我们要实现的是,使用多线程来计算 1 ~ n 范围的所有整数和。
计算运行时间
因为要将普通求和程序与多线程作比较,所以先介绍一下如何计算程序运行的时间。
获取时间函数:
#include<sys/time.h>
int gettimeofday(struct timeval*tv, struct timezone *tz);参数:
其参数tv是保存获取时间结果的结构体,参数tz用于保存时区结果。tz 一般为NULL即可。
struct timezone{
int tz_minuteswest;/*格林威治时间往西方的时差*/
int tz_dsttime;/*DST 时间的修正方式*/
}
struct timeval{
long int tv_sec; // 秒数
long int tv_usec; // 微秒数
}因为上面获取到的时间,拆分为了秒级和微秒两部分,我们需要将他们组合成一个准确的时间。下面是我自定义的函数:
double get_time()
{
struct timeval t;
gettimeofday(&t,NULL);
return t.tv_sec + t.tv_usec/1000000.0;
}
下面进入正题~
多线程求和
比如,我们要计算1到100的整数和,可以将这100个数分为2部分,利用线程并行的特点,同时计算这两部分整数的和,线程1计算1到50,线程2计算51到100,最后将这两部分和在相加。听起来是不是效率变快了一半。
下面我们测试一下,计算 1~100000000的和
//编译的warning不用理会
#include<stdio.h>
#include<stdlib.h>
#include<pthread.h>
#define MAX 1000000000 //整数范围 1 ~ MAX
#define N 100 //创建N 个子线程求和
#define AVE (MAX/N) //每个子线程处理的整数个数
long long *sum = NULL; //保存各个子线程计算的结果
//获取当前时间
double get_time()
{
struct timeval t;
gettimeofday(&t,NULL);
return t.tv_sec + t.tv_usec/1000000.0;
}
//求和子线程
void* sum_work(void* arg)
{
int n = (int)arg; //第n部分
long long start = n*AVE+1;
long long end = start + AVE -1;
long long i;
sum[n] = 0;
//计算start ~ end 范围的整数和
for(i=start; i <= end;i++)
{
sum[n] = sum[n] + i;
}
pthread_exit(0);
}
int main()
{
double t1,t2;
pthread_t *pthread_id = NULL; //保存子线程id
int i;
long long result = 0; //总和
pthread_id = (pthread_t*)malloc(N * sizeof(pthread_t));
sum = (long long*)malloc(N * sizeof(long long));
//开始计算
t1 = get_time();
//创建N个子线程
for(i=0;i<N;i++)
{
pthread_create(pthread_id+i,NULL,sum_work,i);
}
//将各个子线程的求和结果综合到一起
for(i=0;i<N;i++)
{
//等待子线程结束,如果该子线程已经结束,则立即返回
pthread_join(pthread_id[i],NULL);
result += sum[i];
}
//求和结束
t2 = get_time();
//输出求和结果和运行时间
printf("sum of 1 ~ %lld is %lld runtime is %f\n",(long long)MAX,result,t2-t1);
free(pthread_id);
free(sum);
return 0;
}运行结果:5组数据平均1.14秒
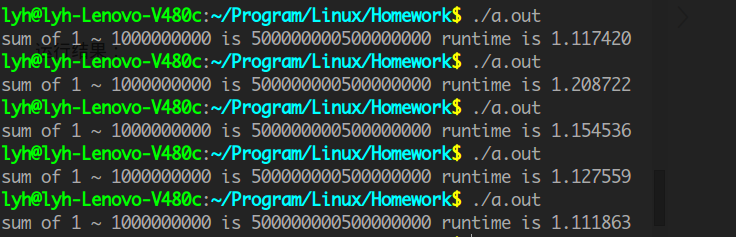
不用多线程的一般求和程序
#include<stdio.h>
#include<sys/time.h>
#define MAX 1000000000
double get_time()
{
struct timeval t;
gettimeofday(&t,NULL);
return t.tv_sec + t.tv_usec/1000000.0;
}
int main()
{
double t1, t2;
long long i;
long long sum = 0;
t1 = get_time();
for(i =1;i<=MAX;i++)
{
sum += i;
}
t2 = get_time();
printf("sum of 1 ~ %lld is %lld runtime is %f\n",(long long)MAX,sum,t2-t1);
return 0;
}运行结果:同样5组数据平均2.62秒
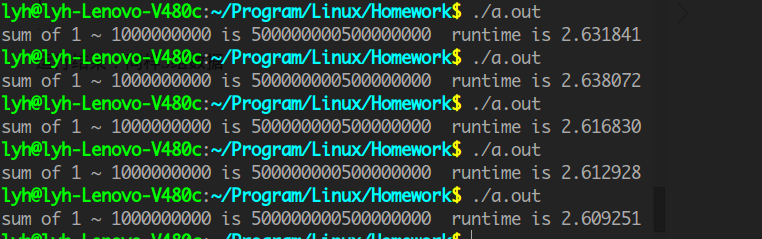
可以看出,与多线程比较差距很明显。
但是,如果将求和的范围缩小,比如将上面的MAX值调成1000,再次运行就会发现多线程计算的时间要比普通程序长了。为什么呢?因为当计算的整数比较少时,本来用的时间就少,而线程的调度也是需要开销的,以及其他增加的语句执行也会花费时间,所以综合起来多线程不但体现不出来优势,反而会托后退。
线程的数量也不是越多越好,大家可以试着改变程序中的N。
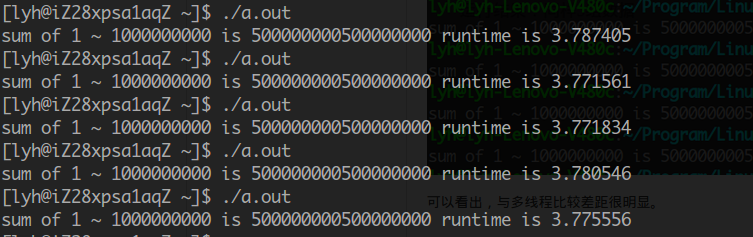
单核CPU
多线程:
普通程序:
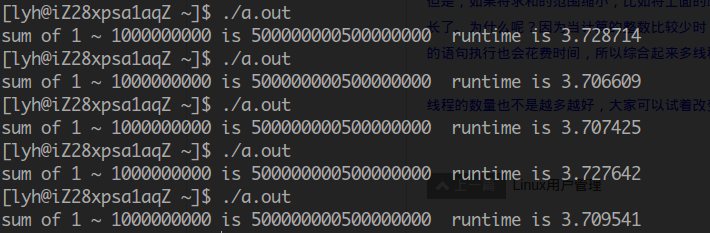
在单核CPU上测试,多线程在这里毫无优势,反而因为线程的额外开销增加了运行时间,因为单核CPU上线程并不能达到真正的并行。
所有,选择多线程还需要根据具体的场景来使用。