一、基础知识
linux是一个多用户多任务的操作系统,多用户就是指允许多个用户在同一时间登录使用计算机,多任务是指linux可以同时执行多个任务,可以在还未执行完一个任务时又去执行另一个任务。进程是操作系统资源管理的最小单位,简单来说它是运行中的程序。
进程是程序的一次执行,是一个动态的实体,而程序则是一些保存在硬盘上的可执行代码它是静态的实体。在linux中每一个进程都分配有一个独立的唯一的ID(非负数),操作系统以这些ID来标识这些进程。
进程的内存映像是指内核在内存中存放可执行程序的方法,linux下的程序映像布局如下:
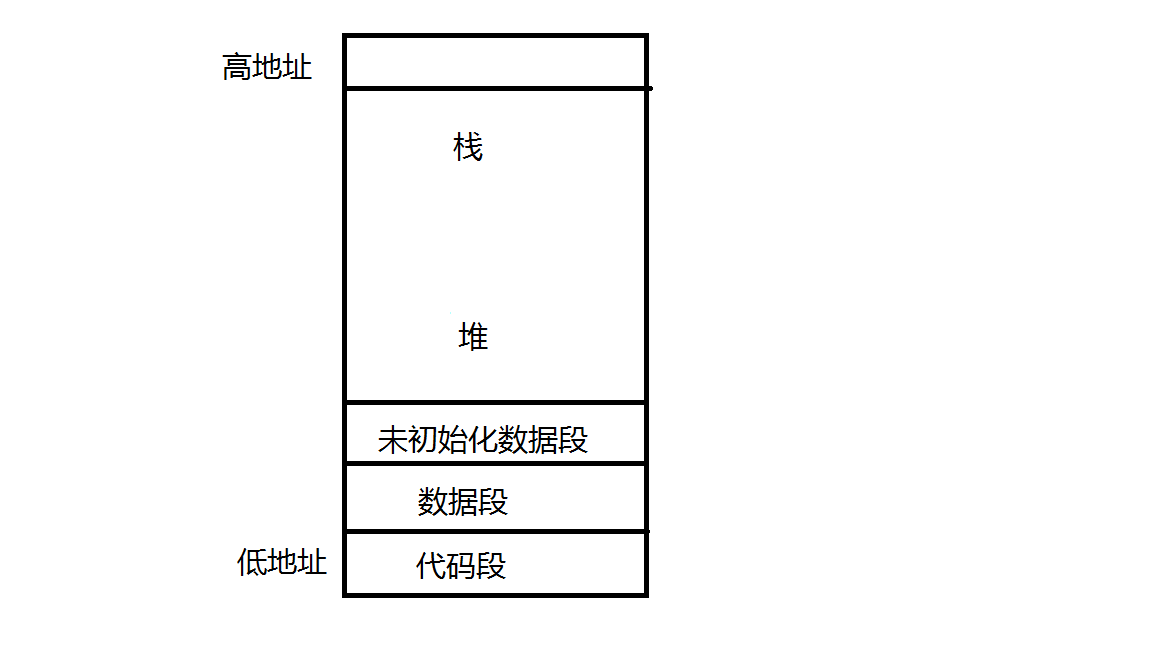
1)、代码段(.text段):二进制代码(只读),可被多个线程共享。
2)、数据段(.data段):存储已经被初始化的全局变量和静态局部变量。
3)、未初始化数据段(.bss段):存储未被初始化的全局变量。
4)、堆(heap):存放程序运行中动态分配的内存。
5)、栈(stack):存放局部变量,用于函数调用,保存函数返回值等。
6)、高地址:存放命令行参数和环境变量。
在进程中.data段和.bss段是一直存在于程序的整个生命周期的。
二、创建进程
创建进程最常用的是fork()和vfork()两个函数,这两个函数的区别如下:
1)、fork()创建的子进程与父进程完全独立,它是父进程的一份拷贝,拥有独立的系统资源,具有良好的并发性,当然这样的创建方式对于系统的开销是非常大的,对于一些并不需要子进程拷贝父进程的程序而言这种开销是完全没有必要的。而vfork()创建的进程与父进程共享系统资源,这样的创建对于系统开销相比第一种着实降低了好多。
2)、fork()创建的进程与父进程的执行顺序与系统的进程调度算法有关,而vfork()创建的进程会让子进程先执行,当子进程调用exit()结束进程时才结束子进程而继续父进程。
通过一个程序来看fork()与vfork()的区别:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int globvar = 5;
int main(void)
{
pid_t pid;
int var = 1,i;
pid = fork();
// pid = vfork();
switch (pid)
{
case 0 :
i = 3;
while (i-- > 0)
{
printf("子进程正在运行!\n");
globvar++;
var++;
sleep(1);
}
printf("子进程的globvar = %d,var = %d\n",globvar,var); break;
case -1 : perror("ERROR"); break;
default :
i = 5;
while (i-- > 0)
{
printf("父进程正在运行!\n");
globvar++;
var++;
sleep(1);
}
printf("父进程的globvar = %d,var = %d\n",globvar,var); break;
}
return 0;
}

因为这里加入了语句sleep(1);我们可以看到父子进程是交替执行的,父进程中globvar、var与子进程中的globvar、var互不干扰。
现在将pid = fork();注释掉,将pid = vfork();取消注释看看运行结果。
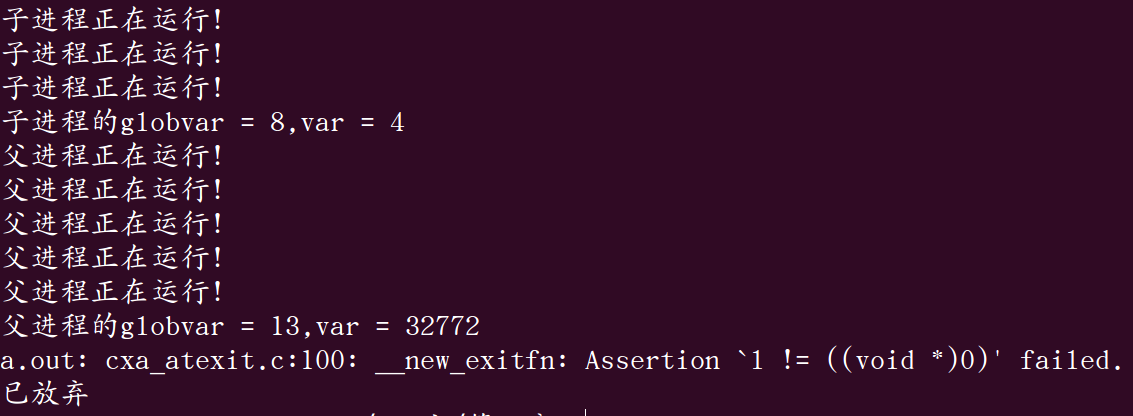
从运行结果看出子进程是先于父进程执行的,但是后边的结果貌似不是我们所期盼的,这是为什么呢?通过google和请教学长终于得出了一个结论。
vfork()创建的子进程只能由exit()结束,然后才能继续执行父进程。但这个结果明显不能完全说服人,因为我们看到父进程明明是执行了,那么父进程是怎么执行的呢?原来如果不让子进程执行exit()结束的话它就会执行到return 0;这一句,然后将main函数结束掉,随之为main分配的栈就会弹出,因为父子进程的资源共享,所以父进程的栈也就随之挂了,这时候就发生上述灵异事件了,父进程再次进入main函数(事实上有的版本的内核在这里就发生段错误了),但是现在的栈已经不是以前的栈了,上边的局部变量也不再是以前的局部变量了(局部变量保存在栈上,旧栈弹出,局部变量销毁),取而代之的是新栈上的垃圾值(这里有点类似定义了一个变量没有初始化而直接引用),因此局部变量var是一个很奇葩的值,而全局变量globvar在.data区存储着,它存在于整个程序的生命周期,所以它的值是正确的。
将上述程序中case 0:后边的break;该换成exit(0);后出现了我们期待已久的结果:
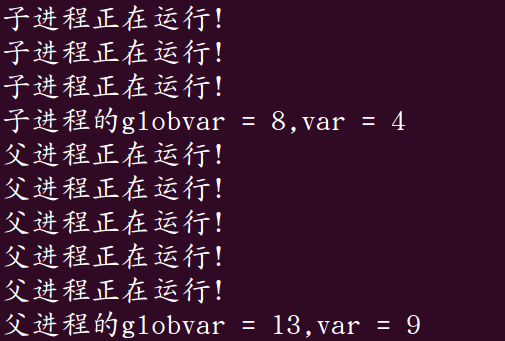
从结果中我们可以看出子进程执行完后父进程执行,并且父子进程共享内存资源。