内容包括:
- 概念和基本使用
- 索引的优缺点及使用场景
- 索引底层结构(B,B+树及优缺点对比)
- 高效使用索引
- 聚簇索引与非聚簇索引
概念
索引存储在内存中,为服务器存储引擎为了快速找到记录的一种数据结构。
基本操作
为数据表添加索引:
ALTER TABLE table_name ADD INDEX index_name (column_list) //普通索引
ALTER TABLE table_name ADD UNIQUE (column_list) //唯一性索引,设置后,不允许插入重复值
ALTER TABLE table_name ADD PRIMARY KEY (column_list) //唯一索引,通常用于自增主键。
删除索引
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
查看索引
SHOW INDEX FROM tblname;
SHOW KEYS FROM tblname;
优缺点及使用场景
- 减少表的检索行数,提高查询效率
- 建立唯一索引或者主键索引,保证数据字段的唯一性
- 检索时有分组和排序需求时,减少服务器排序的时间
缺点:
- 创建和维护索引需要消耗时间及内存,随着数据的增加而增加
- 索引字段过多,数据量巨大时,索引占据空间可能比表更大。
- 当对表的数据进行更新操作时,索引也要动态的维护,这样就会降低数据的维护速度。
使用注意:
- 表数据较小时不建议使用,此时全表扫描可能效率更好。
- 在经常需要where、排序、分组、取区间的列上建议使用。
- 列不能作为表达式的一部分,或者用作函数参数,否则失效。
- 当表更新操作远大于select操作时,不建议添加索引。
索引底层数据结构了解
B树
平衡多路查找树,一棵m阶的B树。
特性:
- 树中每个结点最多含有m个孩子( m >= 2 );
- 除根结点和叶子结点外,其他每个结点至少 m/2 个孩子。
- 若根结点不是叶子,至少2个孩子。
- 有 j 个孩子的非叶节点恰好有 j-1 个关键码,关键码按递增次序排序。

B树存在磁盘中,我们想要查找29,查找过程:
1. 根据根结点找到文件目录的根磁盘块1,将其中信息导入内存。 【磁盘IO操作一次】
2. 此时内存中有两个文件17,35和三个存储其他磁盘页面地址的数据。 比较:17<29<35,因此我们访问指针P2
3. 根据P2指针,我们定位到磁盘3,并将其信息导入内存。【磁盘IO操作2次】
4. 此时内存中有两个文件26,30和三个存储其他磁盘页面地址信息的指针,26<29<30,因此我们找到P2指针。
5. 根据P2指针,定位到磁盘8,将其中信息导入内存。【磁盘IO操作3次】
B+
相对B树的不同特性:
- 非叶子节点的值会以最大或最小值出现在其子节点中,即叶子节点包含所有元素。
- 非叶子节点带有索引数据和指向叶子节点的指针,不包含指向实际元素数据的地址信息。仅叶子节点有所有元素信息。
- 每个元素不保存数据,只保存索引值即主键。
- 所有叶子节点形成一个有序链表。

单行查询时与B树相同
范围查询时,比如查找大于3小于8的数据,根据单行查找方式查找到3之后,通过链表直接遍历后面的元素。
B+树优势:
- B+树的磁盘读写代价更低。同样的一块磁盘大小,B树需要存储表元素数据,B+只需要存储索引,可以存储更多节点。同等元素数据量下,B+树层数更少。
- B+树的查询效率稳定。因为非终结点只是关键字的索引,所以任何关键字的查找必须走一条根到叶子的路。
- B+树中叶子结点也成一个链表,所以B+树在面对范围查询时比B树更加高效。
InnoDB索引使用
索引分主索引和辅助索引
主索引在表创建后即存在。以主键为索引,叶子节点存储元素数据。
为主键外的字段添加的索引为辅助索引。以字段内容为索引,叶子节点存储元素对应主键。
MyISAM不同点在于叶子存储的不是元素数据,而是元素数据地址。实现索引与实际数据分离。
如何高效率使用索引
独立列查询
SQL语句使用不当时,将无法使用现存索引而去全表扫描。所以需要注意:索引列不能是表达式的一部分,也不能是函数的参数。
通过在查询SQL前加explain,查看是否有使用索引。

上图中,为timestamp字段添加了索引。 明显使用DATE()函数后,timestamp不使用索引,rows行数为总数据行数。
前缀索引查询(注意选择性把握)
选择性指不重复的索引值和数据表的记录总数的比值。选择性最高时,即所有键不重复时选择性为1。
由上面对索引内部实现的描述我们得知,我们索引的字段越长时,所占内存也就越大。前缀索引意在保持较高选择性的情况下,取字段的前缀部分用于索引,降低内存使用率。
我对测试表中pdl字段及前缀部分的选择性进行观测如下:
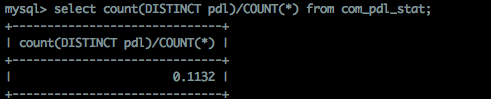
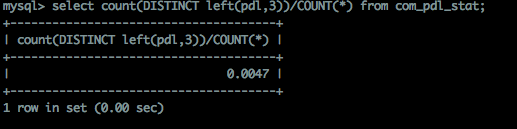

如图,前缀为9时选择性已经较高,再增加时,没有明显提升。这时,如果pdl字段很长,就可以考虑使用pdl的前缀9个字符作为前缀索引。
alter table com_pdl_stat add key `left_pdl`(pdl(9));
注意:无法使用前缀索引做ORDER BY 和 GROUP BY,考虑业务场景做取舍。
多列索引合并
很多时候我们为了查询方便,为很多列单独创建索引。但我们在使用where筛选时,却多使用AND,OR等条件。
当我为表的pdl,timestamp字段单独设置索引时,and查询为:

通过key标志知道此时仅使用了pdl字段的索引。filtered仅17.92.
这里的仅使用了pdl字段索引。(高性能提到5.0之后的版本会各自使用pdl和timestamp字段,然后SQL服务器对多个索引结果做相交(AND)或联合操作(OR)操作,通过extra可查询,但是我的5.7没有这种优化,不知道为什么~~)
如上,仅使用where条件的第一个字段索引 或者 服务器消耗CPU,内存等资源去做合并工作,都会影响查询性能。
这是有必要合并索引,创建pdl_time(pdl, timestamp)索引后同样的查询结果如下:

pdl_time索引被使用,filtered达到100%。
在创建多列索引时注意:
- 通常将选择性高的字段放在前面
- 多列字段的前缀也可以作为索引(例如(a,b)索引时,可以单独使用a索引,但不能单独使用b索引)
聚簇索引
聚簇索引指的是一种数据组织结构。判断标准为:索引的叶子节点中,存储的是数据还是只想数据块的指针。如果是指向数据块指针,则为非聚簇索引。
索引类型依赖存储引擎,Innodb使用的是聚簇索引,MyISAM使用非聚簇索引
Innodb主键索引图:

如图为Innodb存储引擎生成的主键索引结构。非叶子节点存储主键,叶子节点存储主键和行数据(还有事务ID和回滚指针)。
Innodb辅助索引图:

如图为Innodb存储引擎生成的辅助索引结构。叶子节点存储索引字段和对应的主键值,索引到主键值后,根据主键值再去主键索引中查找对应的数据。
优点在于:
- 减少磁盘IO次数。使用索引查询数据时,索引节点和数据被一起载入内存,不需要根据指针再进行一次IO读取。
- 无需维护辅助索引。当出现数据页分裂时,无需更新索引中的数据块指针。
非聚簇索引图:

非聚簇索引主键索引和辅助索引结构一致。