两大规则:
1:某个成员距离首位置的偏移量最小是该成员大小的一倍。
2:所有成员的大小之和应该是最大成员大小的整数倍。
为什么要内存对齐?点这里
来段代码解释下:
#include<stdio.h>
struct student1
{
char a;
short b;
int c;
}stu1;
struct student2
{
char a;
int b;
short c;
}stu2;
int main()
{
printf("sizeof(stu1) : %d\n",(int)sizeof(stu1));
printf("sizeof(stu2) : %d\n",(int)sizeof(stu2));
return 0;
}

我们接下来就来解释为什么stu1和stu2分别是8和12,主要还是我们的两个规则:
注意:下面的表示方法,例如short b 就会在两个字节中填b,表示占用两个字节*
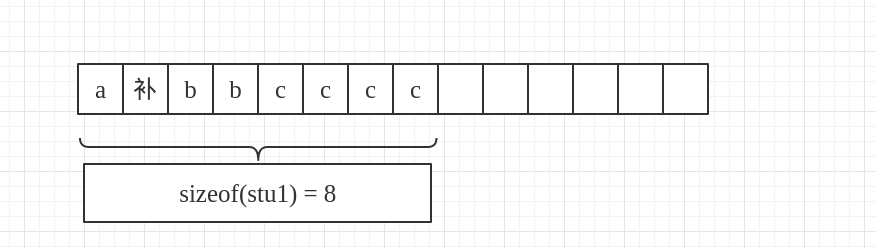
对于stu1来说,a是char类型的,占1个字节.如图:

b是short类型的,占2个字节,由于规则1,某个成员距离首位置的偏移量最小是该成员的1倍,但是此时b距离首位置只有a这一个字节,所以补一个字节,如图:

再说到c为一个int类型的,占用4个字节,我们用规则1去验证,现在它距离首位置的偏移量是4,并且它自己也占用4个字节,刚好是一倍,满足规则1,再来看规则2,所有成员的大小之和应该是最大成员大小的整数倍,现在c为int类型,加上前面的4个字节,一共是8个字节,是最大成员c的字节数的2倍,满足规则2,所以就直接将c放在后面.如图:
那么对于stu2来说呢,
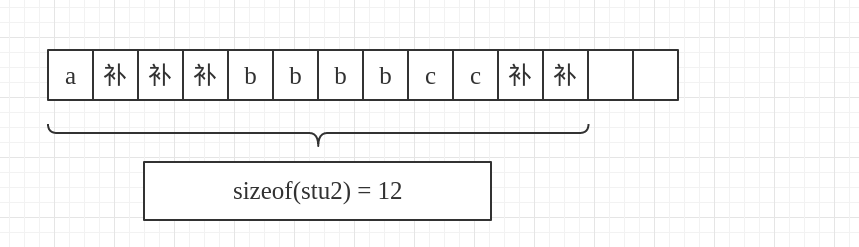
首先char a还是一样的,a占用一个字节.如图:

再说b,b是一个int类型的变量,首先根据我们的规则1,距离首位置的偏移量至少是该成员的一倍,所以应该补3个位置,如图:

再说short c,根据规则1,现在的成员偏移量为8,c的大小为2,满足规则1,再来看规则2,目前我们所有成员的大小为10,并不满足目前成员大小为最大成员(int b)大小的整数倍,所以需要再补两个字节,总大小构成12,就是4的整数倍了,如图:
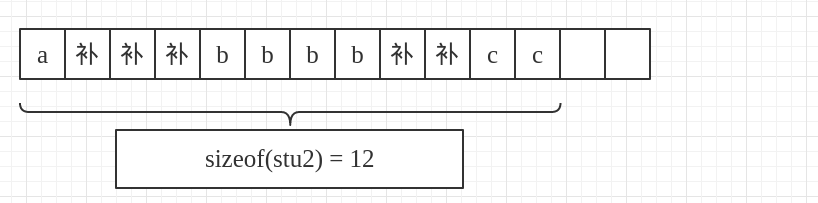
好,基本上就是这样,但是有没有思考过我在最后补的两个字节为什么要补在最后呢,难道不会是下面这样吗?
好,带着这个问题,我们来看看下面的这段代码:
#include<stdio.h>
struct node1
{
int a;
int b;
int c;
};
struct node2
{
char a;
char b;
short c;
int d;
};
int main()
{
struct node1 s1 = {3,5,6};
struct node2 s2 = {3,5,6,99};
struct node *p1 = &s1;
struct node *p2 = &s2;
printf("%d\n",*(int *)p1);
printf("%d\n",*(int *)p2);
}

恩,这个执行结果有点糟糕啊,第一个执行结果到是没什么问题,但是第二个394499怎么解释呢.
原因就要牵扯到内存对齐的问题,再次回忆下内存对其两个原则,一个最小,一个最大,一个最小:某个成员目前的偏移量最小是这个成员的一倍,一个最大:所有成员的大小之和是最大成员的整数倍.
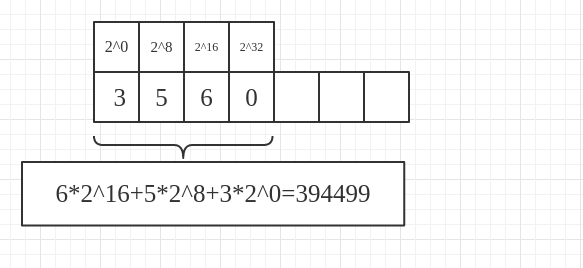
现在再来分析:我分别给a,b,c赋值3,5,6.即分别占用1,1,2个字节,总共就是4个字节,即一个int,那么我最后printf中的值肯定就是这4个字节组成的,按照低地址存入,高地址输出的原则,所以在内存中会是这样计算,6*2^16+5*2^8+3*2^0 = 394499,(2^16是宏观把握的结果)如图:
所以补的位置就是上面例子的位置,而不是先补后加数据,原因上面的例子已经得到很好的验证,至于为什么要这样,不是补在低位呢,我还没研究这么深,搞懂再说吧……