文章目录
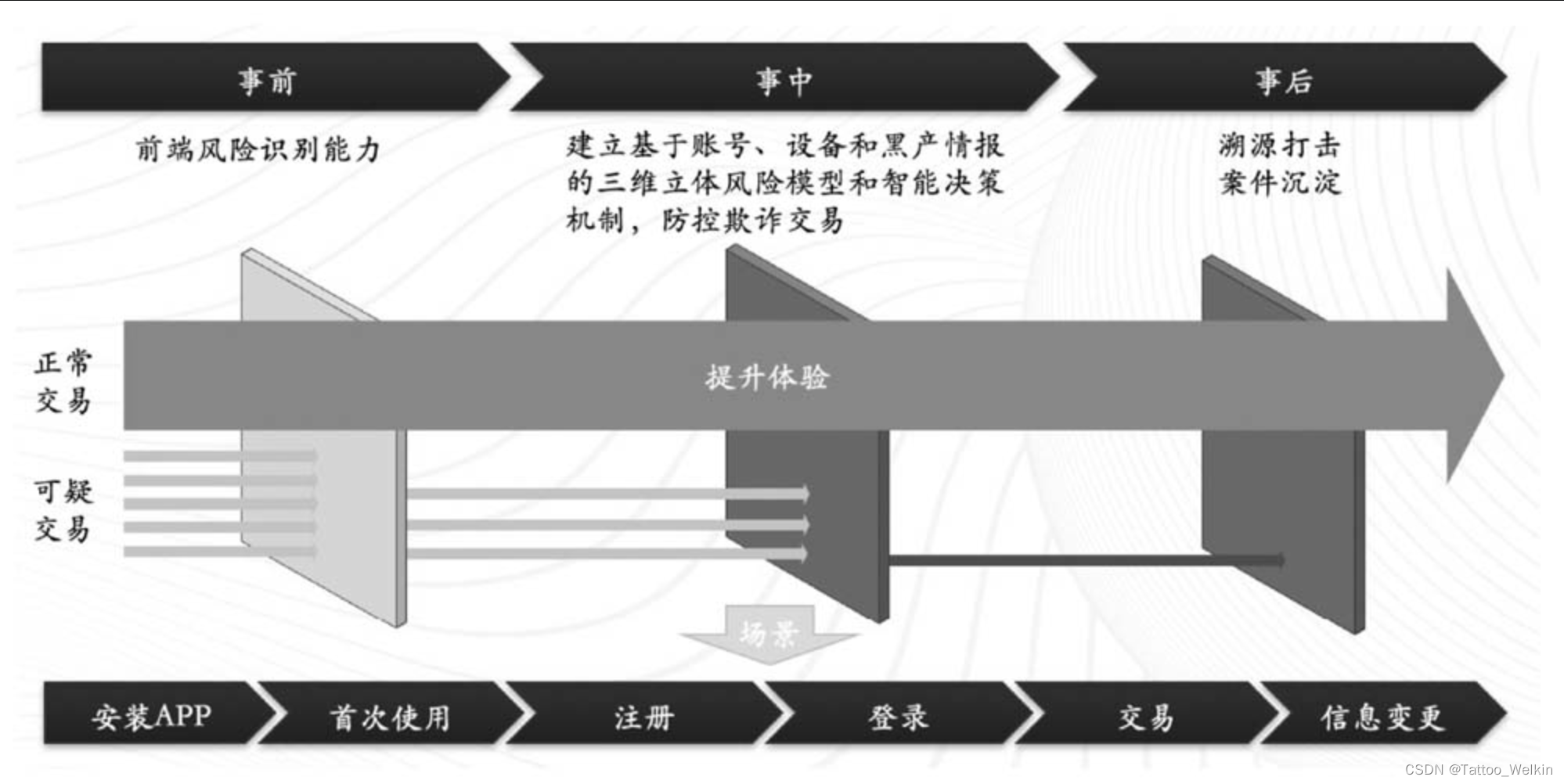
动态防控理念
生物探针
通过采集终端的操作行为、传感器信息等数据综合建模,通过机器学习区分出操作业务的是自然人还是自动化工具。
智能验证码
一种常见的风控工具,本质上也是区分操作业务的是否为自然人。
生物探针和智能验证码的区别:
前者适用于全业务场景检测是否是机器,后者适用于特定场景对抗机器批量行为,需要用户进行拖动、点击等交互操作
风险态势感知系统
风险态势感知系统侧重于宏观的统计分析,利用业务核心数据、设备信息及风险决策结果等各类数据,通过预置的分析算法模型进行实时、H+1、T+1多种周期组合的分析计算。其核心功能是感知、展示和预测整个业务体系的风险事件变化趋势。当风险决策结果发生非预期的波动时,运营人员就必须人工分析策略漏杀、误杀的情况。运营人员结合数据分析和底层的机器学习的离线计算结果更新风控模型,实时调整决策引擎的风险策略。在推动优化风险策略的同时,风险态势感知系统还可以对黑产攻击事件做预警。
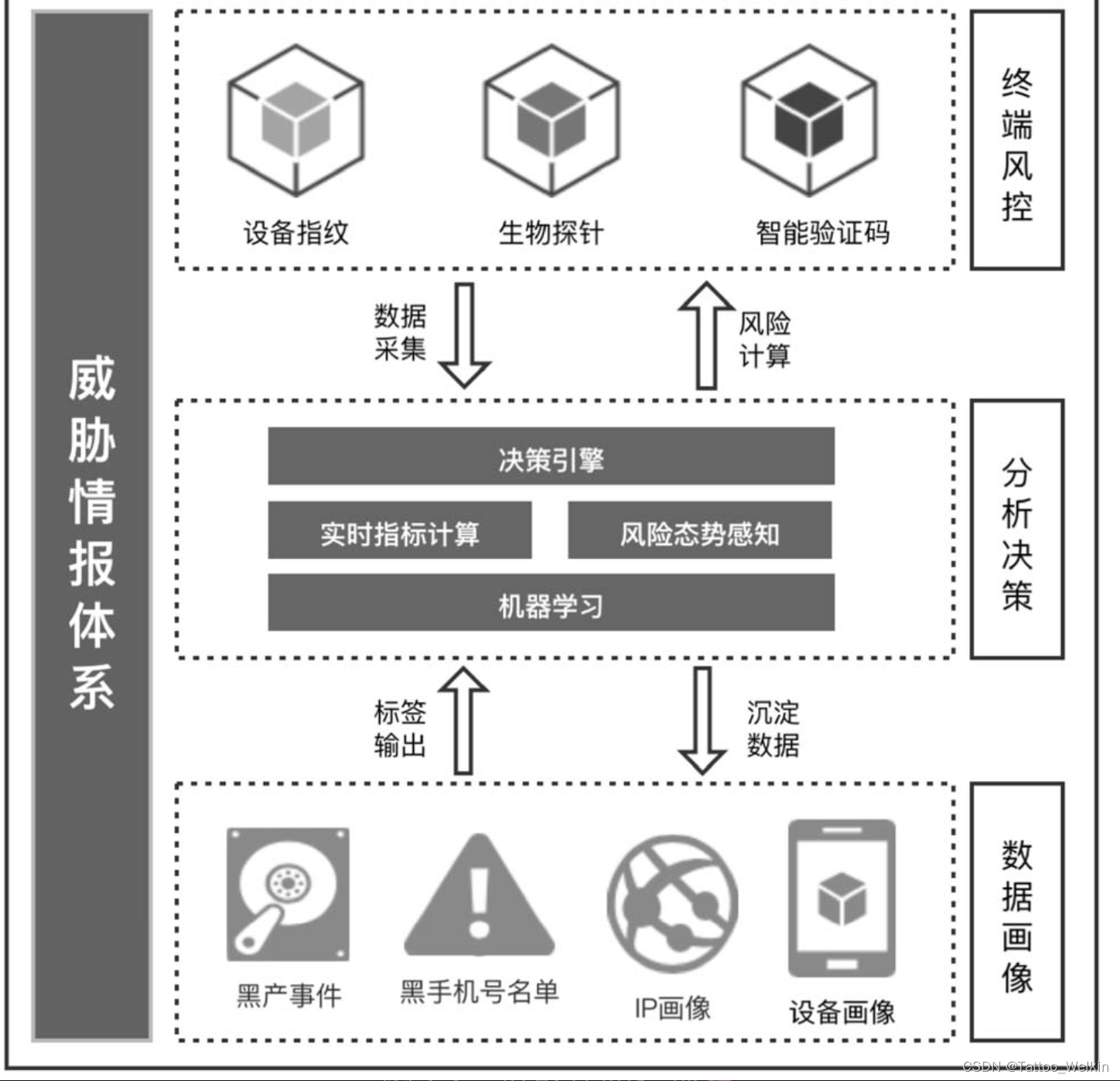
风控核心组件设备指纹
设备指纹的原理
采集一些字段生成一个设备ID(设备ID 需要兼具稳定性和唯一性)
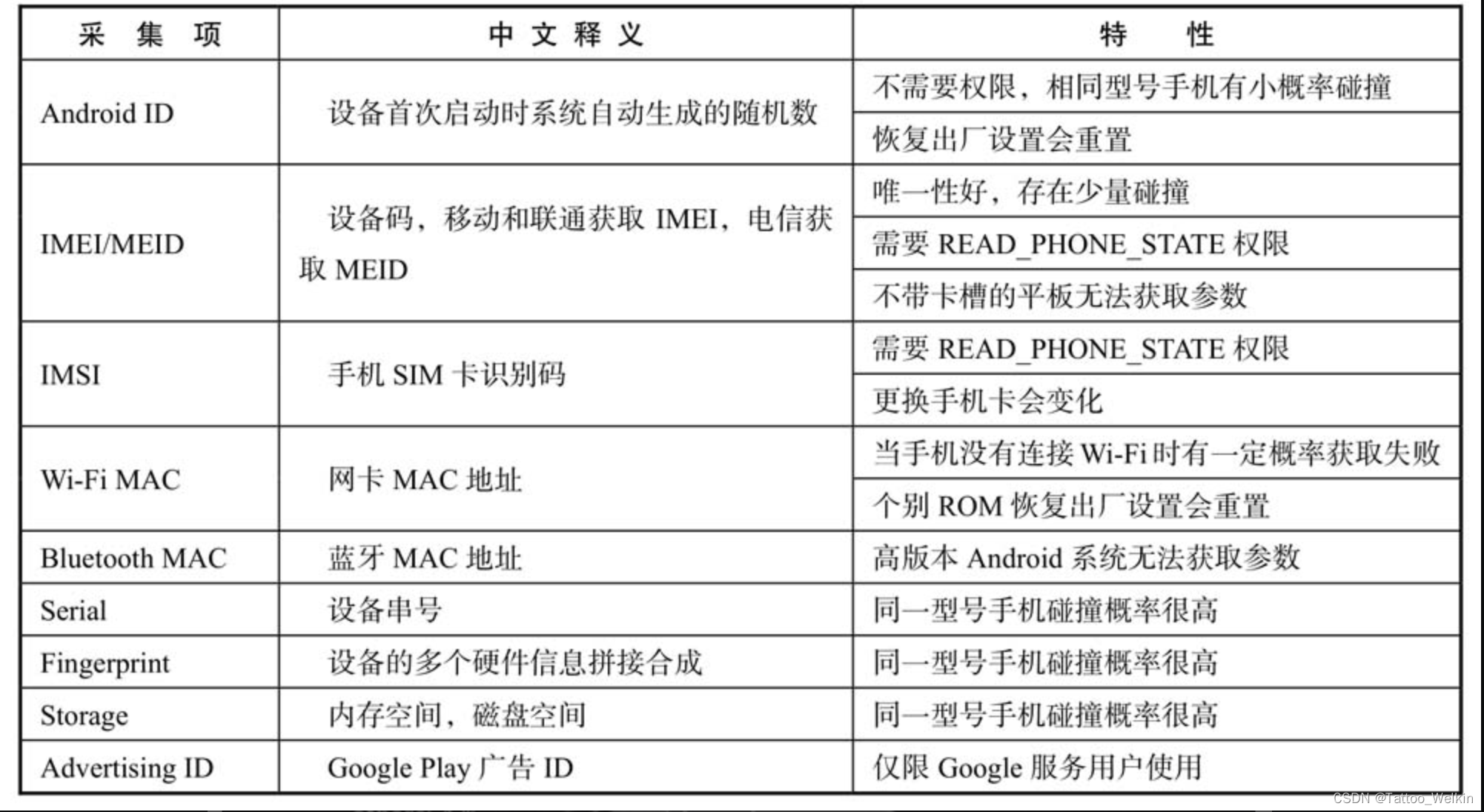
Android 设备指纹
设备ID 需要兼具稳定性和唯一性,Android 系统的开源和碎片化导致API 函数实现各不相同,所以兼容性是Android 系统中设备指纹面临的最大挑战。表4.1列举了Android 系统中比较稳定的设备参数。
iOS 设备指纹

Web 设备指纹
Web 设备指纹(又被称为浏览器指纹)是由用户设备硬件信息和浏览器配置信息综合计算产生的,它通过 JavaScript 脚本采集信息生成对应的设备ID。
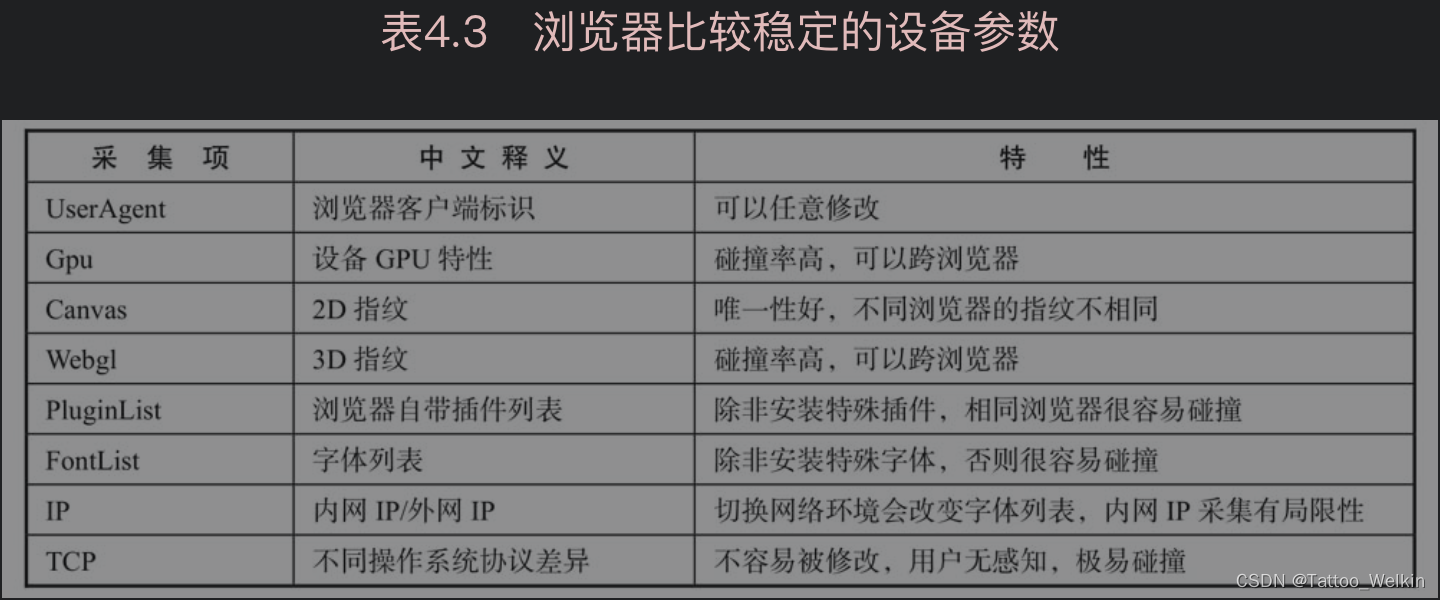
Web 设备指纹的实现过程主要分为两部分:
- 其一为设备指纹的稳定性,即需要收集较为稳定的设备信息;
- 其二是作弊环境检测,即 保证当前 Web 设备指纹采集到的信息都是真实的。下面具体说明 Web 设备指纹中的一些异常检测原理。
具体见书
设备ID 生成与恢复逻辑
生成逻辑
设备指纹SDK 采集终端设备信息完成后,会计算生成一个唯一ID 来标识设备,如图4.3所示为设备ID 生成逻辑示意图。
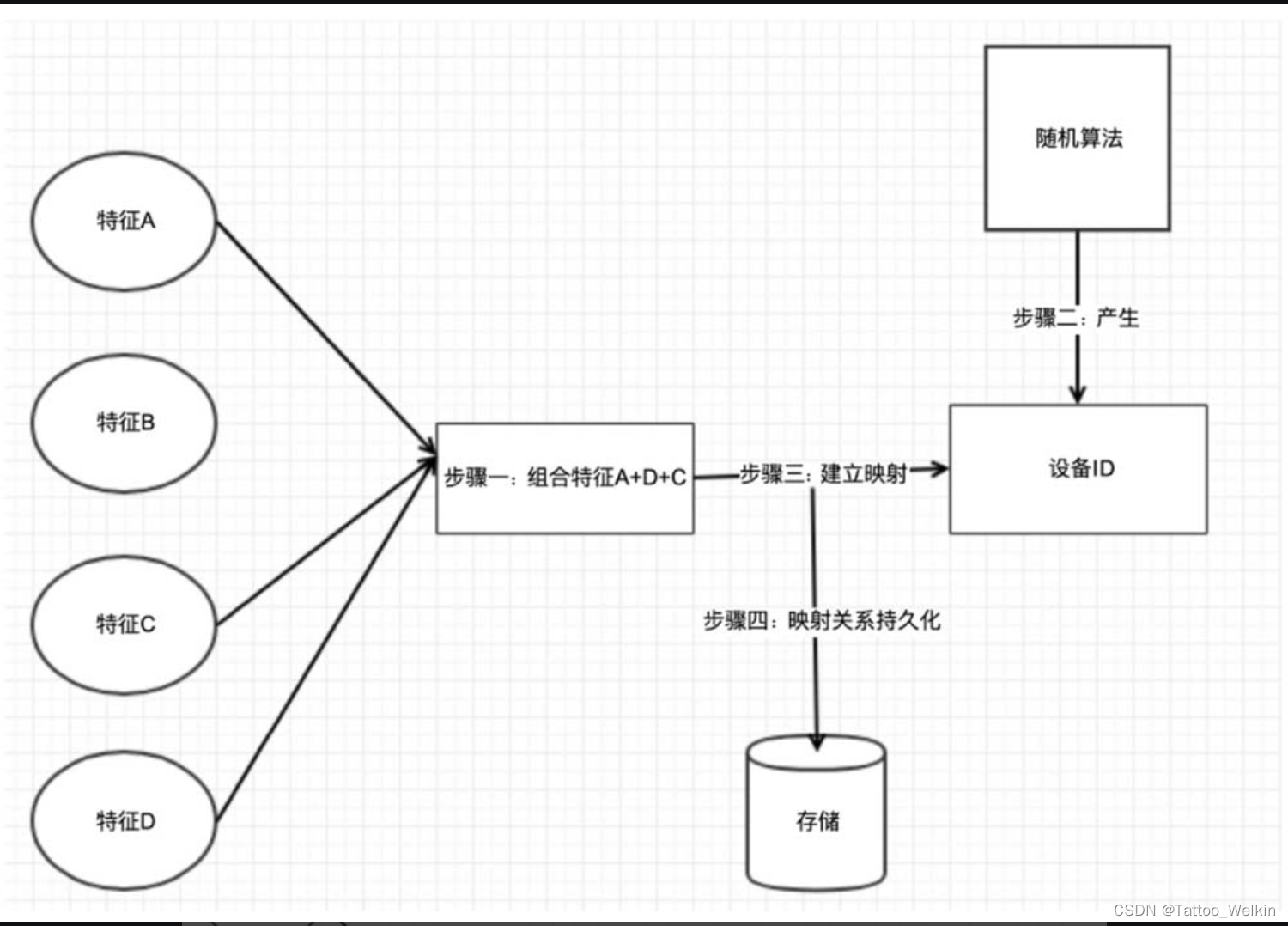
需要注意的是,设备ID 是在后端生成的。从前端的角度考虑,无论采用多强的加固和混淆,都能够逆向还原代码。如果由前端生成设备ID,那么只要逆向出相关逻辑就能批量生成合法的设备ID。同理,如果 将设备ID 直接返回前端,在前端做风控策略,就很容易被绕过。此外,特征与设备ID的关系是多对一的映射,特征会碰撞但设备ID 必须满足唯一。
上述的没太看明白~
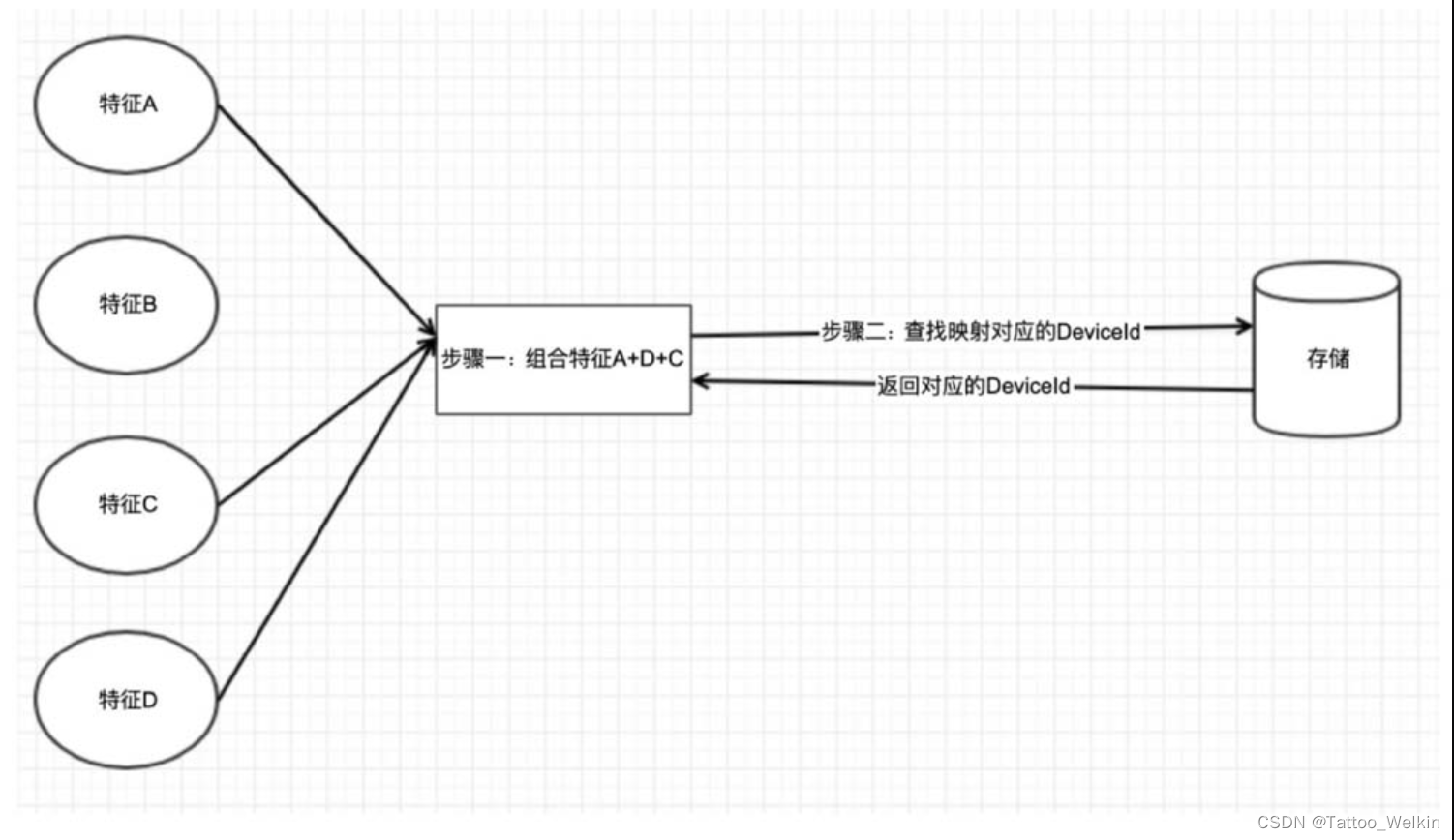
恢复逻辑
设备ID 恢复逻辑,就是从采集到的设备信息中筛选特征组合。如果新采集的设备特征与数据库中已有的设备特征相同或相似,就认为新采集的设备是同一台设备,赋予相同的设备ID。如果没有查找到相似的设备,就认为是一台新设备,生成新的设备ID。(key 是特征的组合,value 是对应的设备 ID)
恢复逻辑需要权衡稳定性和唯一性。唯一性和稳定性是一个权衡的过程,一个高另外一个就低。稳定性表示设备经过改机或恢复出厂设置以后还能保证设备ID 不变。唯一性表示不同设备,尤其是同一型号的设备ID 不一致。如图4.4所示为设备ID 恢复逻辑示意图。
代码保护
终端风控使用的SDK 受限于其工作原理,必须嵌入业务的APP 应用或H5页面中,直接暴露在黑产眼前。黑产团伙中的技术人员通过逆向分析和修改SDK 采集的设备信息字段试探云端的防控策略,也可以制作工具针对性地伪造大量的虚假设备用于后续攻击活动。因此,风控技术人员需要对SDK 进行安全加固保护,保护其核心代码逻辑,提升黑产逆向分析的技术难度和消耗的时间成本。
从SDK 代码保护的防护效果来看,Android 相对防护效果较好,iOS 次之,而 JS 的防护效果较差。
那么对于代码保护的手段都有哪些呐?
JS 代码混淆技术
代码混淆(obfuscation)是增加黑产静态分析难度而牺牲运行效率的一种技术方案。JS代码混淆是指通过逻辑变换算法等技术手段将受保护的代码转化为难以分析的等价代码的一种技术方案。“难以分析”是混淆的目的,“等价代码”则是要确保混淆后的代码与源代码功能表现保持一致。通俗来说,混淆代码P 就是把P 转换为P’,使P’的行为与P 的行为一致,但是攻击者却很难从P’中分析获取信息。
分为四种:
- 布局混淆(layoutobfuscation)
- 数据混淆(data obfuscation)
- 控制混淆(controlobfuscation)
- 预防混淆(preventive obfuscation)
具体原理略。
Android/iOS SDK 加固保护
- 变量名与函数名混淆(ProGuard:使用简短的无意义的名称来重命名已经存在的类、字段、方法和属性)
- 字符串混淆
- Dex 加固与抽取
- LLVM:LLVM 是Low Level Virtual Machine 的缩写,其定位是一个比较底层的虚拟机。然而 LLVM 本身并不是一个完整的编译器,LLVM 是一个编译器基础架构,把很多编译器需要的功能以可调用的模块形式实现出来并包装成库,其他编译器实现者可以根据自己的需要使用或扩展,主要聚焦于编译器后端功能,如代码生成、代码优化、JIT 等。