一. 链接脚本是什么?
链接脚本(Linker Script)是ld命令实现链接操作的规范性语义描述文件,使用链接命令语言(Linker Command Language)进行书写。链接脚本最主要的功能是描述如何将输入文件的节区(Sections)映射到输出文件的节区中,同时对输出文件的存储布局进行控制。另外,链接脚本中还定义了其它众多的命令,可以控制链接器完成很多高级控制和操作。
链接脚本中的输入文件和输出文件均为目标文件(Object File),其最常见的格式为ELF文件格式,每个输入文件包含一系列属性不同的输入节区(Input Section),输出文件中则包含一系列的输出节区(Output Section)。链接脚本的首要任务就是要指导链接器如何将多个输入文件中的多个输入节区映射到输出文件的输出节区中,并完成输出文件及各个节区的属性(包括存储布局、节区对齐、属性等)设置等。
二. 简单实例
链接脚本一般使用文本文件的形式进行描述,其中包含了一系列的链接命令,下面给出一个简单的、完整的链接脚本,并以该链接脚本运行ld程序,通过一个链接实例,从中观察链接脚本的作用。
1. 链接脚本实例
下面给出一个简单的链接脚本,文件名为Script:
[GCC@localhost script]$ cat Script
SECTIONS
{
. = 0x10000;
.text : { *(.text) }
. = 0x8000000;
.data : { *(.data) }
.bss : { *(.bss) }
}
该链接脚本中包含了一条SECTIONS命令,描述了输出文件中节区的存储布局(Memory Layout)。
该链接脚本的语义表明:
(1)输出的目标文件中需要包含三个节区:.text,.data及.bss,即目标文件中包含代码、已初始化的数据和未初始化的数据三个部分。
(2)赋值表达式“.= 0x10000;”表示输出文件中的.text节区的起始虚拟地址为0x10000,输出节区命令“.text : { *(.text) }”表示输出文件中的.text节区的应该由所有输入文件中的.text节区合并而成。
(3)赋值表达式“. = 0x8000000;”表示输出文件中的.data节区的起始虚拟地址为0x8000000,输出节区命令“.data : { *(.data) }”表示输出文件中的.data节区的内容应该由所有输入文件中的.data节区合并而成。
(4)输出节区命令“.bss : { *(.bss) }”表示输出文件中的.bss节区的内容应该由所有输入文件中的.bss节区合并而成,并且.bss节区的地址紧接在.data节区之后。当然,ld链接器可能会在.data节区和.bss节区之间适当进行填充,从而满足节区的对齐要求。
上述链接脚本中的点符号(.)通常称为位置计数器(Location Counter),用来描述链接过程中目标文件存储布局中的当前地址。
2. 应用链接脚本过程
假设有如下两个个目标文件,分别是add.o和sub.o,其原始的ELF节区信息分别展示如下(鉴于篇幅,命令结果显示省略了一些无关内容,下同):
add.o文件的节区信息:
[GCC@localhost script]$ readelf -S add.o
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS 00000000 000034 00000e 00 AX 0 0 4
[ 2] .data PROGBITS 00000000 000044 000004 00 WA 0 0 4
[ 3] .bss NOBITS 00000000 000048 000000 00 WA 0 0 4
[ 4] .comment PROGBITS 00000000 000048 00002e 01 MS 0 0 1
[ 5] .note.GNU-stack PROGBITS 00000000 000076 000000 00 0 0 1
[ 6] .shstrtab STRTAB 00000000 000076 000045 00 0 0 1
[ 7] .symtab SYMTAB 00000000 000224 000090 10 8 7 4
[ 8] .strtab STRTAB 00000000 0002b4 00000e 00 0 0 1sub.o文件的节区信息:
[GCC@localhost script]$ readelf -S sub.o
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS 00000000 000034 000011 00 AX 0 0 4
[ 2] .data PROGBITS 00000000 000048 000000 00 WA 0 0 4
[ 3] .bss NOBITS 00000000 000048 000000 00 WA 0 0 4
[ 4] .comment PROGBITS 00000000 000048 00002e 01 MS 0 0 1
[ 5] .note.GNU-stack PROGBITS 00000000 000076 000000 00 0 0 1
[ 6] .shstrtab STRTAB 00000000 000076 000045 00 0 0 1
[ 7] .symtab SYMTAB 00000000 000224 000090 10 8 7 4
[ 8] .strtab STRTAB 00000000 0002b4 000012 00 0 0 1下面使用ld进行链接:
./ld-new -o math.o sub.o add.o -T Script链接生成目标文件math.o,其节区信息如下:
[GCC@localhost script]$ readelf -S math.o
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS 00010000 001000 000022 00 AX 0 0 4
[ 2] .data PROGBITS 08000000 002000 000004 00 WA 0 0 4
[ 3] .bss NOBITS 08000004 002004 000004 00 WA 0 0 4
[ 4] .comment PROGBITS 00000000 002004 00002d 01 MS 0 0 1
[ 5] .symtab SYMTAB 00000000 002034 0000b0 10 6 7 4
[ 6] .strtab STRTAB 00000000 0020e4 00001f 00 0 0 1
[ 7] .shstrtab STRTAB 00000000 002103 000035 00 0 0 1可以看到,math.o的.text节区的起始地址为0x00010000,.data节区的起始地址为0x08000000,长度为4个字节,这些均是由链接脚本中的“.= 0x10000;”和“. = 0x8000000;”来指定的,.bss节区紧随其后,其起始地址为0x08000004。
另外,输入文件add.o的.text节区大小为0xe,sub.o的.text节区大小为0x11,输出目标文件math.o的.text节区大小为0x22字节,基本上等于两个输入文件中.text节区的大小之和,其相差的部分通常是由对齐填充引起的。
当然,我们也可以通过objdump查看sub.o、add.o以及math.o的内容。
[GCC@localhost script]$ objdump -d sub.o
sub.o: file format elf32-i386
Disassembly of section .text:
00000000 <sub>:
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: 8b 45 0c mov 0xc(%ebp),%eax
6: 8b 55 08 mov 0x8(%ebp),%edx
9: 89 d1 mov %edx,%ecx
b: 29 c1 sub %eax,%ecx
d: 89 c8 mov %ecx,%eax
f: 5d pop %ebp
10: c3 ret
[GCC@localhost script]$ objdump -d add.o
add.o: file format elf32-i386
Disassembly of section .text:
00000000 <add>:
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: 8b 45 0c mov 0xc(%ebp),%eax
6: 8b 55 08 mov 0x8(%ebp),%edx
9: 8d 04 02 lea (%edx,%eax,1),%eax
c: 5d pop %ebp
d: c3 ret
[GCC@localhost script]$ objdump -d math.o
math.o: file format elf32-i386
Disassembly of section .text:
00010000 <sub>:
10000: 55 push %ebp
10001: 89 e5 mov %esp,%ebp
10003: 8b 45 0c mov 0xc(%ebp),%eax
10006: 8b 55 08 mov 0x8(%ebp),%edx
10009: 89 d1 mov %edx,%ecx
1000b: 29 c1 sub %eax,%ecx
1000d: 89 c8 mov %ecx,%eax
1000f: 5d pop %ebp
10010: c3 ret
10011: 66 90 xchg %ax,%ax
10013: 90 nop
00010014 <add>:
10014: 55 push %ebp
10015: 89 e5 mov %esp,%ebp
10017: 8b 45 0c mov 0xc(%ebp),%eax
1001a: 8b 55 08 mov 0x8(%ebp),%edx
1001d: 8d 04 02 lea (%edx,%eax,1),%eax
10020: 5d pop %ebp
10021: c3 ret 从上述结果可以看出,输出文件math.o中的.text内容就是输入文件sub.o和add.o的.text内容的合并,这与链接脚本中的输出节区命令“.text : { *(.text) }”所描述的语义是完全一致的。
3. 实验讨论
(1)如果在上述链接过程中使用命令./ld-new -o math.o add.o sub.o -T Script,即交换sub.o和add.o的顺序,输出的math.o与上述的结果是否相同,说明了什么问题?
(2)试着修改链接脚本的内容,例如增加一个节区,或者修改节区的地址,重新编译,然后重复上述的分析。
三. 链接脚本中常见的链接命令
1. 设置程序入口
设置程序的入口(Entry Point)可以使用ENTRY命令,其参数为某个符号名称。
ENTRY(symbol)例如ld默认的链接脚本中通常有如下的语句:
ENTRY(_start)表示设置程序的入口地址为_start符号的地址。
通常程序的入口地址按如下的顺序进行指定:
(1)由ld的命令行选项-e entry 指定。
ld -o test -e my_entry test.c(2)由链接脚本中的ENTRY命令指定
(3)由target机器环境中默认的符号名称指定
(4)如果.text节区存在,则入口地址为.text节区的起始地址
(5)默认指定入口地址为地址0。
2. 文件目录相关命令
ld的链接脚本命令中包含了一系列的与文件/目录相关的命令,如表1所示。
| 命令格式 |
意义 |
备注 |
| INCLUDE filename |
嵌入链接脚本文件 |
在当前目录和ld选项-L所指定的目录中搜索 |
| INPUT(file, file, ...) |
指定链接的输入文件 |
|
| GROUP(file, file, ...) |
指定链接的输入归档文件 |
.a文件 |
| OUTPUT(filename) |
指定输出文件名称 |
与命令行使用-o 作用相同 |
| SEARCH_DIR(path) |
指定文件的搜索目录 |
与命令行使用选项-L作用相同 |
| STARTUP(filename) |
指定链接的第一个输入文件 |
例如,在ld默认的链接脚本中通常会有形如如下的片段:
SEARCH_DIR("/usr/local/i686-pc-linux-gnu/lib");
SEARCH_DIR("/usr/local/lib");
SEARCH_DIR("/lib");
SEARCH_DIR("/usr/lib");用来描述链接过程中库文件的搜索路径。
3. 目标文件格式定义
| 命令格式 |
意义 |
备注 |
| OUTPUT_FORMAT(bfdname) |
输出文件的格式 |
与命令行选项--oformat bfdname同义 |
| OUTPUT_FORMAT(default, big,little) |
输出文件的格式 |
与选项-EB -EL有关 |
| TARGET(bfdname) |
指定输入文件的BFD格式 |
与命令行选项-b bfdname同义 |
例如:
OUTPUT_FORMAT("elf32-i386", "elf32-i386", "elf32-i386")表示指定输出文件的格式默认为elf32-i386,如果使用链接选项-EB,则选择大端模式的输出格式elf32-i386,如果使用链接选项-EL,则选择小端模式的输出格式elf32-i386。这个例子中三个输出格式的名称是一样,当然也可以指定为不同的值。
OUTPUT_ARCH(i386)表示输出文件的BFD格式为i386机器上的ELF文件。
4. 符号及赋值
链接脚本文件中可以定义、使用符号,也可以对符号进行赋值运算,最常见的赋值操作形如:
symbol = expression ;
symbol += expression ;表示的意义等同于一般高级语言中的操作语义,例如:
__bss_start = .;表示为符号__bss_start赋值为当前位置计数器(.)的值。
表3中给出了几个比较常用的符号赋值命令。
| 命令格式 |
意义 |
| HIDDEN(symbol = expression) |
定义一个符号symbol并赋值,该符号只在本模块内可见。 |
| PROVIDE(symbol = expression) |
如果程序没有定义符号symbol,那么链接脚本定义一个符号symbol并赋值,如果程序已经定义了符号symbol,那么链接器就直接使用该符号。 |
| PROVIDE_HIDDEN(symbol = expression) |
与PROVIDE意义相同,并且本符号只在本模块内可见。 |
例 6‑1 HIDDEN命令
HIDDEN(floating_point = 0);
SECTIONS {
.text : { *(.text) HIDDEN(_etext = .); }
HIDDEN(_bdata = (. + 3) & ~ 3);
.data : { *(.data) }
}在本例中,链接脚本中定义了三个符号,分别是floating_point、_etext和 _bdata,这三个符号在本模块外是不可见的,也就是说,这3个符号只在本链接脚本中可见。
例 6‑2 PROVIDE命令
SECTIONS{
.text : {
*(.text)
_etext = .;
PROVIDE(etext = .);
}
}
在本例中,如果链接的程序中定义了符号_etext,那么链接器在链接过程中会产生一个符号重复定义的错误(multiple definition error)。但是对于由PROVIDE命令声明的符号etext,如果程序中也定义了相同的符号etext,那么链接器在链接过程中会自动地使用程序中的同名符号,而忽略链接脚本中使用PROVIDE命令声明符号etext;如果程序中没有定义符号etext,但却对符号etext进行了引用,那么链接器会自动使用链接脚本中所定义的符号etext。
5. SECTIONS命令
SECTIONS命令指导链接器如何将输入文件的节区映射到输出文件的节区中,并且对输出节区的存储布局进行控制,用来描述所有的输出节区信息。SECTIONS命令比较复杂,其格式如下:
SECTIONS
{
sections-command
sections-command
...
}可以看出,SECTIONS命令由多个sections-command组成,每个sections-command可以包括:
(1)ENTRY命令
(2)符号赋值命令
(3)节区描述命令(sections-command),用来描述一个输出section的信息
(4)覆盖描述(overlay description)
如果链接脚本中没有SECTIONS命令对输入输出节区的映射进行定义,那么链接器会按照链接过程中输入文件中的节区顺序,在目标文件中生成对应的同名节区,第一个节区的起始地址为0x0。如果链接过程中第一个输入文件的节区包含了所有的输入文件中的节区名称,那么输出文件中的节区顺序则和第一个输入文件中的节区顺序相同。
输出节区描述的语法较为复杂,主要描述了某个特定节区的各种属性,其中最主要的内容就是描述该输出节区与输入节区之间的映射关系及存储布局等。
1. 节区描述命令(sections-command)
一个完整的输出节区描述语法如下:
section_name [address] [(type)] :
[AT(lma)]
[ALIGN(section_align) | ALIGN_WITH_INPUT]
[SUBALIGN(subsection_align)]
[constraint]
{
output-section-command
output-section-command
...
} [>region] [AT>lma_region] [:phdr :phdr ...] [=fillexp] [,]该描述包括了输出节区的名称、地址、属性等,重点包括一些输出节区命令(output-section-command),用来描述某个特定的输出节区的各种属性以及该输出节区与各个输入文件中特定节区之间的映射关系。
输出节区地址描述了该输出节区的虚拟存储地址VMA (Virtual Memory Address),指定输出节区地址会改变位置计数器(dot,即链接脚本中的符号“.”)的值。
我们通过一个例子来进行说明输出节区地址的使用。
例 6‑3 输出节区地址三个不同的表示示例
.text . : { *(.text) }
.text : { *(.text) }
.text ALIGN(0x10) : { *(.text) }例子中前两个输出节区描述的差别在于,第一个例子中使用了输出节区的地址,指定输出.text字段的起始地址为当前位置计数器(.)的值;而第二个例子中,输出节区描述没有使用输出节区地址描述,那么链接器会根据所有输入.text节区的默认对齐属性对.text的起始虚拟地址进行对齐并设置。因此,这两种方式可能会导致输出节区.text的虚拟地址不同。
例子中第3个输出节区描述中使用了ALIGN(0x10)操作对当前的位置计数器进行以0x10字节大小进行对齐,并使用对齐地址作为输出节区.text的起始虚拟地址。
一个输出节区是由多个输入节区“合并”而成的,输出节区命令(output-section-command)用来描述一个输出节区的由哪些输入节区合并而成。
上述这几个概念非常相近,容易混淆,可以借助下同分析。
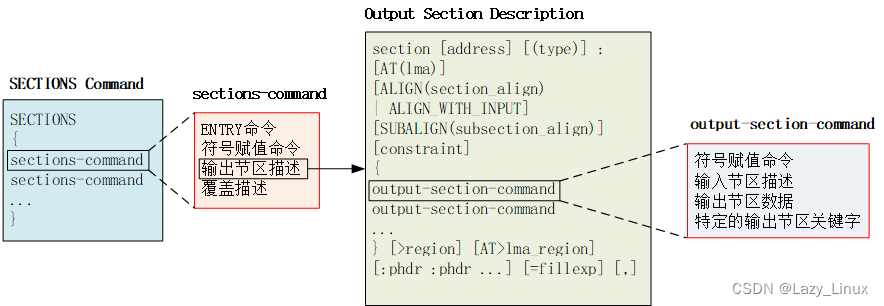
图 1. 几个术语之间的关系
2. 输出节区命令(output-section-command)
一个输出节区是由多个输入节区“合并”而成的,输出节区命令用来描述一个输出节区的由哪些输入节区合并而成,主要包括:
(1)符号赋值命令
(2)输入节区描述(Input Section Description)
(3)输出节区数据
(4)特定的输出节区关键字
下面主要介绍输入节区描述。
输入节区描述(Input Section Description)是链接脚本中最基本的操作,输出节区描述主要指导链接器如何对输出文件中的各个节区进行存储布局,而输入节区描述则指导链接器如何将多个输入文件的节区映射到这个存储布局中,即多个输入文件中的节区如何映射到某个输出节区中。
一个最基本的输入节区描述包括一个可选的文件名和一个节区名称的列表,形如:
*(.text)
其中*表示所有输入文件名,是一种使用通配符(Wildcard)的表达形式,该输入节区描述表达的意义是所有输入文件的.text节区。
下面看两个完整的输出节区描述实例。
实例6‑1 输出节区描述示例1
.rel.plt :
{
*(.rel.plt)
PROVIDE_HIDDEN (__rel_iplt_start = .);
*(.rel.iplt)
PROVIDE_HIDDEN (__rel_iplt_end = .);
}该实例描述了.rel.plt输出节区的描述,其中包含了4条命令,其中2条为输入节区描述,2条为符号赋值命令。
输入节区描述*(.rel.plt)表示所有输入文件中的.rel.plt节区都应该被映射到输出节区.rel.plt中,输入节区描述*(.rel.iplt)表示所有输入文件中的.rel.iplt节区也都应该被映射到输出节区.rel.plt中。
实例 6‑2 输出节区描述示例2
.text :
{
*(.text.unlikely .text.*_unlikely .text.unlikely.*)
*(.text.exit .text.exit.*)
*(.text.startup .text.startup.*)
*(.text.hot .text.hot.*)
*(.text .stub .text.* .gnu.linkonce.t.*)
/* .gnu.warning sections are handled specially by elf32.em. */
*(.gnu.warning)
}这个输出节区描述是ld默认链接脚本中的一部分,描述了输出节区.text的相关信息,其中包含了6个输入节区描述,这6个输入节区描述一起描述了应该将哪些输入文件的哪些输入节区映射到最终的输出节区中。
例如,*(.text.unlikely .text.*_unlikely .text.unlikely.*)输入节区描述表示将所有输入文件中的节区名称形如.text.unlikely、.text.*_unlikely .text.unlikely.*的所有节区都映射到输出节区.text中,其中的*可以代表输入文件名和节区名称中任意的字符串。
四. 实际的链接脚本片段分析
本节我们从ld默认的链接脚本中选取部分内容进行分析。可以使用ld -verbose显示当前使用的默认链接脚本内容。
[root@localhost ~]# ld -verbose
GNU ld version 2.20.51.0.2-5.48.el6_10.1 20100205
Supported emulations:
elf_i386
i386linux
elf_x86_64
elf_l1om
using internal linker script:
==================================================
/* Script for -z combreloc: combine and sort reloc sections */
OUTPUT_FORMAT("elf32-i386", "elf32-i386",
"elf32-i386")
OUTPUT_ARCH(i386)
ENTRY(_start)
SEARCH_DIR("/usr/i686-redhat-linux/lib"); SEARCH_DIR("/usr/local/lib"); SEARCH_DIR("/lib"); SEARCH_DIR("/usr/lib");
SECTIONS
{
/* Read-only sections, merged into text segment: */
PROVIDE (__executable_start = SEGMENT_START("text-segment", 0x08048000)); . = SEGMENT_START("text-segment", 0x08048000) + SIZEOF_HEADERS;
.interp : { *(.interp) }
.note.gnu.build-id : { *(.note.gnu.build-id) }
.hash : { *(.hash) }
.gnu.hash : { *(.gnu.hash) }
.dynsym : { *(.dynsym) }
.dynstr : { *(.dynstr) }
.gnu.version : { *(.gnu.version) }
.gnu.version_d : { *(.gnu.version_d) }
.gnu.version_r : { *(.gnu.version_r) }
.rel.dyn :
{
*(.rel.init)
*(.rel.text .rel.text.* .rel.gnu.linkonce.t.*)
*(.rel.fini)
*(.rel.rodata .rel.rodata.* .rel.gnu.linkonce.r.*)
*(.rel.data.rel.ro* .rel.gnu.linkonce.d.rel.ro.*)
*(.rel.data .rel.data.* .rel.gnu.linkonce.d.*)
*(.rel.tdata .rel.tdata.* .rel.gnu.linkonce.td.*)
*(.rel.tbss .rel.tbss.* .rel.gnu.linkonce.tb.*)
*(.rel.ctors)
*(.rel.dtors)
*(.rel.got)
*(.rel.sharable_data .rel.sharable_data.* .rel.gnu.linkonce.shrd.*)
*(.rel.sharable_bss .rel.sharable_bss.* .rel.gnu.linkonce.shrb.*)
*(.rel.bss .rel.bss.* .rel.gnu.linkonce.b.*)
*(.rel.ifunc)
}
.rel.plt :
{
*(.rel.plt)
PROVIDE_HIDDEN (__rel_iplt_start = .);
*(.rel.iplt)
PROVIDE_HIDDEN (__rel_iplt_end = .);
}
.init :
{
KEEP (*(.init))
} =0x90909090
.plt : { *(.plt) *(.iplt) }
.text :
{
*(.text.unlikely .text.*_unlikely)
*(.text .stub .text.* .gnu.linkonce.t.*)
/* .gnu.warning sections are handled specially by elf32.em. */
*(.gnu.warning)
} =0x90909090
.fini :
{
KEEP (*(.fini))
} =0x90909090
PROVIDE (__etext = .);
PROVIDE (_etext = .);
PROVIDE (etext = .);
.rodata : { *(.rodata .rodata.* .gnu.linkonce.r.*) }
.rodata1 : { *(.rodata1) }
.eh_frame_hdr : { *(.eh_frame_hdr) }
.eh_frame : ONLY_IF_RO { KEEP (*(.eh_frame)) }
.gcc_except_table : ONLY_IF_RO { *(.gcc_except_table .gcc_except_table.*) }
/* Adjust the address for the data segment. We want to adjust up to
the same address within the page on the next page up. */
. = ALIGN (CONSTANT (MAXPAGESIZE)) - ((CONSTANT (MAXPAGESIZE) - .) & (CONSTANT (MAXPAGESIZE) - 1)); . = DATA_SEGMENT_ALIGN (CONSTANT (MAXPAGESIZE), CONSTANT (COMMONPAGESIZE));
/* Exception handling */
.eh_frame : ONLY_IF_RW { KEEP (*(.eh_frame)) }
.gcc_except_table : ONLY_IF_RW { *(.gcc_except_table .gcc_except_table.*) }
/* Thread Local Storage sections */
.tdata : { *(.tdata .tdata.* .gnu.linkonce.td.*) }
.tbss : { *(.tbss .tbss.* .gnu.linkonce.tb.*) *(.tcommon) }
.preinit_array :
{
PROVIDE_HIDDEN (__preinit_array_start = .);
KEEP (*(.preinit_array))
PROVIDE_HIDDEN (__preinit_array_end = .);
}
.init_array :
{
PROVIDE_HIDDEN (__init_array_start = .);
KEEP (*(SORT(.init_array.*)))
KEEP (*(.init_array))
PROVIDE_HIDDEN (__init_array_end = .);
}
.fini_array :
{
PROVIDE_HIDDEN (__fini_array_start = .);
KEEP (*(.fini_array))
KEEP (*(SORT(.fini_array.*)))
PROVIDE_HIDDEN (__fini_array_end = .);
}
.ctors :
{
/* gcc uses crtbegin.o to find the start of
the constructors, so we make sure it is
first. Because this is a wildcard, it
doesn't matter if the user does not
actually link against crtbegin.o; the
linker won't look for a file to match a
wildcard. The wildcard also means that it
doesn't matter which directory crtbegin.o
is in. */
KEEP (*crtbegin.o(.ctors))
KEEP (*crtbegin?.o(.ctors))
/* We don't want to include the .ctor section from
the crtend.o file until after the sorted ctors.
The .ctor section from the crtend file contains the
end of ctors marker and it must be last */
KEEP (*(EXCLUDE_FILE (*crtend.o *crtend?.o ) .ctors))
KEEP (*(SORT(.ctors.*)))
KEEP (*(.ctors))
}
.dtors :
{
KEEP (*crtbegin.o(.dtors))
KEEP (*crtbegin?.o(.dtors))
KEEP (*(EXCLUDE_FILE (*crtend.o *crtend?.o ) .dtors))
KEEP (*(SORT(.dtors.*)))
KEEP (*(.dtors))
}
.jcr : { KEEP (*(.jcr)) }
.data.rel.ro : { *(.data.rel.ro.local* .gnu.linkonce.d.rel.ro.local.*) *(.data.rel.ro* .gnu.linkonce.d.rel.ro.*) }
.dynamic : { *(.dynamic) }
.got : { *(.got) *(.igot) }
. = DATA_SEGMENT_RELRO_END (12, .);
.got.plt : { *(.got.plt) *(.igot.plt) }
.data :
{
*(.data .data.* .gnu.linkonce.d.*)
SORT(CONSTRUCTORS)
}
.data1 : { *(.data1) }
/* Sharable data sections. */
.sharable_data : ALIGN(CONSTANT (MAXPAGESIZE))
{
PROVIDE_HIDDEN (__sharable_data_start = .);
*(.sharable_data .sharable_data.* .gnu.linkonce.shrd.*)
/* Align here to ensure that the sharable data section ends at the
page boundary. */
. = ALIGN(. != 0 ? CONSTANT (MAXPAGESIZE) : 1);
PROVIDE_HIDDEN (__sharable_data_end = .);
}
_edata = .; PROVIDE (edata = .);
__bss_start = .;
.bss :
{
*(.dynbss)
*(.bss .bss.* .gnu.linkonce.b.*)
*(COMMON)
/* Align here to ensure that the .bss section occupies space up to
_end. Align after .bss to ensure correct alignment even if the
.bss section disappears because there are no input sections.
FIXME: Why do we need it? When there is no .bss section, we don't
pad the .data section. */
. = ALIGN(. != 0 ? 32 / 8 : 1);
}
/* Sharable bss sections */
.sharable_bss : ALIGN(CONSTANT (MAXPAGESIZE))
{
PROVIDE_HIDDEN (__sharable_bss_start = .);
*(.dynsharablebss)
*(.sharable_bss .sharable_bss.* .gnu.linkonce.shrb.*)
*(SHARABLE_COMMON)
/* Align here to ensure that the sharable bss section ends at the
page boundary. */
. = ALIGN(. != 0 ? CONSTANT (MAXPAGESIZE) : 1);
PROVIDE_HIDDEN (__sharable_bss_end = .);
}
. = ALIGN(32 / 8);
. = ALIGN(32 / 8);
_end = .; PROVIDE (end = .);
. = DATA_SEGMENT_END (.);
/* Stabs debugging sections. */
.stab 0 : { *(.stab) }
.stabstr 0 : { *(.stabstr) }
.stab.excl 0 : { *(.stab.excl) }
.stab.exclstr 0 : { *(.stab.exclstr) }
.stab.index 0 : { *(.stab.index) }
.stab.indexstr 0 : { *(.stab.indexstr) }
.comment 0 : { *(.comment) }
/* DWARF debug sections.
Symbols in the DWARF debugging sections are relative to the beginning
of the section so we begin them at 0. */
/* DWARF 1 */
.debug 0 : { *(.debug) }
.line 0 : { *(.line) }
/* GNU DWARF 1 extensions */
.debug_srcinfo 0 : { *(.debug_srcinfo) }
.debug_sfnames 0 : { *(.debug_sfnames) }
/* DWARF 1.1 and DWARF 2 */
.debug_aranges 0 : { *(.debug_aranges) }
.debug_pubnames 0 : { *(.debug_pubnames) }
/* DWARF 2 */
.debug_info 0 : { *(.debug_info .gnu.linkonce.wi.*) }
.debug_abbrev 0 : { *(.debug_abbrev) }
.debug_line 0 : { *(.debug_line) }
.debug_frame 0 : { *(.debug_frame) }
.debug_str 0 : { *(.debug_str) }
.debug_loc 0 : { *(.debug_loc) }
.debug_macinfo 0 : { *(.debug_macinfo) }
/* SGI/MIPS DWARF 2 extensions */
.debug_weaknames 0 : { *(.debug_weaknames) }
.debug_funcnames 0 : { *(.debug_funcnames) }
.debug_typenames 0 : { *(.debug_typenames) }
.debug_varnames 0 : { *(.debug_varnames) }
/* DWARF 3 */
.debug_pubtypes 0 : { *(.debug_pubtypes) }
.debug_ranges 0 : { *(.debug_ranges) }
.gnu.attributes 0 : { KEEP (*(.gnu.attributes)) }
/DISCARD/ : { *(.note.GNU-stack) *(.gnu_debuglink) *(.gnu.lto_*) }
}
==================================================

图 2. ld默认链接脚本实例部分内容分析
上图不再赘述,可以根据前述内容自行分析。
参考文献
[1] GNU ld 手册