暑假留校第二次讲座,讲了很多东西,听的时候零零散散记下一些关键词,现在把这些整理以下,以免以后忘记
编码规范
作为一个程序员,必不可少的事儿就是写代码,每个人写代码的风格和形式可能有所不同,我觉得这和一开始接触代码,写代码的时候慢慢形成的习惯,在我看来,写代码就像写字一样,还是要有一定的规范标准,按着这个规范来,写出的代码看起来会好看一些,舒服一些
1.代码缩进
代码缩进的时候可以手动打出4个空格,或者按Tab键自动向后空出4个空格,学长的建议是手动打出4个空格,因为有的配置可能Tab缩进的是4个空格,有的可能是8个空格,这些可以设置,但如果用Tab 的话有的源码分析工具可能分析不出来,出错,因此还是手动打出4个空格较好
2.switch和case
在没听讲座之前,我习惯于把case缩进到switch之后,感觉那样会好看些,学长建议是把switch和case对齐,因为case后面的代码少了还没问题,如果case后面代码很多,这样就不容易看出来case属于那个switch,也有可能把case忽略掉,如果对齐的话就会好一点,想想也是,如果缩进很多的话,的确不容易看出case和switch的所属关系
例子
/*对齐*/ /*缩进*/
switch(x){// switch(x){
case 1: case 1:
case 2: case 2:
case 3: case 3:
default: default:
} }3.一行只写一条语句
if while等后面要加上{}即使{}内只有一条语句
fd = open();等号两边要加两个空格空出一点距离
在刚开始学习写代码的时候老师也强调过一行写一条语句,C语言自由度很高,一行写几条语句也没问题,但写出的程序不仅要完成一些功能,解决一些问题,还要让别人能阅读,阅读起来更舒服,一般我阅读的时候会一行一行看,这行是什么 ,然后跳掉下一行,这也许是一种思维习惯,如果一行中写了几条语句可能会一次要理解好几条语句,所以在感觉上有些不舒服,还有一点就是一行写几条语句可能会显得代码太紧密,不便阅读,if while 等后面加{}一方面是为了使代码更清晰明了,可以一眼看出哪个语句属于哪个if 或者while等等,另一方面也是让代码更美观,阅读起来更方便,等号两边加空格也是同样的作用,连在一起显得太过紧密,加一些空格会看的很清晰
函数命名法
一、匈牙利命名法【Hungarian】: 广泛应用于象 Microsoft Windows 这样的环境中。 Windows 编程中用到的变量(还包括宏)的命名规则匈牙利命名法, 匈牙利命名法通过在变量名前面加上相应的小写字母的符号标识作为前缀, 标识出变量的作用域, 类型等。这些符号可以多个同时使用,顺序是先 m_(成员变量),再指针,再简单数据类型, 再其他。例如:m_lpszStr, 表示指向一个以 0 字符结尾的字符串的长指针成员变量。
二、骆驼命名法【camelCase】:
骆驼式命令法,正如它的名称所表示的那样,是指混合使用大小写字母来构成变量和函数 的名字。例如,下面是分别用骆驼式命名法和下划线法命名的同一个函数: printEmployeePaychecks(); print_employee_paychecks(); 第一个函数名使用了骆驼式命名法——函数名中的每一个逻辑断点都有一个大写字母来标记; 第二个函数名使用了下划线法—-函数名中的每一个逻辑断点都有一个下划线来标记。
三、帕斯卡命名法【PascalCase】: 与骆驼命名法类似。只不过骆驼命名法是首字母小写,而帕斯卡命名法是首字母大写 如:public void DisplayInfo(); string UserName;
一个函数最好不要写的太长,可以将代码分成几个块,函数也能分成块,用函数的嵌套可以让程序看起来更有层次感,逻辑更加清晰
写一个程序的时候,重要的不是写代码,更多的是设计程序的思路和想法,只有把思路和逻辑想清楚以后,在用代码显示出来,写代码的时候也就更快,出错也就会更少,在调试程序的时候也会更容易找到错误
如果要写很长的代码时候,最好不要一次性写完,然后在调试,代码分成块,写完一块就进行测试调试,调试好以后在写下一个分块,这样最后找错误的时候就会容易的多
源码分析工具和调试器
学长介绍了几个源码分析工具和调试器
源码调试工具:
1.Ctags
2.Gtags
3.find
4.grep
调试器:
1.gdb
2.cgdb
3.DDD
优化代码
1.数据上优化
2.数据结构优化
3.算法优化
SMP与多核
SMP:
SMP的全称是”对称多处理”(Symmetrical Multi-Processing)技术,是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存子系统以及总线结构。
它是相对非对称多处理技术而言的、应用十分广泛的并行技术。在这种架构中,一台电脑不再由单个CPU组成,而同时由多个处理器运行操作系统的单一复本,并共享内存和一台计算机的其他资源。虽然同时使用多个CPU,但是从管理的角度来看,它们的表现就像一台单机一样。系统将任务队列对称地分布于多个CPU之上,从而极大地提高了整个系统的数据处理能力。所有的处理器都可以平等地访问内存、I/O和外部中断。在对称多处理系统中,系统资源被系统中所有CPU共享,工作负载能够均匀地分配到所有可用处理器之上。
多核
多内核(multicore chips)是指在一枚处理器(chip)中集成两个或多个完整的计算引擎(内核)。
我们说多核机器,是指一块CPU芯片里面有多个核心,核心与核心之间的通信是由
CPU芯片内部的总线完成的;
静态链接
GCC编译程序过程
1.预编译
预编译又称为预处理,是做些代码文本的替换工作。是整个编译过程的最先做的工作。
预编译又称为预处理,是做些代码文本的替换工作。
处理#开头的指令,比如拷贝#include包含的文件代码,#define宏定义的替换,条件编译等
就是为编译做的预备工作的阶段
主要处理#开始的预编译指令
2.编译
(1)利用编译程序从源语言编写的源程序产生目标程序的过程。
(2)用编译程序产生目标程序的动作。 编译就是把高级语言变成计算机可以识别的2进制语言,计算机只认识1和0,编译程序把人们熟悉的语言换成2进制的。
(3)编译程序把一个源程序翻译成目标程序的工作过程分为五个阶段:
①词法分析
②语法分析
③语义检查和中间代码生成
④代码优化
⑤目标代码生成。
主要是进行词法分析和语法分析,又称为源程序分析,分析过程中发现有语法错误,给出提示信息。
3.汇编
汇编过程实际上指把汇编语言代码翻译成目标机器指令的过程。对于被翻译系统处理的每一个C语言源程序,都将最终经过这一处理而得到相应的目标文件。目标文件中所存放的也就是与源程序等效的目标的机器语言代码。
4.链接
链接程序的主要工作就是将有关的目标文件彼此相连接,也即将在一个文件中引用的符号同该符号在另外一个文件中的定义连接起来,使得所有的这些目标文件成为一个能够被操作系统装入执行的统一整体。
GCC的编译链接过程包括:
1. C预处理器(cpp),处理所有的宏定义,生成文本文件.i
2. C编译器(cc1),生成汇编语言文件.s
3. 汇编器(as)生成可重定位的目标文件.o
4. 链接器(ld)把所有的.o和库组合成一个可执行的目标文件
a) 符号解析:将每个符号的引用和一个符号定义联系起来
b) 重定位:编译(cc1和as)生成的代码(.text)和数据(.data)节的起始地址是0,需要把每个符号的定义和一个存储器位置联系起来,然后修改所有对这些符号的引用。
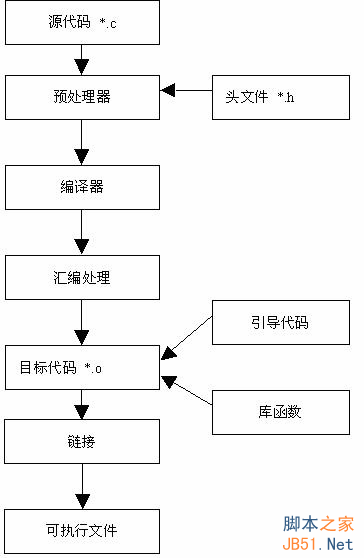
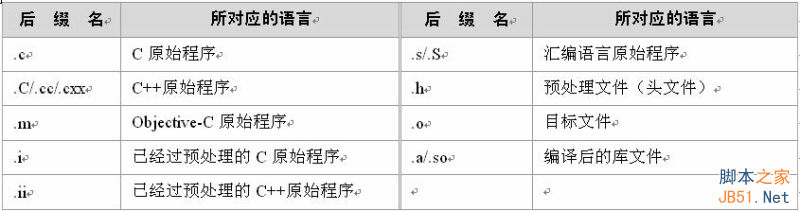
常用文件后缀名
静态链接
静态链接是由链接器在链接时将库的内容加入到可执行程序中的做法。链接器是一个独立程序,将一个或多个库或目标文件(先前由编译器或汇编器生成)链接到一块生成可执行程序。
静态链接的最大缺点是生成的可执行文件太大,需要更多的系统资源,在装入内存时也会消耗更多的时间。
静态链接库
静态链接库就是你使用的.lib文件,库中的代码最后需要连接到你的可执行文件中去,所以静态连接的可执行文件一般比较大一些。格式如:#pragma comment(lib,”XXX.lib”)
linux下的静态链接库是*.a文件,与动态链接库.so对应。
linux下.a文件,如果编写了入口函数,也可以直接执行