项目背景:一个类似云盘的工具,主服务器上的 MySQL(InnoDB 引擎) 存储文件 MD5 值,客户端需要在主服务器上查询文件的 MD5 来获取文件所在服务器的 IP 和文件路径。
问题:在主服务器上如何能更快的查找到文件对应的 MD5。
下面我们通过实际的数据测试来比较不同情况的性能。
前期准备
生成测试数据
由于实际上没有很大的数据量,所以很难测试出性能的不同,这里我用 Java 写了一个随机生成 32 位 MD5 值的代码以模仿实际情况。
单条值如下:
vkQA87d2a9YB5x51VzRcNoS2pbQr5mjv
package tryCode;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Random;
/**
* Created by wwh on 16-3-1.
*/
public class tryMd5 {
static String getMD5(int length){
Random rand = new Random();//随机三个随机生成器
Random randdata = new Random();
StringBuilder sb = new StringBuilder();
int data = 0;
for(int i = 0; i < length; ++i) {
int index = rand.nextInt(3);
switch (index) {
case 0:
data = randdata.nextInt(10); //生成0-9
sb.append(data);
break;
case 1:
data = randdata.nextInt(26) + 65; //生成A-Z
sb.append((char) data);
break;
case 2:
data = randdata.nextInt(26) + 97; //生成a-z
sb.append((char) data);
break;
}
}
return sb.toString();
}
static void insertSql(int number) throws SQLException {
String user = "root";
String secret = "123456789";
String url = "jdbc:mysql://127.0.0.1:3306/try";
Connection conn = DriverManager.getConnection(url, user, secret);
for(int i = 0; i < number; ++i){
String sql = "insert into MD5_3 (md5) values (\"" + getMD5(32) + "\");";
PreparedStatement pre = conn.prepareStatement(sql);
pre.executeUpdate();
}
}
public static void main(String[] args) throws SQLException {
insertSql(729515);
}
}生成了 1 w、10 w、50 w 条测试数据分别存入 3 个表中。为简单起见,表中仅存了主键和 MD5 值。
mysql> show tables;
+---------------+
| Tables_in_try |
+---------------+
| MD5 |
| MD5_2 |
| MD5_3 |
+---------------+
3 rows in set (0.00 sec)
mysql> desc MD5;
+-------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+----------------+
| uid | int(32) | NO | PRI | NULL | auto_increment |
| md5 | char(32) | NO | | NULL | |
+-------+----------+------+-----+---------+----------------+
2 rows in set (0.00 sec)
我们看下选择性:
mysql> select count(distinct md5)/count(*) from MD5;
+------------------------------+
| count(distinct md5)/count(*) |
+------------------------------+
| 1.0000 |
+------------------------------+
1 row in set (0.03 sec)
mysql> select count(distinct md5)/count(*) from MD5_2;
+------------------------------+
| count(distinct md5)/count(*) |
+------------------------------+
| 1.0000 |
+------------------------------+
1 row in set (0.45 sec)
mysql> select count(distinct md5)/count(*) from MD5_3;
+------------------------------+
| count(distinct md5)/count(*) |
+------------------------------+
| 1.0000 |
+------------------------------+
1 row in set (2.95 sec)
选择性为 1 说明随机性很好,没有重复的 MD5 值。
索引的选择性 = 不重复的索引值 / 数据表的记录总数
选择性越高,性能越好。
关闭查询缓存
为了测试数据的准确性,我们关闭查询缓存以避免影响测试结果。
查询缓存也是一个很大的主题,一方面在某些情况下 MySQL 的查询缓存可以极大的提高性能,但另一方面,查询缓存可能成为性能的瓶颈。感兴趣可以查阅相关资料:)
修改配置文件 mysqld.cnf:
我的在 /etc/mysql/mysql.conf.d/下
重启 MySQL
service mysql restart
无自建索引
我们先来看看无自建索引,也就是没有在数据表上显式建立索引。这里我们使用的是 MySQL InnoDB 引擎,关于 InnoDB 引擎的索引相关知识可戳这里。
在我们没有显式指定索引时,MySQL 也会默认帮我们建立索引。因为 MySQL InnoDB 表本身就为一个聚簇索引,默认使用主键建立,里面保存 B-Tree 和数据行。 注意聚簇索引本身不是一种索引,而是一种数据存储格式。一张表只能有一个聚簇索引,如下图:
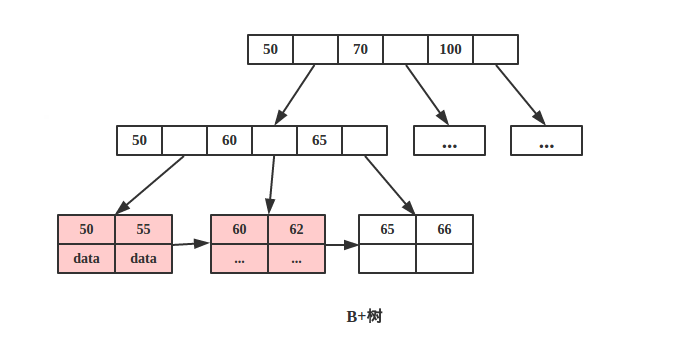
图中仅有叶子节点保存 data,非叶子节点存储 key 的副本。
注意:如果没有定义主键,InooDB 会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB 会隐式定义一个主键为聚簇索引。
主键我们一般定义为一个可自增的整型。也就是说默认我们表上的 MD5 字段是没有索引的,当查找某一条 MD5 时,会 扫描全表。通过 EXPLAIN 可以看到。
mysql> explain select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB";
+----+-------------+-------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | MD5_3 | ALL | NULL | NULL | NULL | NULL | 455637 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+--------+-------------+
1 row in set (0.00 sec)
上图中的 type 是 ALL,说明为全表扫描。
我们来验证一下,选择有 50 w 条数据的表,查询第一条数据和最后一条数据,看看耗时。
mysql> select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB";
+----------------------------------+
| md5 |
+----------------------------------+
| 5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB |
+----------------------------------+
1 row in set (0.12 sec)
mysql> select md5 from MD5_3 where md5 = "5VDUF56jxTF4RQLpRoHybTVc2ZrVmxV9";
+----------------------------------+
| md5 |
+----------------------------------+
| 5VDUF56jxTF4RQLpRoHybTVc2ZrVmxV9 |
+----------------------------------+
1 row in set (0.13 sec)结果:第一条数据耗时 0.12 sec,第二条数据耗时 0.13 sec。
基本上耗时相同,咦?不是顺序查找吗,为什么第一条和最后一条耗时基本相同。因为 InooDB 默认会扫描全表找出数据而不是查询到一条就返回。加上 LIMIT 我们来看看。
mysql> select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB" limit 1;
+----------------------------------+
| md5 |
+----------------------------------+
| 5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB |
+----------------------------------+
1 row in set (0.00 sec)
mysql> select md5 from MD5_3 where md5 = "5VDUF56jxTF4RQLpRoHybTVc2ZrVmxV9" limit 1;
+----------------------------------+
| md5 |
+----------------------------------+
| 5VDUF56jxTF4RQLpRoHybTVc2ZrVmxV9 |
+----------------------------------+
1 row in set (0.12 sec)
加上 LIMIT 我们看到耗时差了很多。第一条数据耗时 0.00 sec,最后一条数据耗时 0.12 sec。
小技巧:当我们需要的数据仅有一行或是唯一的,加上 LIMIT 可以提升性能。
结论:没有显式建立索引时,MySQL InnoDB 会扫描全表,查询的效率是相对低的。
接下来我们显式建立索引来看看。
自建索引
mysql> create index MD5_3_index on MD5_3(md5);
Query OK, 0 rows affected (3.34 sec)
Records: 0 Duplicates: 0 Warnings: 0通过 EXPLAIN 可以看到 Extra 一栏多了一个 Using index
创建完索引后查询会默认使用索引:
mysql> select md5 from MD5_3 where md5 = "5VDUF56jxTF4RQLpRoHybTVc2ZrVmxV9";
+----------------------------------+
| md5 |
+----------------------------------+
| 5VDUF56jxTF4RQLpRoHybTVc2ZrVmxV9 |
+----------------------------------+
1 row in set (0.00 sec)
mysql> select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB";
+----------------------------------+
| md5 |
+----------------------------------+
| 5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB |
+----------------------------------+
1 row in set (0.00 sec)
我们看到不管加不加 LIMIT 都是立刻出结果,0.00 sec。
我们通过 profile 来看看精确时间。
开启 profile:
mysql> set profiling = 1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
查询结果(Query_ID 1.为不建立索引 2.为建立索引):
mysql> show profiles;
+----------+------------+----------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+----------------------------------------------------------------------+
| 1 | 0.12253700 | select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB" |
| 2 | 0.00030075 | select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB" |
+----------+------------+----------------------------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
我们来计算一下:
0.12253700/0.00030075 = 407.438
50 w 数据显示建立索引和不建立索引性能差了 400 多倍!由此可见索引的重要性
注:索引带来的好处可不是这一点点哦:),它还能在高并发的情况下避免死锁,或者说减少阻塞,因为如果无索引,插入删除等操作会顺序扫描全表,在并发的情况下可能会全表加锁(MySQL内部有一些优化操作)。而索引仅仅会锁住满足查询的列。可参考这里
那么能不能更快一点呢?我们来试试
前缀索引
前缀索引就是使用数据的部分来做索引,比如上面 32 位 MD5 值,我们可以选择 16 位或 20 位来做索引。前缀索引能使索引更小,更快。但 MySQL 无法使用前缀索引做 GROUP BY 和 ORDER BY 操作。
在创建前缀索引时要注意的就是计算选择性。必须先测试数据的选择性,接近完整的选择性时才可以使用前缀索引。
比如:MD5 值没有重复的,那么选择性为 1,那么在使用前缀索引时必须确定长度为多少时选择性为 1,以此作为前缀,当然越短越好:)。
50 w 随机 MD5 值前缀选择性如下:
mysql> select count(distinct LEFT(md5, 32))/count(*) from MD5_3;
+----------------------------------------+
| count(distinct LEFT(md5, 32))/count(*) |
+----------------------------------------+
| 1.0000 |
+----------------------------------------+
1 row in set (1.21 sec)
mysql> select count(distinct LEFT(md5, 16))/count(*) from MD5_3;
+----------------------------------------+
| count(distinct LEFT(md5, 16))/count(*) |
+----------------------------------------+
| 1.0000 |
+----------------------------------------+
1 row in set (0.81 sec)
mysql> select count(distinct LEFT(md5, 7))/count(*) from MD5_3;
+---------------------------------------+
| count(distinct LEFT(md5, 7))/count(*) |
+---------------------------------------+
| 1.0000 |
+---------------------------------------+
1 row in set (0.77 sec)
mysql> select count(distinct LEFT(md5, 6))/count(*) from MD5_3;
+---------------------------------------+
| count(distinct LEFT(md5, 6))/count(*) |
+---------------------------------------+
| 0.9999 |
+---------------------------------------+
1 row in set (0.74 sec)
我们看到了当前缀为 6 时,选择性变为了 0.9999,不满足要求,所以前缀选择 7 即可。
这里我们仅创建一个 16 位前缀索引来测试。
创建 16 位前缀索引:
mysql> alter table MD5_3 add key(md5(16))
mysql> select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB"查询结果:
+----------+------------+----------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+----------------------------------------------------------------------+
| 1 | 0.00024925 | select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB" |
| 2 | 0.00025325 | select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB" |
| 3 | 0.00022800 | select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB" |
| 4 | 0.00024625 | select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB" |
+----------+------------+----------------------------------------------------------------------+
平均耗时:0.00024419
比普通索引快了大约 1/5。
可见性能还是有提升的。
Hash 索引
最后,我们来简单看一下 Hash 索引,因为现在仅假设数据有 50 w 条,当数据量很大时如上千万条,重复前缀就很多了。此时前缀索引不一定能优化。我们可以将 MD5 字符串进行 Hash,将 Hash 数值结果和对应的 MD5 保存在同一张表,然后在 Hash 值和 MD5 建立单索引或双索引(多列索引)。这样 MySQL InnoDB 会优先比较 Hash 值(左前缀),若 Hash 值相同再比较第二列。数值比较会比字符串比较快很多。
但这种方法在某些情况下会有缺陷,我们可能需要维护 Hash 值。不过在我的场景下 MD5 值是不变的,固 Hash 值不变。
我们来试试
先给表增加字段
mysql> alter table MD5_3 add crc int(32) unsigned default 0 not null;
mysql> update MD5_3 set crc = crc32(md5);
Query OK, 500440 rows affected (2.19 sec)
Rows matched: 500440 Changed: 500440 Warnings: 0
可以看到 50W 行数据2.19sec完成,crc速度还是非常快的。
不建立索引测试下两者速度
mysql> select md5 from MD5_3 where md5 = 'ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I';
+----------------------------------+
| md5 |
+----------------------------------+
| ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I |
+----------------------------------+
1 row in set (0.13 sec)
mysql> select md5 from MD5_3 where crc = crc32('ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I');
+----------------------------------+
| md5 |
+----------------------------------+
| ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I |
+----------------------------------+
1 row in set (0.14 sec)差不多
建立索引看看
mysql> select md5 from MD5_3 where md5 = "ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I";
+----------------------------------+
| md5 |
+----------------------------------+
| ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I |
+----------------------------------+
1 row in set (0.00 sec)
mysql> select md5 from MD5_3 where
-> crc = crc32("ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I") and
-> md5 = "ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I";
+----------------------------------+
| md5 |
+----------------------------------+
| ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I |
+----------------------------------+
1 row in set (0.00 sec)来看下耗时:
+----------+------------+--------------------------------------------------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+--------------------------------------------------------------------------------------------------------------------------+
| 2 | 0.00058175 | select md5 from MD5_3 where crc = crc32("ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I") and md5 = "ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I" |
| 3 | 0.00044100 | select md5 from MD5_3 where md5 = "ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I"
+----------+------------+--------------------------------------------------------------------------------------------------------------------------+
普通索引更快一些,基本差不多,可能因为 CRC32 函数有些耗时。在实际中,我们可以在请求 MD5 前先算好 MD5 的 crc 值再来查询,这样速度应该会快些,具体我们应该先测试然后根据实际情况来选择性能最好的。
在 EXPLAIN 中我发现了一个问题:
mysql> explain select md5 from MD5_3 where crc = crc32("ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I") and md5 = "ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I";
+----+-------------+-------+------+---------------------+-----------+---------+-------+------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------------+-----------+---------+-------+------+------------------------------------+
| 1 | SIMPLE | MD5_3 | ref | md5_index,crc_index | md5_index | 96 | const | 1 | Using index condition; Using where |
+----+-------------+-------+------+---------------------+-----------+---------+-------+------+------------------------------------+
1 row in set (0.00 sec)
mysql> explain select md5 from MD5_3 where md5 = "ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I";
+----+-------------+-------+------+---------------+-----------+---------+-------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+-----------+---------+-------+------+--------------------------+
| 1 | SIMPLE | MD5_3 | ref | md5_index | md5_index | 96 | const | 1 | Using where; Using index |
+----+-------------+-------+------+---------------+-----------+---------+-------+------+--------------------------+
1 row in set (0.00 sec)
注意 Extra 字段,一个为 Using index,一个为 Using index condtion。
查了相关资料发现这是 MySQL 5.6新特性—— Index Condition Pushdown(ICP,索引条件下推)
ICP(index condition pushdown)是mysql利用索引(二级索引)元组和筛字段在索引中的where条件从表中提取数据记录的一种优化操作。ICP的思想是:存储引擎在访问索引的时候检查筛选字段在索引中的where条件(pushed index condition,推送的索引条件),如果索引元组中的数据不满足推送的索引条件,那么就过滤掉该条数据记录。
看下 MySQL 手册的定义:
Index Condition Pushdown (ICP) is an optimization for the case where MySQL retrieves rows from a table using an index. Without ICP, the storage engine traverses the index to locate rows in the base table and returns them to the MySQL server which evaluates the WHERE condition for the rows. With ICP enabled, and if parts of the WHERE condition can be evaluated by using only fields from the index, the MySQL server pushes this part of the WHERE condition down to the storage engine.
简单来说,就是将本身需要推送到 Server 层的操作在索引上就过滤掉,以提高性能。ICP 可以减少存储引擎必须访问基表的次数和 MySQL 服务器必须访问存储引擎的次数。
具体了解可以看看这位朋友的文章
顺便说一句,MySQL使用的是聚簇索引,我们建立普通索引时,其实是 二级索引,二级索引会保存 key 和 主键,MySQl 会首先在 二级索引 上找到需要的 key,然后获得对应的主键,然后在去聚簇索引上找数据。
对了,当我们确定某一个值是唯一的时,可以设置 唯一约束,MySQL 会默认给唯一约束建立索引~,加快查询速度。
注意:
MySQL 只会选择一次索引,若有多个只会选择一个
MySQL 不是很聪明,有时候我们需要强制指定索引
本文完,如有错误,欢迎指正:)
from XiyouLinuxGroup By wwh