Pi资源释放消息
4.当进程Pj收到Pi资源释放消息后,它就从自己的消息队列中删除所有的Tm:Pi资源请求
5.当同时满足如下两个条件时,就将资源分配给进程Pi:
(a)按照“=>”全序关系排序后,Tm:Pi资源请求排在它的请求队列的最前面
(b)已经从所有其他进程都收到了时间戳>Tm的消息(注:如果Pi<Pj,那么Pi只需要收到一个>=Tm的消息即可)
规则5中的条件(a),(b)都只需要由进程Pi自己在本地进行判断。
根据规则5,我们而已可以看出这一算法是阻塞的,因为Pi必须等待其收到其他进程的回复,确定早于它申请资源时刻的事件都被它接收,确定自己是当前时间戳和进程号最小的进程(根据"=>"关系)。