错误率: 分类错误的样本数占样本总数的比例成为“错误率”。
精度 : 精度 = 1 - 错误率。
泛化误差: 训练结果在新的测试集上的误差。
过拟合:训练将本身的一些特点当做了潜在的一般性质进行了学习。
欠拟合:对训练样本的一般性质尚未学好。
关于NP问题,机器学习面临的问题通常是NP难甚至是更难的问题,而有效的学习算法必须是多项式时间内的。若可彻底避免过拟合,则通过经验误差最小化就能获得最优解,这就意味着我们构造了“P = NP”,因此只要相信,“P != NP”过拟合问题就不可避免。
独立同分布:在概率统计理论中,如果变量序列或者其他随机变量有相同的概率分布,并且互相独立,那么这些随机变量是独立同分布。
随机变量X1和X2独立,是指X1的取值不影响X2的取值,X2的取值也不影响X1的取值.随机变量X1和X2同分布,意味着X1和X2具有相同的分布形状和相同的分布参数,对离散随机变量具有相同的分布律,对连续随机变量具有相同的概率密度函数,有着相同的分布函数,相同的期望、方差。反之,若随机变量X1和X2是同类型分布,且分布参数完全相同,则X1和X2完全一定同分布!
评估的方法:
留出法:直接将数据集D划分为两个互斥的集合,其中一个集合用来训练集S,另一个作为测试集T。当然采样的时候可以采用“分层采样的方法”。对于一般情况下,常见的做法是将大约2/3 ~ 4/5 的样本用来训练,剩下的用来测试。
交叉验证法:
现将数据D划分成k个大小相似的互斥子集,然后每次使用k-1个子集训练,剩下的子集用来作为测试集。这样做的有一个问题就是计算量瞬间变大。
自助法:
自助法直接以自助采样法为基础,每次从集合D中随机抽样获取一个样本,放入测试集中,然后重复M次,我们简单估计,始终不被采样得到的概率是(1 - 1/m)^m ,取极限得到1/e
大约是0.368。
调参与最终模型:
机器学习常常设计两类参数,第一类是算法的参数,也称“超参数”。数目常常在10个以内,另一个是模型参数数目不定,在深度学习模型中可能成百的参数。
性能度量:
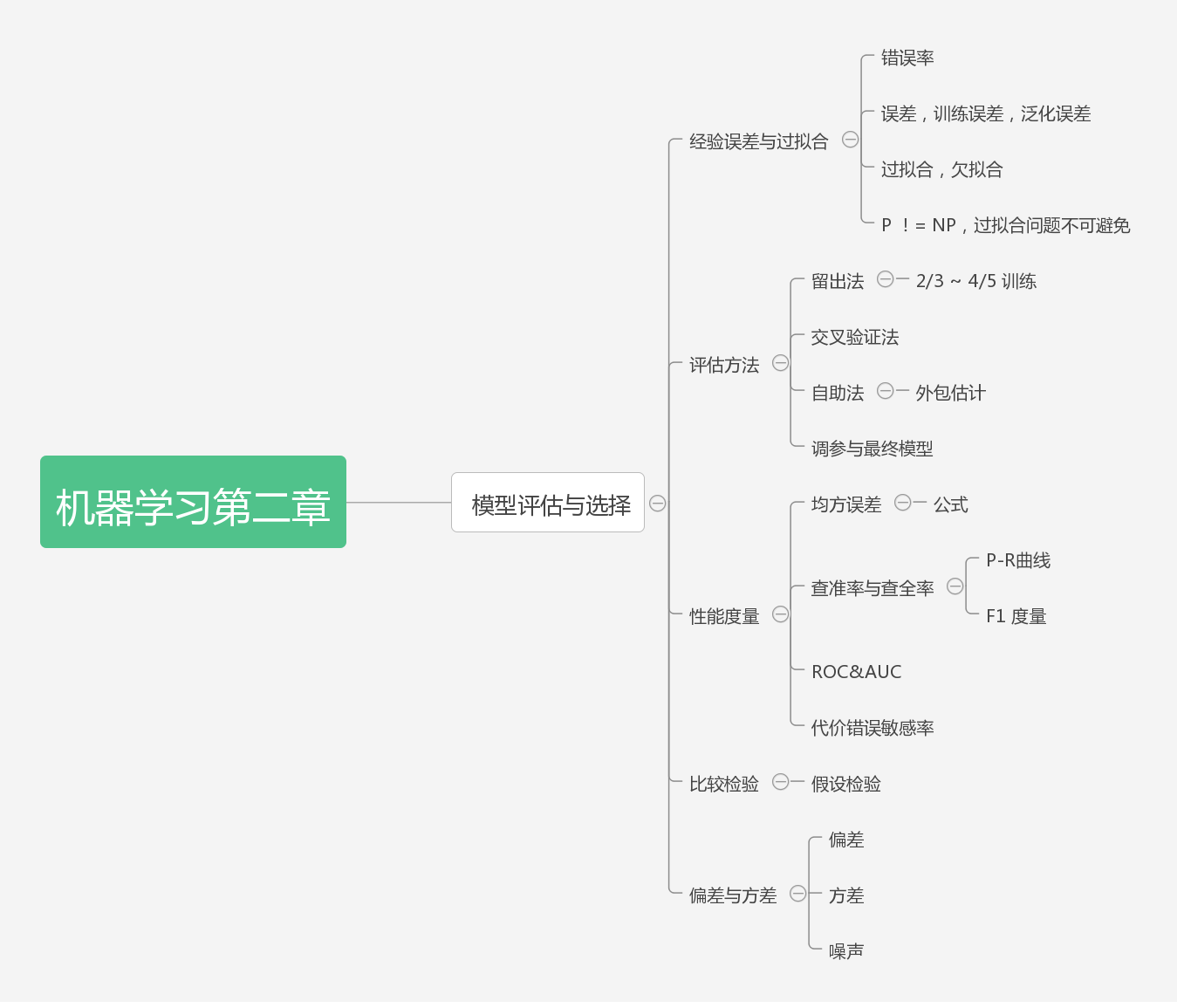
均方误差:
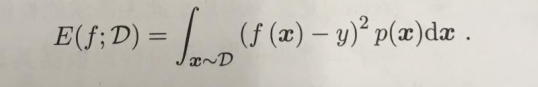
查准率与查全率:

P-R 曲线:
R曲线指的是Precision Recall曲线,翻译为中文为查准率-查全率曲线。PR曲线在分类、检索等领域有着广泛的使用,来表现分类/检索的性能。
例如,要从一个样本S中分出标签为L的样本,假设样本S中标签确实为L的集合为SL,分类器将样本标签分为L的集合为SLC,SLC中标签确实为L的集合为SLCR。那么,
查准率(Precision Ratio)= SLCR/SLC
查全率(Recall Ratio)= SLCR/SL
如果是分类器的话,通过调整分类阈值,可以得到不同的P-R值,从而可以得到一条曲线(纵坐标为P,横坐标为R)。通常随着分类阈值从大到小变化(大于阈值认为标签为L),查准率减小,查全率增加。比较两个分类器好坏时,显然是查得又准又全的比较好,也就是的PR曲线越往坐标(1,1)的位置靠近越好。
F1度量:
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。
F-Measure是Precision和Recall加权调和平均。
一般形式下的F1调和函数:
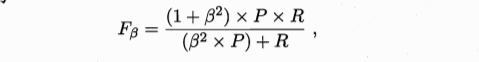
ROC 与 AUC
ROC:受试者工作特征曲线 (receiver operating characteristic curve,简称ROC曲线),又称为感受性曲线(sensitivity curve)。得此名的原因在于曲线上各点反映着相同的感受性,它们都是对同一信号刺激的反应,只不过是在几种不同的判定标准下所得的结果而已。接受者操作特性曲线就是以假阳性概率(False positive rate)为横轴,击中概率为纵轴所组成的坐标图,和被试在特定刺激条件下由于采用不同的判断标准得出的不同结果画出的曲线。
ROC曲线是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(灵敏度)为纵坐标,假阳性率(1-特异度)为横坐标绘制的曲线。传统的诊断试验评价方法有一个共同的特点,必须将试验结果分为两类,再进行统计分析。ROC曲线的评价方法与传统的评价方法不同,无须此限制,而是根据实际情况,允许有中间状态,可以把试验结果划分为多个有序分类,如正常、大致正常、可疑、大致异常和异常五个等级再进行统计分析。因此,ROC曲线评价方法适用的范围更为广泛。
AUC:
最直观的,根据AUC这个名称,我们知道,计算出ROC曲线下面的面积,就是AUC的值。事实上,这也是在早期 Machine Learning文献中常见的AUC计算方法。由于我们的测试样本是有限的。我们得到的AUC曲线必然是一个阶梯状的。因此,计算的AUC也就是这些阶梯 下面的面积之和。这样,我们先把score排序(假设score越大,此样本属于正类的概率越大),然后一边扫描就可以得到我们想要的AUC。但是,这么 做有个缺点,就是当多个测试样本的score相等的时候,我们调整一下阈值,得到的不是曲线一个阶梯往上或者往右的延展,而是斜着向上形成一个梯形。此 时,我们就需要计算这个梯形的面积。
代价错误率与代价曲线:
代价错误率:
对于不同类型的错误造成的错误所造成的后果不同,为权衡不同的类型错误所造成的不同损失,可为错误赋予“非均等代价”。
代价敏感错误率:
偏差和方差:
这里我省去推到的过程,直接得出结果:
泛华误差可分解为偏差,方差,噪声之和。
解释下定义:
偏差:度量学习算法的期望预测和真实结果的偏离程度,刻画了学习算法本身的拟合能力,方差:方差度量了同样大小训练集的变动所导致的学习性能变化,刻画了数据扰动造成了影响。
噪声:表达了当前任务上任何学习算法所能达到的期望泛化误差的下界,刻画了学习问题本身的难度。
偏差-方差分解说明了,泛化性能是有学习算法的能力,数据的充分性,以及学习任务本身的难度共同决定的,给定学习任务,为了取得好的泛化性能,则需要使偏差较小,即能够充分拟合数据,并且使数据扰动产生的影响小。