文章目录
基本概念
(1)索引、文档、REST API
文档----一行数据
- ES 是面向文档的,
文档是可搜索的最小单位 文档会被序列化成 JSON 格式,保存在 ES 里面,字段都会有对应的数据类型(字符串,布尔,日期等)- 每个文档有个 UNIQUE ID - 可以自动生成也可以指定
针对于每一篇文档,都会有元数据的信息存在,刑如:

索引-----多个行记录的集合
一个索引就是具有某些共有特性的文档集合,在ES中是一个名词,类似于 关系型数据库中库 的概念。

索引结构
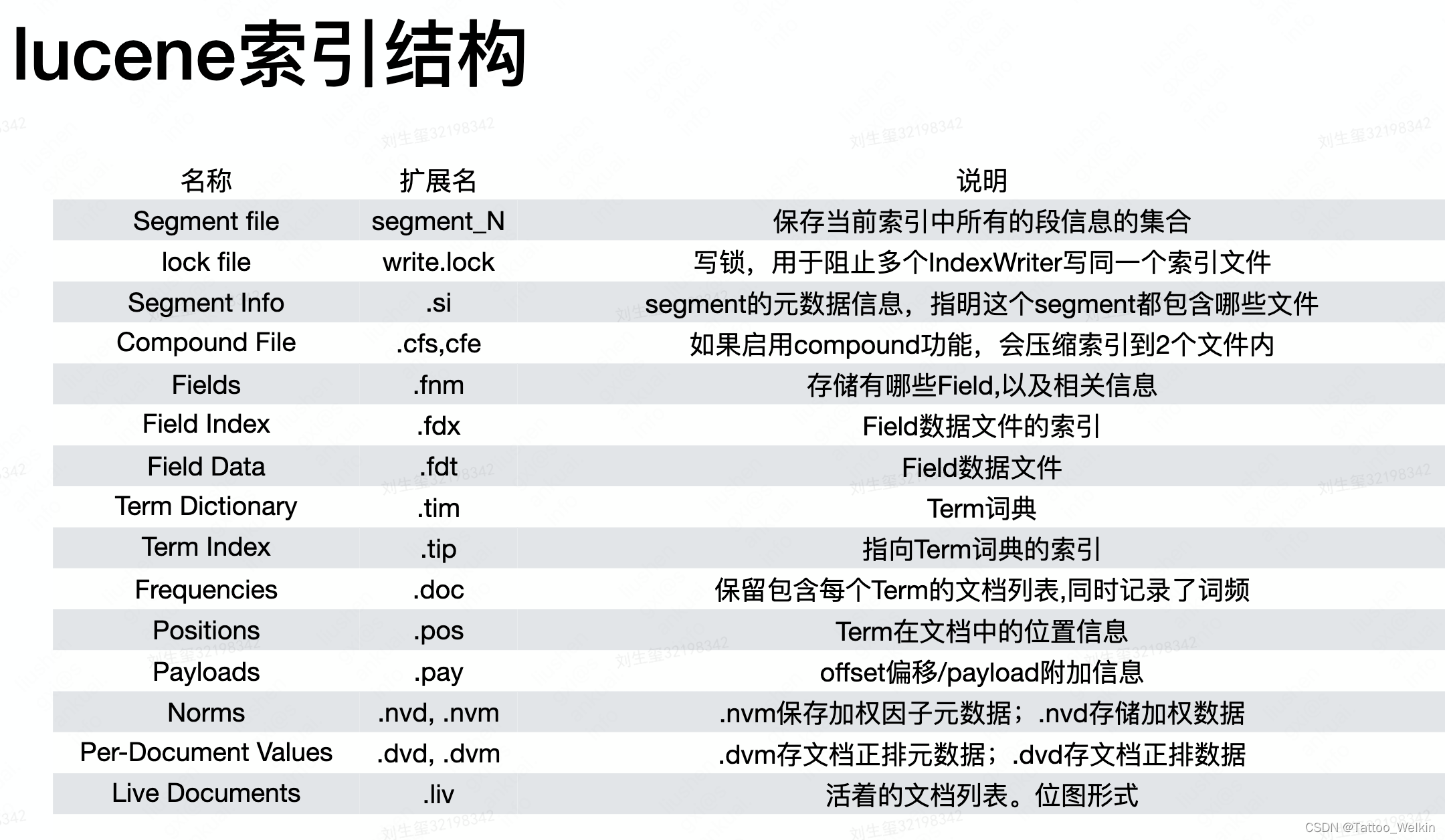
索引的具体实现细节
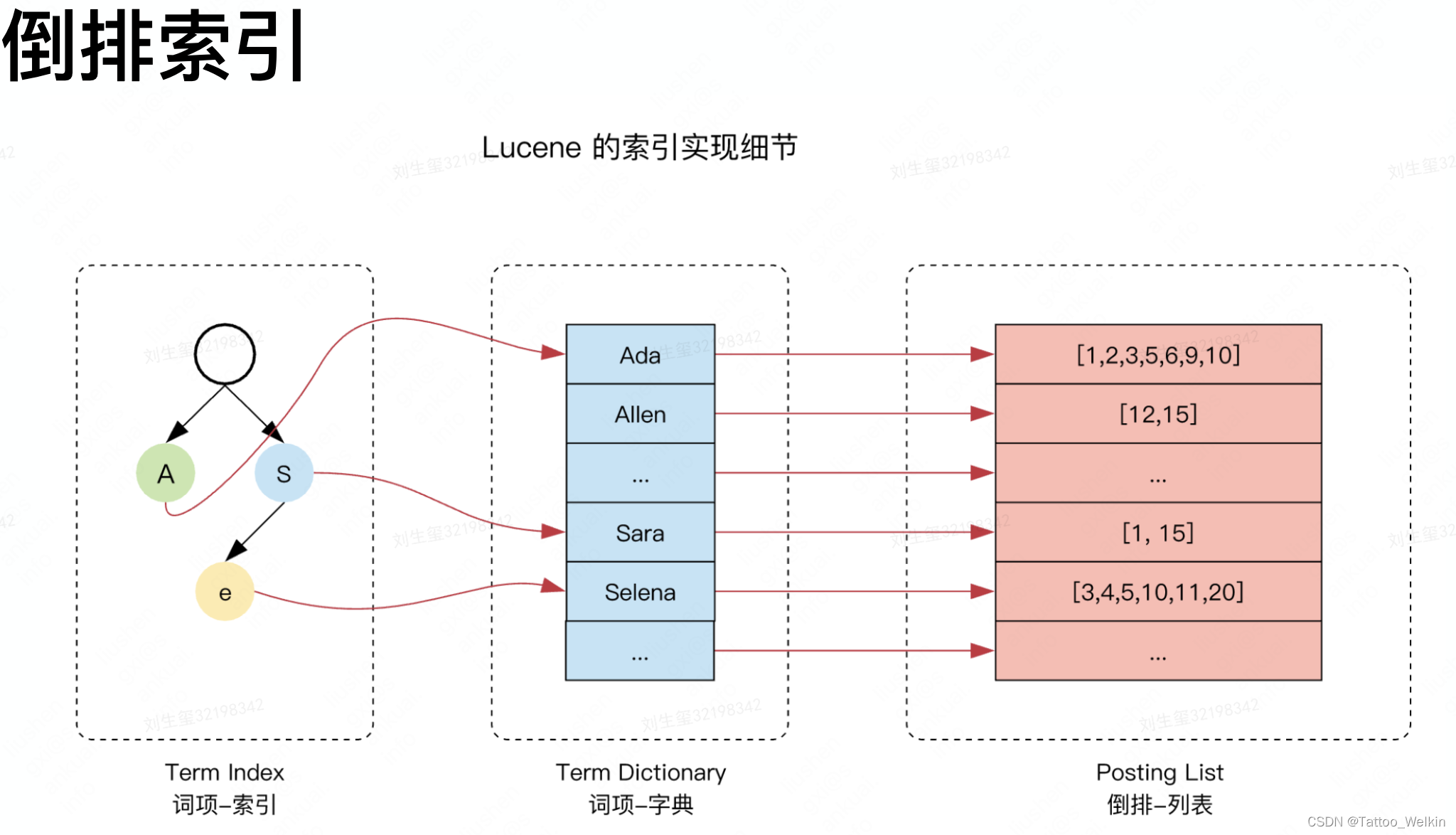
Type
7.0 之前在一个索引下可以创建多个Type, 但是 7.0 之后,只能创建一个,即 Type-"_doc"
与关系型数据库的类比
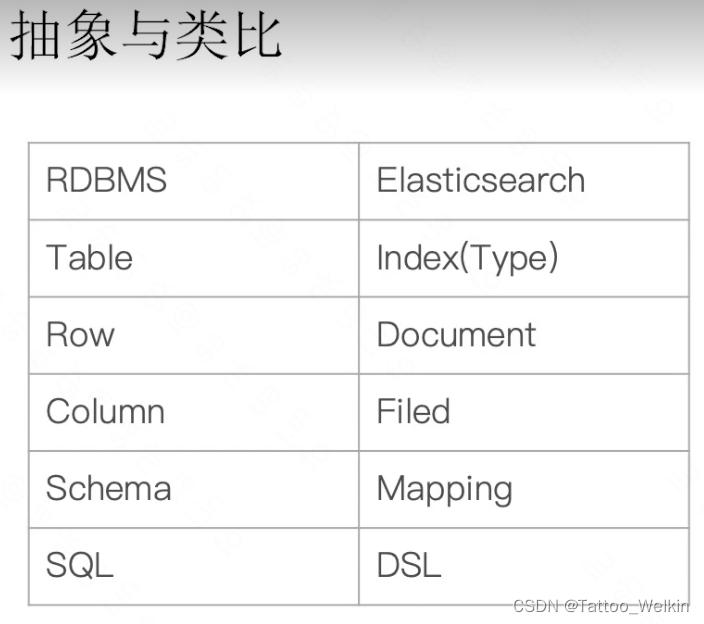
针对于数据量庞大或者需要高性能检索的场景而言,就选择ES,而如果数据量小,且需要大量事务操作的话,就选择一些关系型数据库。
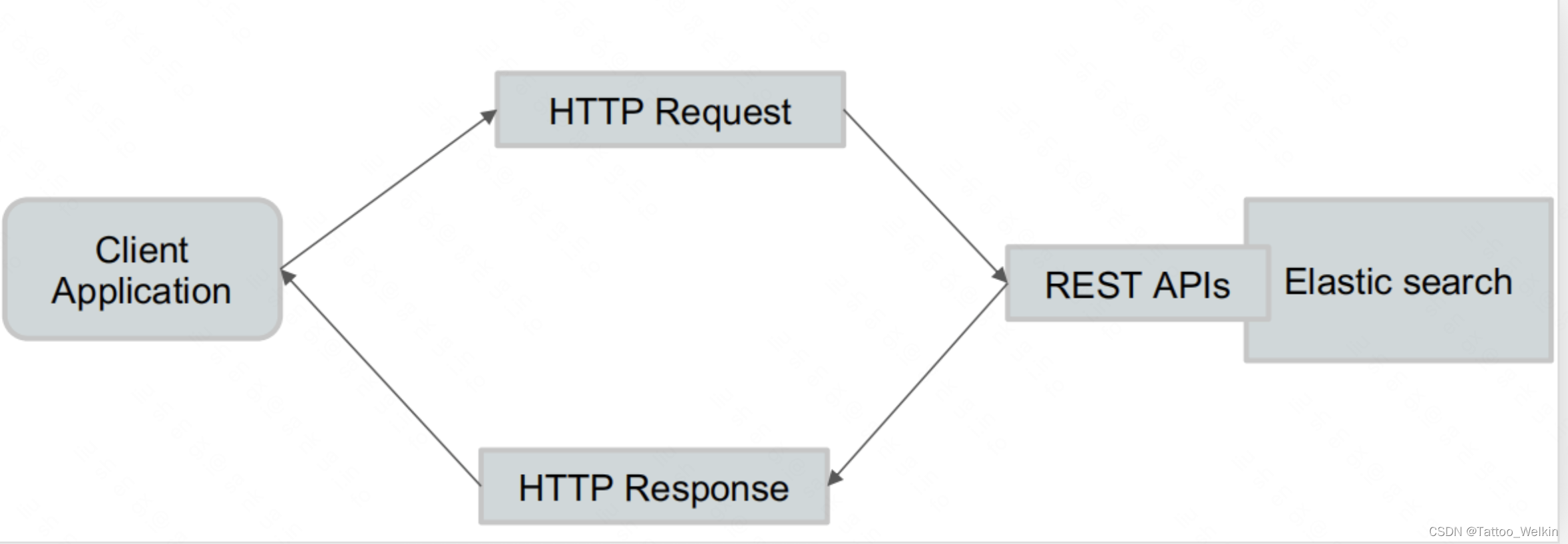
REST API ----很容易被各种语言调用
(2)节点、集群、分片及副本
节点—就是指集群下的一个节点
其实就是一个 ES 实例,本质上是一个 Java 进程。每个节点启动之后,会分配一个 UID,保存在 data 目录下。
节点分为多种类型:
- Master-eligible nodes (正常节点)
- 每个节点启动之后,默认就是 Master eligible 节点,第一个节点启动之后自动就是 master 节点
- Mater-eligible 节点可参加选主流程,成为 Master 节点
- 每个正常节点都保存了集群的状态,
但是只有 Master 节点才能修改集群的状态信息
集群的状态一般包含了:所有节点信息,所有的索引和其相关的 Mapping 与 Setting 信息,分片的路由信息
- Data Node (数据节点)
可以保存数据的节点,负责保存分片数据。 - Coordinating Node (代理节点:类比于消息队列中的代理)
- 负责接收 Client 的请求,将请求分发到合适的节点,最终把结果汇聚到一起
每个节点默认都起到 Coorinating Node 的职责
- Hot & Warm Node (冷热节点)
不同的硬件配置的 Data Node, 用来实现 Hot(热数据) & Warn(旧数据)架构,以降低集群部署的成本 - Machine Learning Node
负责跑机器学习的 JOB,用来做异常检测 - Tribe Node (未来要被淘汰)
5.3 开始使用 Cross Cluster Serach
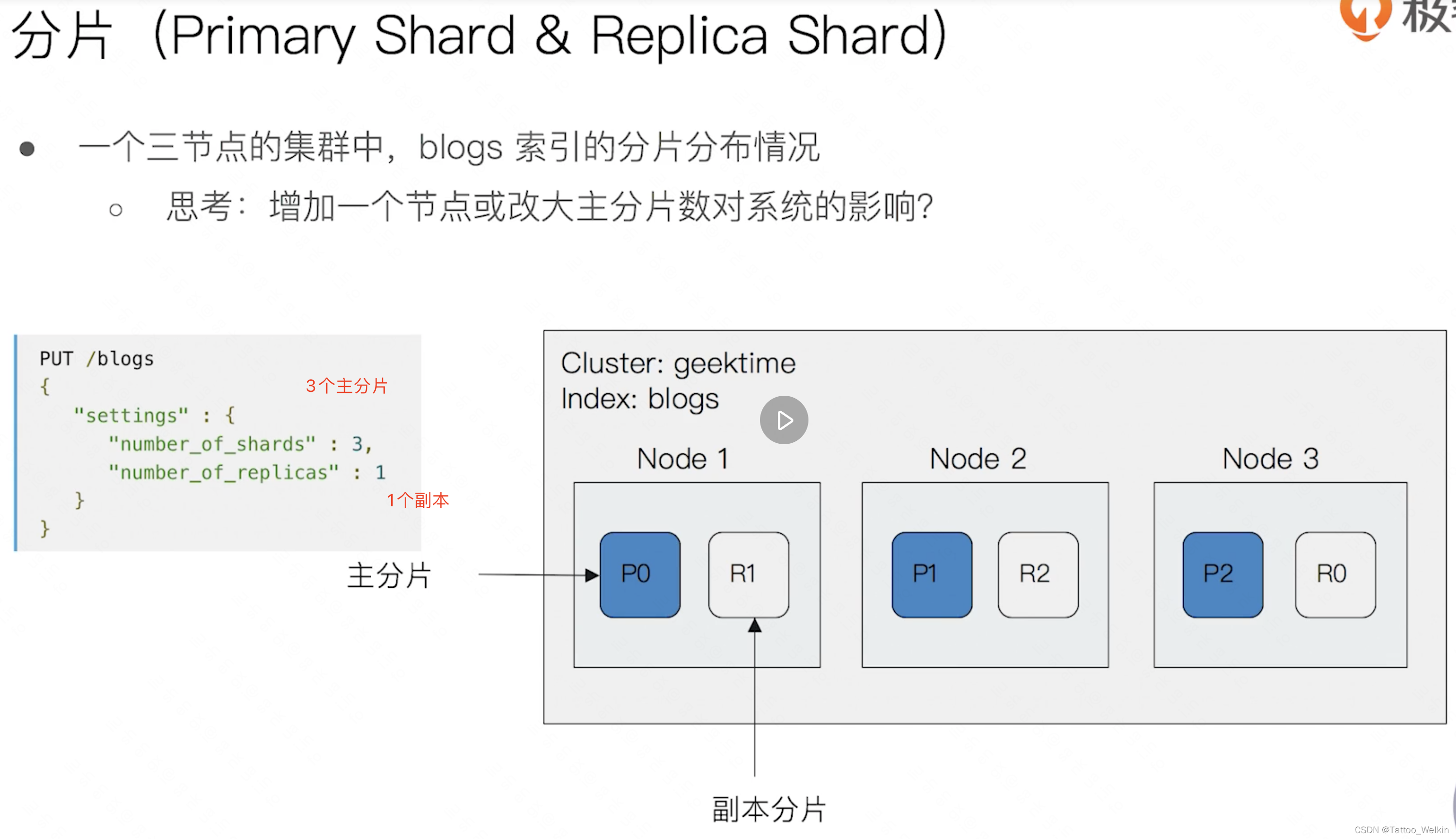
分片(Shard)------一个索引由多个分片组成,这些分片是索引里面的一部分,每一个分片都具备索引相同的数据结构
一个索引分成N个shard,每一个 Shard 的内容就是这个完整索引内容的 1/N
每个分片其实就是一个 Lucene 索引,Lucene 是倒排索引!
分为主副分片,主分片是一个运行的 Lucene 的实例,主分片数在索引创建时指定,后期不允许修改,除非 Reindex。
主分片会被尽可能平均地 (rebalance) 分配在不同的节点上(例如你有 2 个节点,4 个主分片(不考虑备份),那么每个节点会分到 2 个分片,后来你增加了 2 个节点,那么你这 4 个节点上都会有 1 个分片,这个过程叫 relocation,ES 感知后自动完成)。从分片只是主分片的一个副本,它用于提供数据的冗余副本,从分片和主分片不会出现在同一个节点上(防止单点故障),默认情况下一个索引创建 5 个主分片,每个主分片会有一个从分片 (5 primary + 5 replica = 10 个分片)。如果你只有一个节点,那么 5 个 replica 都无法被分配 (unassigned),此时 cluster status 会变成 Yellow。
分片是独立的,对于一个 Search Request 的行为,每个分片都会执行这个 Request。每个分片都是一个 Lucene Index,所以一个分片只能存放 Integer.MAX_VALUE - 128 = 2,147,483,519 个 docs。
例子:
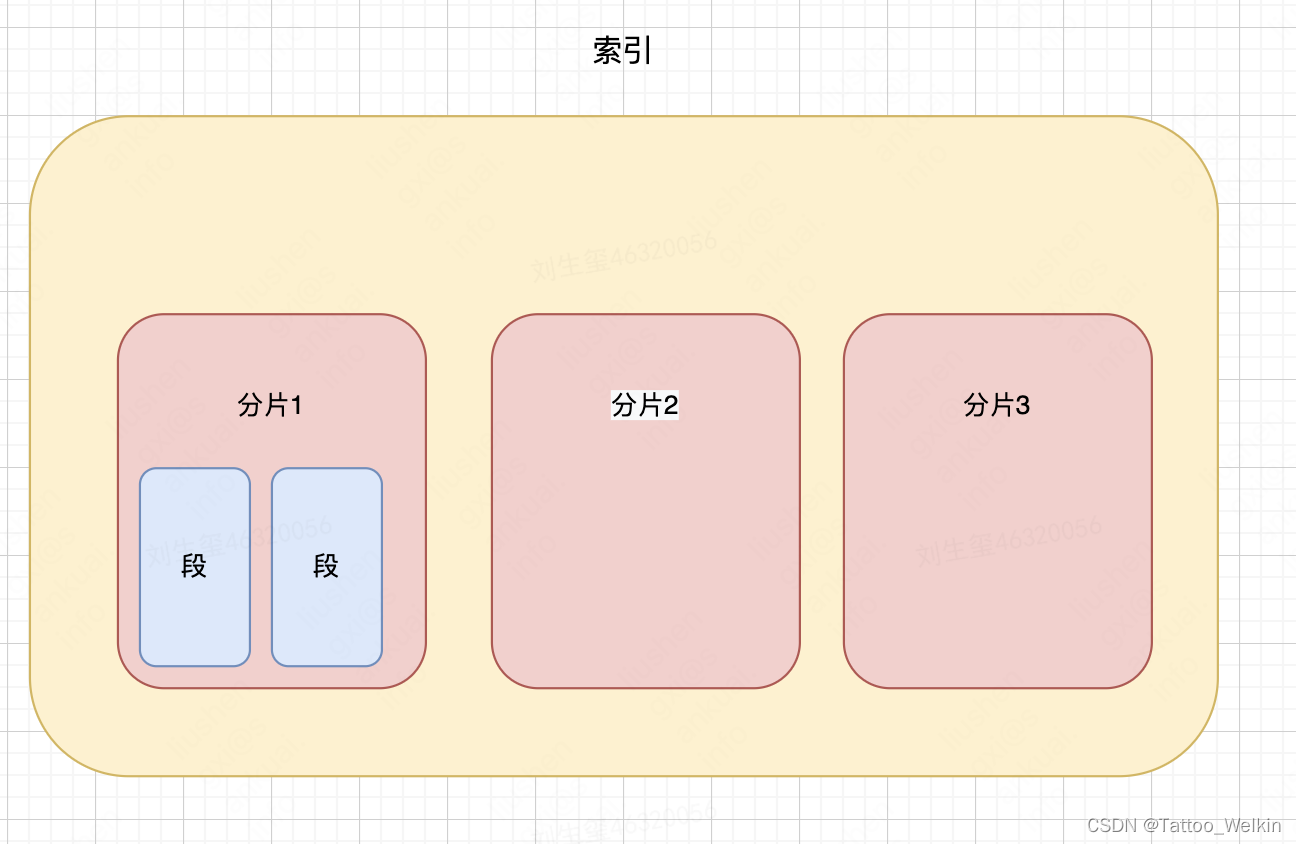
段(Segment)-------分片的组成单元
即多个段构成一个分片,
段是检索的基本单元,所有的查询/更新都是基于段来查询的
分词
- 分词,即文本分析(Analysis) - 是把全文本转换成一系列的单词(term /token)的过程,也叫分词。通过分词器(Analyzer)来实现,分词器会有很多,ES有内置的,也可以按需定制化分词器。如下例子:
除了在数据写入时转换词条,
匹配 Query 语句时候也需要用相同的分析器对查询语句进行分析
分词器
由三部分组成。
- Character Filters (针对原始文本处理,例如去除 html)
- Tokenizer(按照规则切分为单词)
- Token Filter (将切分的单词进行加工,小写,删除 stopwords,增加同义语)。
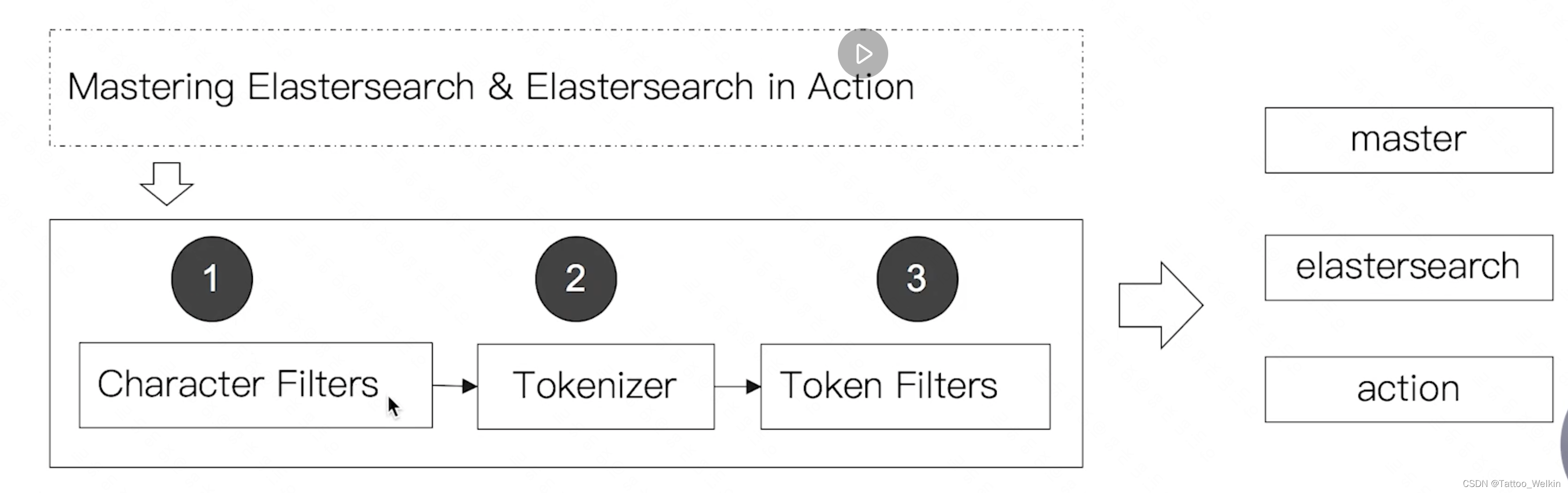
- CharFilters(0个或多个) + Tokenizer(恰好一个) + TokenFilters(0个或多个)
stopwords:停用词:指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。这些停用词都是人工输入的,主要包括英文字符(a,an,the,that 等)、数字、数学字符、标点符号及使用频率特高的单汉字(的,在,了,啊等)。
ES中内置的分词器
8 种:
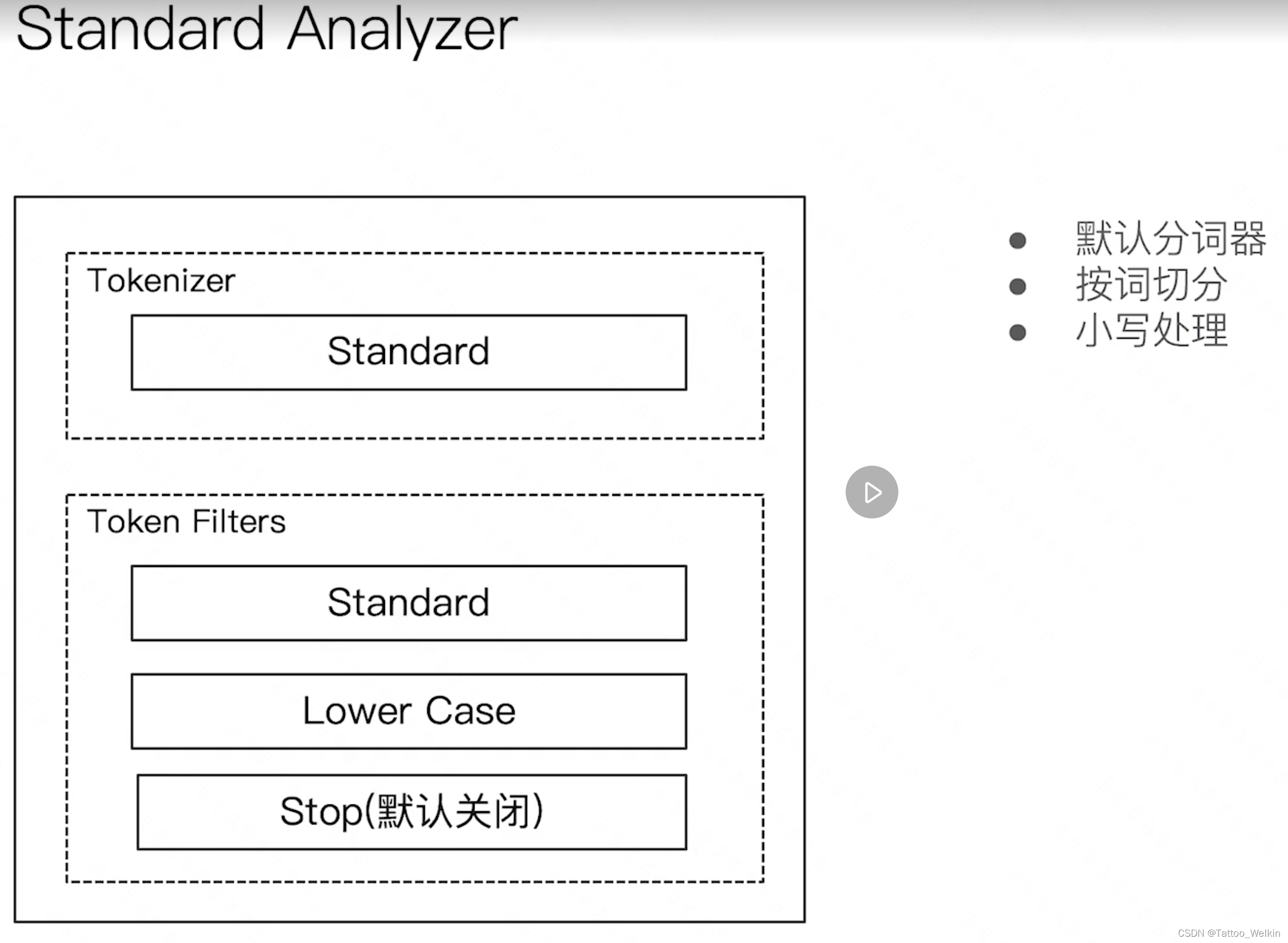
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤),小写处理
- Stop Analyzer - 小写处理,停用词过滤(the ,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
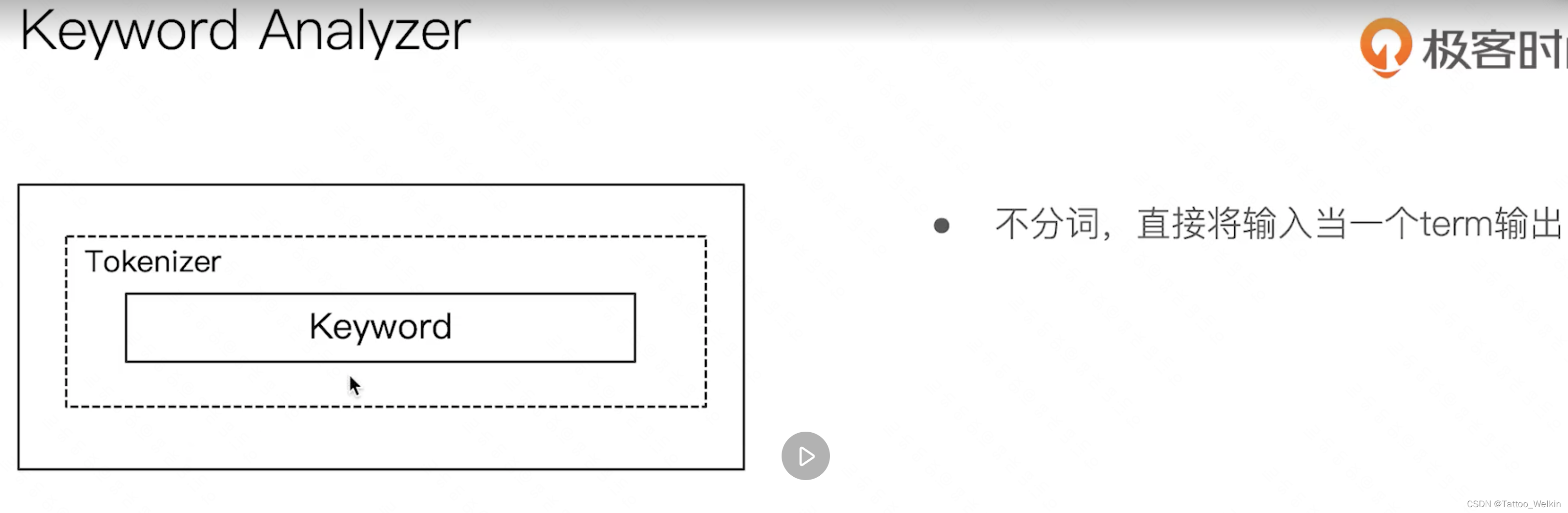
- Keyword Analyzer - 不分词,直接将输入当做输出
- Patter Analyzer - 正则表达式,默认 \W+
- Language - 提供了 30 多种常见语言的分词器
- Customer Analyzer 自定义分词器
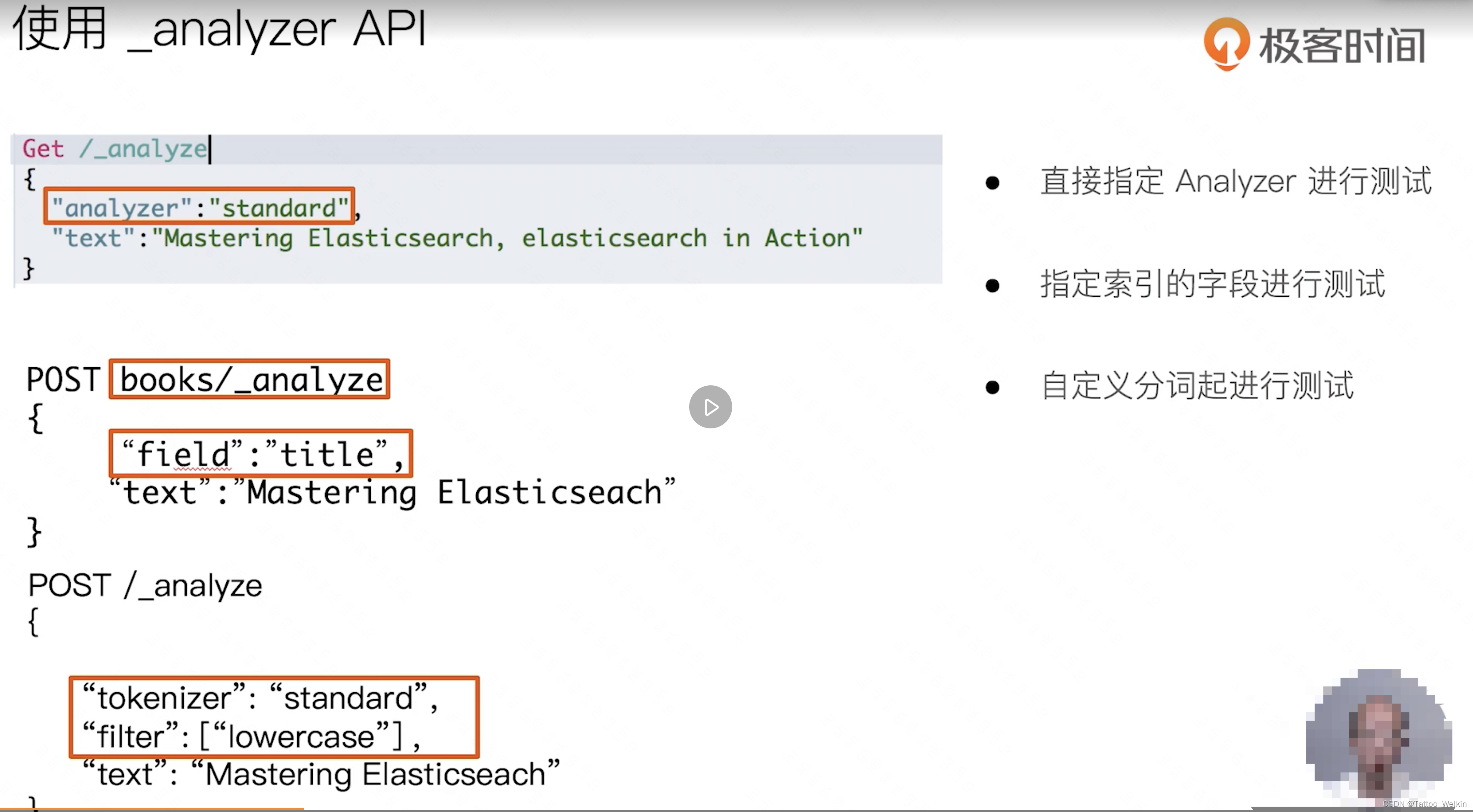
使用 _analyzer Api
此API的作用主要是三种。
- 直接指定 Analyzer 进行对传入数据分析
- 指定索引的字段查看该索引字段是如何分词的
- 自定义分词进行测试
默认分词器 Standard Analyzer 和 Keyword Analyzer
中文分词:IK分词器
搜索
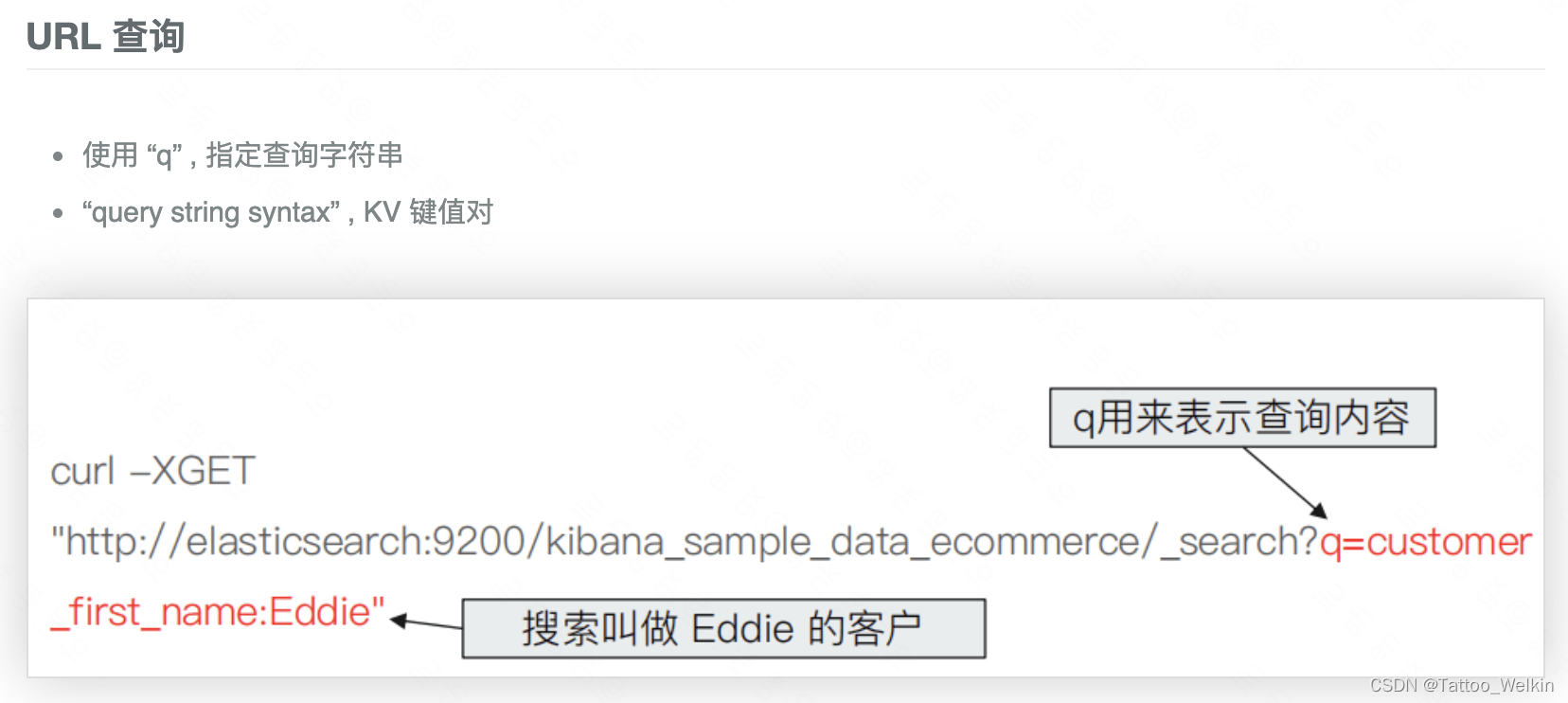
搜索API
ES的搜索API分为两类,一类是URL Search(即在 URL 中使用查询参数),另一类是Request Body Search(使用 Elasticsearch 提供的,基于 JSON 格式的格式更加完备的 Query Dpmain Specific Language (DSL)),目前我们工作中使用的是 Request Body Search。
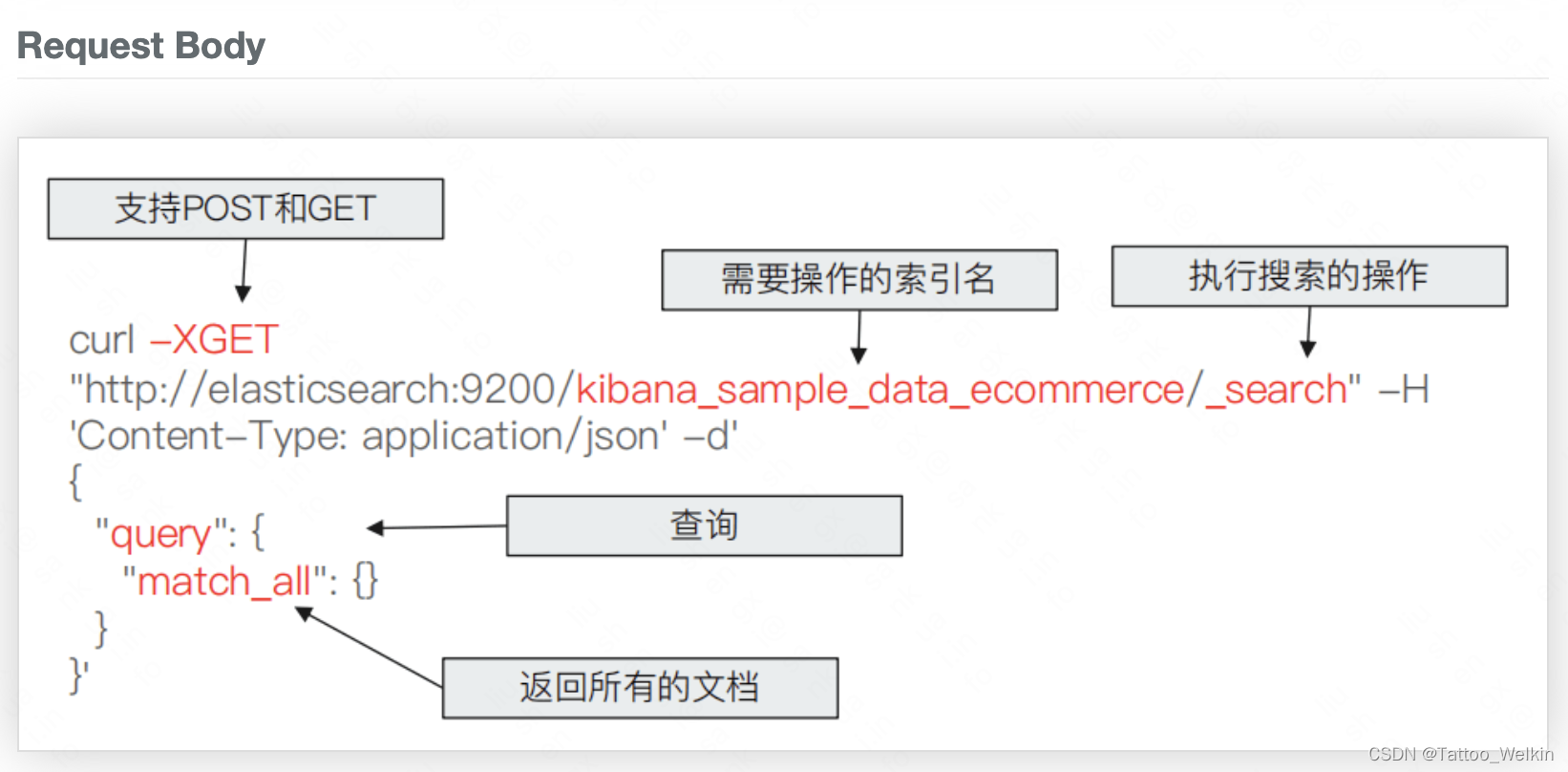
检索
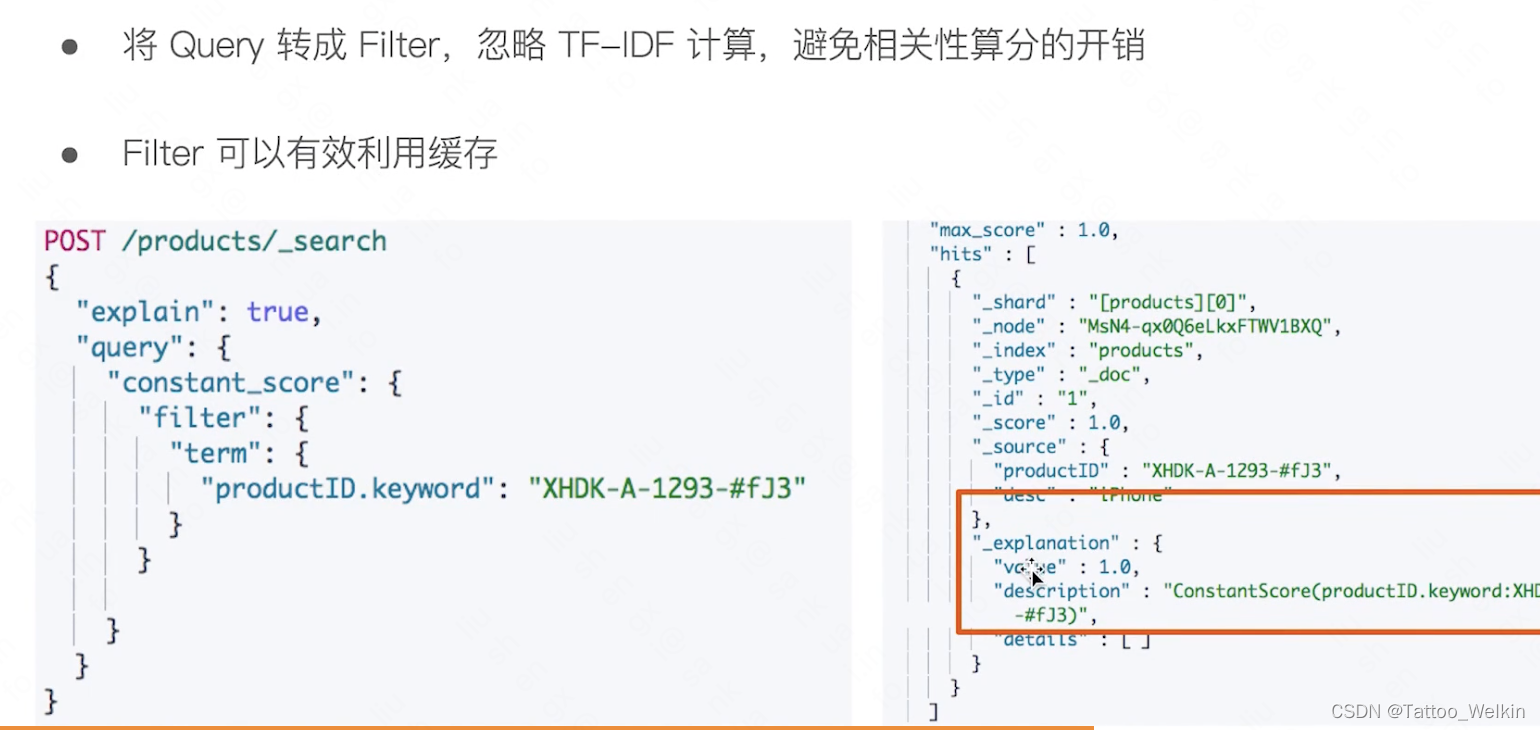
term 查询:单个精确值查找(term query),包含:范围查询,前缀查询。对输入不会做分词处理。
在进行精确值查找时, 我们会使用过滤器(filters)。过滤器很重要,因为它们执行速度非常快,不会计算相关度(直接跳过了整个评分阶段)而且很容易被缓存。如下: 使用 constant_score 查询 (性能高)以非评分模式来执行 term 查询并以一作为统一评分。
全文搜索:会对输入的查询进行分词。然后每个词项逐个进行底层的查询,最终将结果进行合并。并为每个文档生成一个算分。 例如查 “Martix reloaded”, 会查到包括 Matrix 或者 reload 的所有结果。
bool 查询
一个 bool 查询,是一个或者多个查询子句的组合
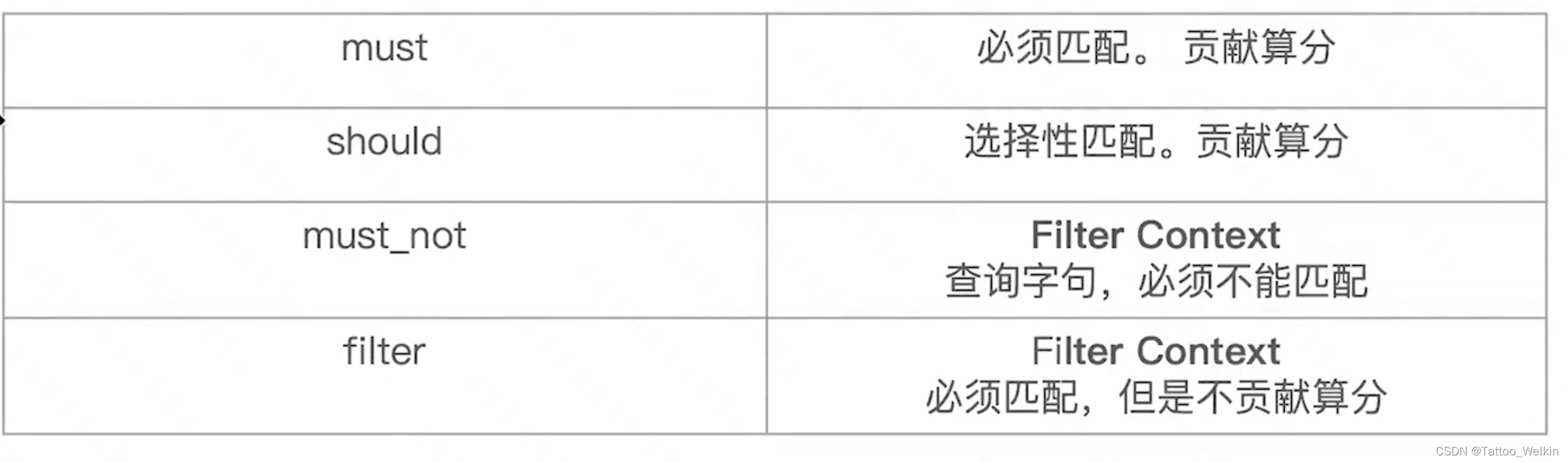
- must ——所有的语句都 必须(must) 匹配,与 AND 等价。
- must_not ——所有的语句都 不能(must not) 匹配,与 NOT 等价。
- should ——至少有一个语句要匹配,与 OR 等价。
- filter——必须匹配,运行在非评分&过滤模式。
