哈夫曼编码和译码。将以前学的c++相关知识系统的用了一遍,反正是能想到啥,啥方便就用啥,但是说回来,也没省多少事。反正比用c语言写跟简单一点。
先看题目原型吧!
假设某通信报文的字符集由A,B,C,D,E,F这6个字符组成,它们在报文中出现的频度(频度均为整数值)。
(1)构造一棵哈弗曼树,依次给出各字符编码结果。
(2)给字符串进行编码。
(3)给编码串进行译码。
规定:
构建哈弗曼树时:左子树根结点权值小于等于右子树根结点权值。
生成编码时:左分支标0,右分支标1。
输入
第一行:依次输入6个整数,依次代表A,B,C,D,E,F的频度,用空格隔开。
第二行:待编码的字符串
第三行:待译码的编码串
输出
前6行依次输出各个字符及其对应编码,格式为【字符:编码】(冒号均为英文符号)
第7行:编码串
第8行:译码串
样例输入
3 4 10 8 6 5
BEE
0010000100111101
样例输出
A:000
B:001
C:10
D:01
E:111
F:110
001111111
BADBED
所用到的相关知识,最近学的智能指针,迭代器,STL中的list链表,array数组容器,继承,就这些吧!我也不怎么考虑算法的优劣了。这感觉确实所用到的变量太多了。我得汇总一下~~~
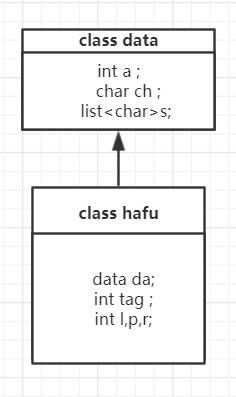
以上为相关类和属性,其中data类中
- a 字符出现的频数
- ch 对应的字符
- s 编码链表字符类型,左为0右为1
- hafu类中的方法全是静态方法(通过类名来使用)
其中hafu类是继承data类的。tag属性是标记当前节点是否存在父节点,不存在为0,存在为l、p、r分别为左孩子下标有孩子下标,p为双亲下标。
首先初始化data链表,将字符该放入的放入,该置0的置0,接下来第一核心部分建树。
难就难在找最小权值下标和次小权值下标,不管了,我的实现方法就是先在无父节点的节点中找最大值,并在findmax函数中记录无父节点的节点个数,当个数为1时说明我们的树已经建的差不多了,该收工了,否则,设置min等于那个最大值+1,然后在数组中和其他节点权值比较,依据题目要求,让左节点权值小于有节点权值,先获得的最小权值的下标赋给kl,在第一趟循环完了后将以kl为下标的节点的tag置为1,它将是有爸爸的孩子啦!然后再在第二趟循环中招最小权值下标,赋给kr,然后就是哈夫曼算法,让父节点的做有孩子下标为kl,kr,让孩子的父亲节点的下标为新创建的节点的下标!树的创建大致思路就是这样。点到为止!
接下来就是编码,这在哈夫曼树算法中不算核心,很简单,就根据节点的个数,逐个遍历,从第一个开始,按照父亲节点的下标,然后依据父亲节点的下标找到父亲节点,然后,看父亲节点的孩子下标,判断当前节点的下标是父节点的左孩子还是右孩子,若是右孩子,往编码链表中追加字符1,否则追加字符0,当遇到当前节点的父节点下标为0时,表示已经到树顶了!然后将链表逆置,因为我们的编码方向是从树顶到根,逆置后才是当前节点真正的哈弗曼编码,直接调用函数就行了。然后进行下一个节点的编码!同样的方法!
在我看来,最难得就是译码了,真是很烧脑。
我是怎么解决的呢?
方法比较笨!根据输入的编码数组,我们要在指针数组中根据不同字符的编码和输入的字符串进行匹配,然后找到匹配的字符输出。我就是先遍历对象数组,用每一个字符的编码与所输入的数组前面的字符进行匹配,若匹配正确就将输入的数组中的刚匹配的字符全置为‘#’符号,然后再输出对象数组中存的对应字符,再从对象数组头开始和匹配数组非‘#’元素再进行匹配;当该数组中元素全为’#'号时,说明匹配完了;若当前对象数组的当前元素和匹配数组中前几个非‘#’元素不匹配,用下一个对象的编码进行再次匹配即可。不断循环!
main函数
#include<iostream>
#include<stdlib.h>
#include<memory>
#include<list>
#include"hafuman.h"
using namespace std;
int main(){
//智能指针数组
array<shared_ptr<hafu>,SIZE>arr ;
//初始化
hafu::init(arr);
//创建哈夫曼树
hafu::process(arr);
//获取哈夫曼编码
hafu::makeCode(arr);
//返回哈夫曼编码
hafu::request(arr);
//翻译编码
hafu::transform(arr);
}
头文件
#ifndef _HAFU_H_
#define _HAFU_H_
#include<iostream>
#include<stdlib.h>
#include<stdio.h>
#include<memory>
#include<vector>
#include<list>
#include<string.h>
using namespace std;
//SIZE为字符个数
//MAXLINE为使用的字符串长度
enum {SIZE = 11,MAXLINE = 100};
class data{
public:
int a ;
char ch ;
list<char>s;
};
class hafu:public data{
public:
data da;
int tag ;
int l,p,r;
hafu():tag(0){}
~hafu(){}
//找当前数组中无父节点的节点中字符频率(权值)最大的节点
static int findmax(int s,int &kl,array<shared_ptr<hafu>,SIZE>&ls);
//找当前无父节点的节点中权值最小的两个节点
static void find(int s,int& kl,int &kr,array<shared_ptr<hafu>,SIZE>&ls);
//初始化智能指针数组
static void init(array<shared_ptr<hafu>,SIZE>&ls);
//建立哈夫曼树
static void process(array<shared_ptr<hafu>,SIZE>&ls);
//便利哈夫曼树
static void print(const array<shared_ptr<hafu>,SIZE>&ls);
//编码
static void makeCode(array<shared_ptr<hafu>,SIZE>&ls);
//逆置链表
static void reverse(list<char>&s);
//打印各个的编码
static void printCodes(array<shared_ptr<hafu>,SIZE>&ls);
//输入字符,返回相关编码
static void request(const array<shared_ptr<hafu>,SIZE>&ls);
//打印各自父节点的编码
static void printlist( list<char>&s);
//译码
static void transform(const array<shared_ptr<hafu>,SIZE>&ls);
static int search(list<char>&s ,char* arr,int i);
};
int hafu::search(list<char>&s,char *arr,int i){
list<char>::iterator iter ;
int k = 0 ;
for(k = 0 ;k < strlen(arr);k++ ){
if(arr[k]!='#')break ;
}
int m = k ;
int count = 0 ;
for(iter = s.begin();iter!=s.end();iter++){
if(*iter == arr[k]){
count ++ ;
k++ ;
}
else{
return 0;
}
}
int len = s.size();
int kk = m;
for(k = 0 ;k< len ;k++){
kk = m+k;
arr[kk] ='#';
}
return 1 ;
}
void hafu::transform(const array<shared_ptr<hafu>,SIZE>&ls){
char s[MAXLINE];
cin>>s;
int i = 0,j ;
int len = strlen(s);
for(i =0 ;i< (SIZE+1)/2;i++){
i = j ;
if(s[strlen(s)-1]=='#'){
break;
}
if(search(ls[i]->da.s,s,i)){
cout<<ls[i]->da.ch<<"";
j = 0 ;
//这是个巨坑
if(i == (SIZE+1)/2-1){
i = 0;
}
}
else{
j++ ;
}
}
cout<<endl;
}
void hafu::printlist( list<char>&s){
list<char>::iterator iter ;
for(iter=s.begin();iter!=s.end() ;iter++){
cout<<*iter<<"";
}
}
void hafu::request(const array<shared_ptr<hafu>,SIZE>&ls){
char arr[MAXLINE];
cin>>arr ;
int len = strlen(arr);
int i ,j;
int flag = 0 ;
for(i = 0 ;i< len ;i++){
for(j = 0 ;j<(SIZE+1)/2;j++){
if(ls[j]->da.ch == arr[i]){
printlist(ls[j]->da.s);
flag =1 ;
}
}
if(flag==0)return ;
}
}
void hafu::printCodes(array<shared_ptr<hafu>,SIZE>&ls){
int i = 0;
for(i = 0 ; i < (SIZE+1)/2 ;i++){
list<char>::iterator iter ;
cout<<ls[i]->da.ch<<":";
for(iter = ls[i]->da.s.begin() ; iter!=ls[i]->da.s.end();iter++){
cout<<*iter<<"";
}
cout<<endl ;
}
}
void hafu:: reverse(list<char>&s){
int i ;
s.reverse();
}
void hafu::makeCode(array<shared_ptr<hafu>,SIZE>&ls){
int i = 0 ;
int j = 0;
for(j = 0 ;j < (SIZE+1)/2;j++){
int index = ls[j]->p;
int k = j ;
while(index){
if(ls[index]->l == k){
ls[j]->da.s.push_back('0');
}
if(ls[index]->r == k){
ls[j]->da.s.push_back('1');
}
k = index ;
index = ls[index]->p;
}
reverse(ls[j]->da.s);
}
printCodes(ls);
}
int hafu::findmax(int s,int &kl,array<shared_ptr<hafu>,SIZE>&ls){
int i ,j;
int temp ;
kl = -1 ;
int count = 0;
for(i = 0;i < s ;i++){
if(kl< ls[i]->da.a && ls[i]->tag != 1){
kl = i;
}
if(ls[i]->tag == 0)count++ ;
}
}
void hafu::find(int s,int& kl,int &kr,array<shared_ptr<hafu>,SIZE>&ls){
int i= 0, j = 0 ;
int count ;
count = findmax(s,kl,ls);
if(count==1){
kr = -1 ;
return ;
}
//此处趟了一枪,没处理好,导致Oj过不了
int mins =ls[kl]->da.a+10;
for(i = 0 ;i < 2 ;i++){
int min = mins ;
for(j = 0 ; j < s ; j++){
if(i==0&&ls[j]->da.a < min&&ls[j]->tag == 0){
min = ls[j]->da.a ;
kl = j ;
}
if(i==1&&ls[j]->da.a < min&& ls[j]->tag==0){
min = ls[j]->da.a ;
kr = j;
}
}
if(i == 0)ls[kl]->tag = 1 ;
if(i == 1){
ls[kr]->tag = 1 ;
break ;
}
}
}
void hafu::print(const array<shared_ptr<hafu>,SIZE>&ls){
int i = 0 ;
for(i =0 ;i < SIZE ;i++){
cout<<ls[i]->da.a<<" "<<ls[i]->p<<" "<<ls[i]->l<<" "<<ls[i]->r<<endl;
}
}
void hafu::process(array<shared_ptr<hafu>,SIZE>&ls){
int j = (SIZE+1)/2;
int i ;
int kl=-1,kr=-1 ;
for(i =j ;i< SIZE;i++){
find(i,kl,kr,ls);
if(kr == -1)break ;
ls[i]->da.a = ls[kr]->da.a + ls[kl]->da.a ;
ls[i]->l = kl ;
ls[i]->r = kr ;
ls[kl]->p = i ;
ls[kr]->p = i ;
}
}
void hafu::init(array<shared_ptr<hafu>,SIZE>&ls){
int j = 0 ;
for(j = 0;j < SIZE;j++){
shared_ptr<hafu>p(new hafu);
if(j<6)cin>>p->da.a ;
ls[j] = p ;
}
int i = 0;
char ch;
char arr[6] = {'A','B','C','D','E','F'};
for(i = 0 ;i< (SIZE+1)/2;i++){
ls[i]->da.ch=arr[i];
}
i = 0 ;
while(1){
if(i == SIZE){
break ;
}
ls[i]->l = 0;
ls[i]->r = 0;
ls[i]->p = 0;
if(i >= (SIZE+1)/2){
ls[i]->da.ch = '\0';
ls[i]->da.a = 0;
i++ ;
continue ;
}
i++ ;
}
}
#endif
运行截图:

之前写的OJ过不了,最后问老师这个问题,她给了我另一组数据让我测,果然出错,原因就在找最小值和译码那块,幸好不是大问题,尽管OJ过了,还是希望读者能掌握解题方法!