文章目录
Kafka 为什么分区?
为什么 Kafka 要做这样的设计?为什么使用分区的概念而不是直接使用多个主题呢?
原因
- 其实分区的作用就是提供
负载均衡的能力,或者说对数据进行分区的主要原因,就是为了实现系统的高伸缩性(Scalability)。不同的分区能够被放置到不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的,这样每个节点的机器都能独立地执行各自分区的读写请求处理。并且,我们还可以通过添加新的节点机器来增加整体系统的吞吐量。 - 除了提供负载均衡这种最核心的功能之外,利用分区也可以实现其他一些业务级别的需求,比如实现业务级别的消息顺序的问题。
Kafka 为什么规定一个partition 只能被一个消费者消费?
 假设1个 partition 能够被同组的多个 consumer 消费,因为 consumer 是通过 pull 的模式从partition拉取消息的,pull的时候就要决定从哪里 pull,也就是 index 的值,不做中心化维护index的值的话,consumer就很容易pull到重复的消息重复消费,对index做中心化处理的话,就会增加通信成本,consumer每次pull的时候还得通信获取最新的index的值,再加上consumer消费失败,不commit成功的话,index的值维护起来就会异常复杂。整体上利大于弊呐,于是就1个partition只能被同组的一个consumer,如果需要多个consumer,就分多个partition
假设1个 partition 能够被同组的多个 consumer 消费,因为 consumer 是通过 pull 的模式从partition拉取消息的,pull的时候就要决定从哪里 pull,也就是 index 的值,不做中心化维护index的值的话,consumer就很容易pull到重复的消息重复消费,对index做中心化处理的话,就会增加通信成本,consumer每次pull的时候还得通信获取最新的index的值,再加上consumer消费失败,不commit成功的话,index的值维护起来就会异常复杂。整体上利大于弊呐,于是就1个partition只能被同组的一个consumer,如果需要多个consumer,就分多个partition
为什么 Kafka 的 broker 上 topic 越多效率越慢?
因为当分区数激增的时候,Kafka 的顺序写入特性会被大大破坏从而引入大量的随机I/O,因此吞吐量会下降
kafka中的 AR、ISR、LEO、HW 分别是什么
-
LEO:Log End Offset。
日志末端位移值或末端偏移量,表示日志下一条待插入消息的位移值。举个例子,如果日志有 10 条消息,位移值从 0 开始,那么,第 10 条消息的位移值就是 9。此时,LEO = 10。本质上应该是 offset +1 -
LSO:Log Stable Offset。这是 Kafka 事务的概念。如果你没有使用到事务,那么这个值不存在(其实也不是不存在,只是设置成一个无意义的值)。
该值控制了事务型消费者能够看到的消息范围。 -
AR:Assigned Replicas。AR 是主题被创建后,分区创建时被分配的
副本集合,副本个数由副本因子决定。 -
ISR:In-Sync Replicas。Kafka 中
特别重要的概念,指代的是AR 中那些与 Leader 保持同步的副本集合。在 AR 中的副本可能不在 ISR 中,但Leader 副本天然就包含在 ISR 中。关于 ISR,还有一个常见的面试题目是如何判断副本是否应该属于 ISR。目前的判断依据是:Broker 端参数 replica.lag.time.max.ms 参数值。这个参数的含义是 Follower 副本能够落后 Leader 副本的最长时间间隔,当前默认值是 10 秒。这就是说,只要一个 Follower 副本落后 Leader 副本的时间不连续超过 10 秒,就认定是同步的。 -
HW:高水位值(High watermark)。这是
控制消费者可读取消息范围的重要字段。一个普通消费者只能“看到”Leader 副本上介于 Log Start Offset 和 HW(不含)之间的所有消息。水位以上的消息是对消费者不可见的。
阐述下 Kafka 中的领导者副本(Leader Replica)和追随者副本(Follower Replica)的区别
首先声明一下,所谓的领导者副本其实就是 主副本。
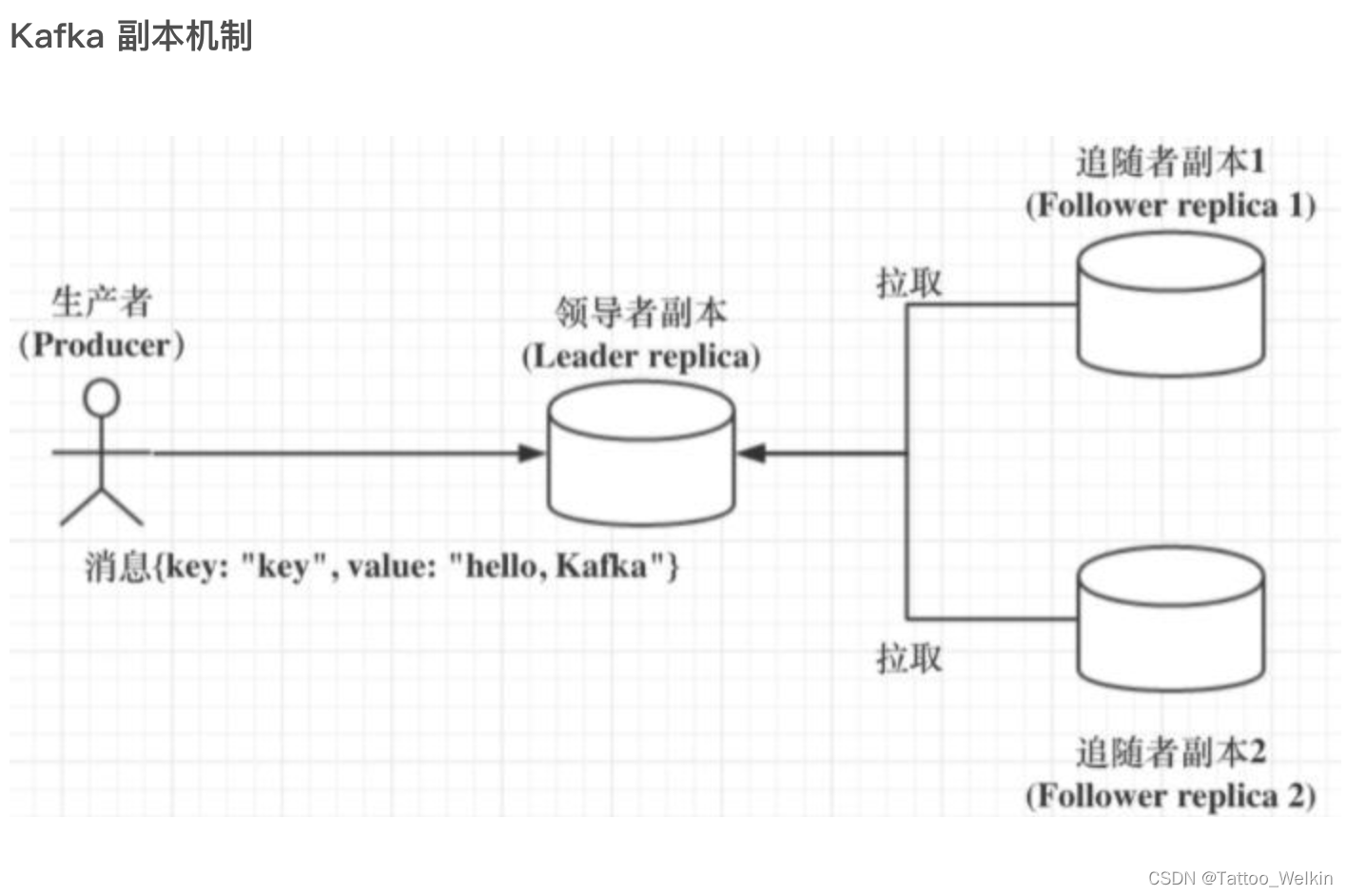
Kafka 副本当前分为领导者副本和追随者副本。只有 Leader 副本才能对外提供读写服务,响应 Clients 端的请求。
Follower 副本只是采用拉(PULL)的方式,被动地同步 Leader 副本中的数据,并且在 Leader 副本所在的 Broker 宕机后,随时准备应聘 Leader 副本。
自 Kafka 2.4 版本开始,社区通过引入新的 Broker 端参数,允许 Follower 副本有限度地提供读服务。
问题一:kafka 的副本为什么之前不提供读服务?
-
因为副本的数据可能并不会那么及时,所以会导致出现幻读,脏读情况。如果提供就属于 AP。如果不提供,就属于 CP。那么 kafka 为什么选择 CP 而不是 AP 呐?
-
场景不适用。
读写分离适用于那种读负载很大,而写操作相对不频繁的场景,可 Kafka 不属于这样的场景。 -
同步机制。Kafka 采用 PULL 方式实现 Follower 的同步,因此,Follower 与 Leader 存在不一致性窗口。如果允许读 Follower 副本,就势必要处理消息滞后(Lagging)的问题。
Kafka follower副本为什么不对外提供服务
轻松理解CAP理论
__consumer_offsets 是做什么用的 ?
- 它是一个内部主题,无需手动干预,由 Kafka 自行管理。当然,我们可以创建该主题。
- 它的主要作用是
负责注册消费者以及保存位移值。可能你对保存位移值的功能很熟悉,但其实该主题也是保存消费者元数据的地方。千万记得把这一点也回答上。另外,这里的消费者泛指消费者组和独立消费者,而不仅仅是消费者组 - Kafka 的
GroupCoordinator组件提供对该主题完整的管理功能,包括该主题的创建、写入、读取和 Leader 维护等。
前世
老版本 Consumer 的位移管理是依托于 Apache ZooKeeper 的,它会自动或手动地将位移数据提交到 ZooKeeper 中保存。当 Consumer 重启后,它能自动从 ZooKeeper 中读取位移数据,从而在上次消费截止的地方继续消费。这种设计使得 Kafka Broker 不需要保存位移数据,减少了 Broker 端需要持有的状态空间,因而有利于实现高伸缩性。
ZK 并不适用于高频写操作,所以就需要将其去掉。
于是直接就是将 Consumer 的位移数据作为一条条普通的 Kafka 消息,提交到 __consumer_offsets 中。可以这么说,__consumer_offsets 的主要作用是保存 Kafka 消费者的位移信息。它要求这个提交过程不仅要实现高持久性,还要支持高频的写操作。显然,Kafka 的主题设计天然就满足这两个条件,因此,使用 Kafka 主题来保存位移这件事情,实际上就是一个水到渠成的想法了。
- 有特定的消息格式,不要往该主题发送消息
消息格式
- 消息格式是:位移主题的 Key 中应该保存 3 部分内容:<Group ID,主题名,分区号 >,Value 就是 位移值
- 用于删除 Group 过期位移甚至是删除 Group 的消息
位移主题是怎么被创建的
- 当 Kafka 集群中的第一个 Consumer 程序启动时,Kafka 会自动创建位移主题。
- 分区数是怎么制定的呐?看 Broker 端参数 offsets.topic.num.partitions 的取值了。它的默认值是 50,因此 Kafka 会自动创建一个 50 分区的位移主题。如果你曾经惊讶于 Kafka 日志路径下冒出很多 __consumer_offsets-xxx 这样的目录,那么现在应该明白了吧,这就是 Kafka 自动帮你创建的位移主题啊
- 副本数或备份因子是怎么确定的呐?Broker 端另一个参数 offsets.topic.replication.factor 要做的事情了。它的默认值是 3。
那 Consumer 是怎么提交位移的呢?目前 Kafka Consumer 提交位移的方式有两种:自动提交位移和手动提交位移
- Consumer 端有个参数叫 enable.auto.commit
Kafka 是怎么删除位移主题中的过期消息的呢?–Compaction
假设 Consumer 当前消费到了某个主题的最新一条消息,位移是 100,之后该主题没有任何新消息产生,故 Consumer 无消息可消费了,所以位移永远保持在 100。由于是自动提交位移,位移主题中会不停地写入位移 =100 的消息。显然 Kafka 只需要保留这类消息中的最新一条就可以了,之前的消息都是可以删除的。这就要求 Kafka 必须要有针对位移主题消息特点的消息删除策略,否则这种消息会越来越多,最终撑爆整个磁盘。
干,其实就是比较时间戳,保留最新的 K-V 数据。
Kafka 提供了专门的后台线程定期地巡检待 Compact 的主题,看看是否存在满足条件的可删除数据。这个后台线程叫 Log Cleaner。很多实际生产环境中都出现过位移主题无限膨胀占用过多磁盘空间的问题,如果你的环境中也有这个问题,我建议你去检查一下 Log Cleaner 线程的状态,通常都是这个线程挂掉了导致的。
请求是怎么被处理的?
Reactor 模式
高性能服务器程序框架-I/O处理单元之两大高效的事件处理模式


当网络线程拿到请求后,它不是自己处理,而是将请求放入到一个共享请求队列中。Broker 端还有个 IO 线程池,负责从该队列中取出请求,执行真正的处理。如果是 PRODUCE 生产请求,则将消息写入到底层的磁盘日志中;如果是 FETCH 请求,则从磁盘或页缓存中读取消息。
IO 线程池处中的线程才是执行请求逻辑的线程。Broker 端参数 num.io.threads 控制了这个线程池中的线程数。目前该参数默认值是 8,表示每台 Broker 启动后自动创建 8 个 IO 线程处理请求。你可以根据实际硬件条件设置此线程池的个数。
当 IO 线程处理完请求后,会将生成的响应发送到网络线程池的响应队列中,然后由对应的网络线程负责将 Response 返还给客户端。
消费者组重平衡全流程解析
触发时机:
- 组成员数量发生变化。
- 订阅主题数量发生变化
- 订阅主题的分区数发生变化。
重平衡的完整流程需要消费者端和协调者组件共同参与才能完成。我们先从消费者的视角来审视一下重平衡的流程。