文章开始之前我们先抛出几个问题:
- 大家都说TCP比UDP可靠,是这样吗?如果真是这样,那么TCP的可靠性体现在哪儿或者说TCP的可靠性通过什么手段来保证。
- UDP不如TCP可靠,那么为什么数据的传输不全采用TCP的方式,非要给UDP分一杯羹呢?
- 我们都知道数据包的分片,为什么数据包的分片的任务没有交给传输层而是放在了网络层进行,其中难道有什么不可描述的交易?
- TCP的实现连接的建立要经过三次握手,为什么是三次?两次行不行?
下面我们将根据这些问题,做一些简单的解释:
首先我们来看一下UDP:
-
概念
- UDP是一个简单的传输层控制协议,它是无连接的数据报协议。UDP不保证会到达最终目的地,同时它也不保证各个数据报的先后顺序跨网络后保持不变,不保证相同的数据报只到达一次,由此我们可以看出UDP的不可靠性。比起TCP协议的流式特性,每个UDP的数据报都有一个长度,当对端收到数据报,该长度也将传递给对端的应用进程。
- 下面我们来解剖一下UDP,看一下它的首部构造:

- 每个UDP的首部前面会额外的增加一个伪首部,用来传输层数据报的差错校验。
-
应用
- DNS域名解析
UDP是一个不可靠的协议,为什么域名解析这么重要的工作不交给TCP来完成而是UDP呢?我们知道TCP在真正开启数据请求之前要先建立连接,也就是我们常说的三次握手。当然可靠性的建立必然以牺牲其他利益为代价,对于TCP而言,这代价便是时间,UDP在时间的观念上便更胜一筹,当然完成域名解析一个数据报也足矣,所以使用UDP何乐而不为呢。 - QQ聊天数据的发送(此处并不包含大型文件的传送)
- 屏幕广播(英语听力课不就是这种方式嘛)
- DNS域名解析
接着我们来看一下 TCP:
-
概念
-
TCP是一种面向连接的、可靠的、字节流协议。基于TCP的流式特性,所以这就要求用户自己来规划协议,划定消息边界。目前常见的方式有三种:
- 在每个要发的数据报之前附加一个数据长度,对端通过阻塞的方式进行读或写操作,直至数据结束。
- 设定一个特殊的结束标志比如像HTTP的结束标志 \r\n。
- 每次发一个固定长度的数据报,对端也每次接受相等的数据内容。
-
同样的我们来解剖一下TCP看一下它的首部:

-
-
可靠性保证
- 三次握手机制建立连接
首先我们来看一下三次握手的过程:

首先客户端会先向服务器发送一个数据请求,也就是SYN分节,该数据报含了数据的初始序列号、接受窗口,拥塞窗口、接受缓存的大小以及相应网卡所支持的最大数据大小等信息,同样的服务器会针对客户端的请求做一个相应的回应。接着客户端会根据服务器的回应也相应的回复一个ack消息,至此连接成功建立。
你可能会有这样的疑问,握手为什么非得三次,如果说因为TCP是全双工的,需要双方先自报家门,两次完全就够了, 为什么最后还要再经过客户端的一次确认,这不是多余的吗?这样的疑问不是没有道理,我们先来看一个场景:如果路由器在转发客户端的第一次请求的数据报的时候,选择了一条比较长的网络路径,数据报并没有及时传给服务器。一段时间后(小于数据报的存活时间)客户端收不到来自于服务器的回应,于是重传了一次数据报,这次发送的数据报及时送给服务器,相应的客户端也及时收到了来自于服务器的回应。这个时候客户端第一次发送的数据报经历重重险阻终于到达了服务器,服务器以为客户端又发起了一个建立连接的请求,于是给客户端一个回应。由于客户端此前已经收到了此次回应,所以对服务器刚刚的回应不予理睬,服务器以为客户端没有收到自己的回应于是重传。。。。。这种情况将导致服务器的资源被长期占用这不是我们所乐意看到的。而三次握手则很好的避免了这种情况的发生。
-
数据报的错误重传
这个不言而喻,在此也不再赘述。 -
流量控制
说流量控制之前我们先讲一讲信道利用率,我们先来看一张图片

-
其中Td是数据报发送时间,Ta指数据报接收时间,RTT指数据报往返时间
现在从客户端B到客户端A数据报经历的总时间T = Ta + Td + RTT;其中信道利用率可看似 = Td / T,图中我们可以看出大量的时间用来等数据报,这样是不划算的。有什么比较经济的做法呢?没错,我们可以通过不间断的发送数据报来进一步提高信道利用率,这就是所谓的滑动窗口技术。
我们来看一张接收窗口的结构图
-
为了便于叙述,我们先将发送方规定为A,接收方为B
和B一样,相应的A存在一个接收窗口大小,A的发送窗口大小由A的拥塞窗口大小和B的接收窗口大小共同决定(二者取其较小值),要说明的是发送窗口的大小受不同的网络环境和接收方的接收缓存大小的影响,也就是说TCP可以根据实际的网络情况通过动态调整各类窗口的大小来实现对流量的控制。 -
拥塞避免
- 拥塞的条件:对资源的需求总和 > 可用资源
相比于流量控制,拥塞现象是多台客户机不断发数据报导致路由器承受太多的负荷甚至死机而造成的网络拥堵。我们来看一张图:

我们可以看到没有拥塞控制的网络环境是非常危险的,甚至会导致网络环境彻底瘫痪。那么TCP是怎样避免这种现象呢?早些年TCP采用慢开始算法来规避这问题,现在更多的是采用快重传、快恢复的方法。至于这两种算法的具体介绍有兴趣的小伙伴可以自己学习,在此就不再赘述。
- 拥塞的条件:对资源的需求总和 > 可用资源
-
- 三次握手机制建立连接
为什么数据报分片的重任交给了网络层?
-
我们先来看看网络层的作用:主要负责给来自传输层的数据打上自己的IP包头,而不用理睬数据是TCP、UDP、IGMP,ICMP还是其他的数据类型。如果将数据分片交给传输层,必然会先关注数据是采用TCP还是UDP,这无形间增加了实现的难度,所以交给网络层比较经济。要说明的是我们要尽量避免数据报的在网络层的分片,因为数据报分片后会提高路由器cpu的使用率,甚至造成网络拥堵的情况的发生。现在通常有两种方式来避免这种情况的发生:
- 最大传输单元(MTU)
我们知道一般网卡都有一个最大传输单元(MTU),以太网规定的MTU大小是1500字节。这就意味着超过1500字节的数据报将会被分片,但是只要小于1500字节的数据报就可以避免不被分片的命运了吗?答案是否定的。这里的数据报大小指的是传至数据链路层的数据报大小,所以真正称得上数据的部分其实只有1500 - TCP包头 - IP包头 = 1460字节。 如果不想被分片,那就得保证来自于应用层的数据大小不能大于1460字节。 - 路径MTU的发现机制(PMTU)
聊PMTU之前,我们得先解剖一下IP报头:
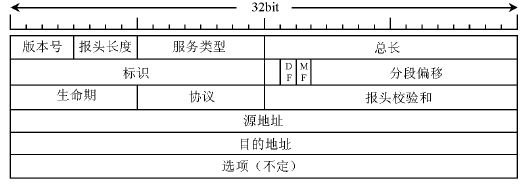
如果说现在又1460字节大小的数据报在网上传输,此时要经历一个MTU只有1000字节大小的路由器,普通的数据报肯定要经历分片,但是如果IP报头的标记位中的DF位为1,即不允许分片,那么此时路由器便会向请求主机发送一条ICMP消息,告诉主机请发一个1000字节的数据报。
- 最大传输单元(MTU)