file 辨识文件类型和编码格式
| 参数 | 含义 |
|---|---|
| 文件名 | 查看指定文件的类型信息 |
| -b 文件名 | 查看指定文件的类型信息但是不输出文件名 |
| -i 文件名 | 输出文件的MIME类型字符串 |
| -F “符号” 文件名 | 将输出的格式文件名 符号 文件类型和编码格式 |
| -L 文件名 | 查看软连接文件 |
| -f 文件名 | 按照清单去做 |
| -z 文件名 | 查看压缩文件内部的文件(只支持对gzip包内部文件的窥探,对于tar,tar.gz,tar.bz2,bz2包全部都不支持) |
查看文件类型
不加参数
-b

-i

MIME类型:‘Multipurpose Internet Mail Extensions’多用途互联网邮件扩展类型,用来***标识和记录文件的打开方式***。常见的类型:
名称 含义 text/plain 普通文本 text/html HTML文本 application/pdf PDF文档 application/msword Word文档 image/png PNG图片 image/jpeg JPEG图片 application/x-tar TAR文件 application/x-gzip GZIP文件
-F意义:在一些自动化文件分析的脚本中,开发者为了避免分隔符和普通字符重复而造成误,解析的情况通常是会手动调整间隔符的

-L
- 如果通过file命令直接查看软连接文件,则查看的就是软连接文件本身的信息
- 如果使用-L选项来查看软连接文件,则查看的是软连接指向的目标文件的信息
-f
-
如果一个文本文件的内容是很多文件的名称,那么我们可以指定-f选项来制定这个文本文件,file命令就会乖乖地去逐个查看每一个文件的类型信息。
*
-z -
制作一个未经压缩的tar包

-
制作一个经过gzip压缩过的tar包

-
制作一个bzip2压缩的tar包

-
以上都是一个压缩包由多个文件,那是不是因为文件是多个的原因?试一下一个文件的情况
- 制作一个bzip2压缩的单个文件

- 制作一个gzip压缩的单个文件

ln链接文件或目录
可以创建一个文件的影子,也可以通过通道进入另外一个地方。
软连接和硬链接
- 软连接文件:
- symboliclink,类似于windows里的快捷方式
- 是windows提供的一种快速启动程序。有些文件有很多的文件夹,要找到某个文件就要一层一层的打开每个文件夹,为了避免这种繁琐操作,windows有一种快捷方式,就是把这个文件的链接放到桌面,快速驱动。这样就能很快地找到并打开所要的文件,程序,所以叫快捷方式。
- 这个软连接文件(A)的内容其实是另一个文件(B)的路径和名称。当打开A文件时,实际上系统会根据其内容找到并打开B文件。
- 硬链接文件:
- hardlink
- 这类文件(A)会有自己的inode节点和名称,其中inode会指向文件内容所在的数据块。该文件内容所在的数据块的引用计数会加1
- 当此数据块的引用计数>=2时,则表示有多个文件同时指向这一类数据块。
- 当删除某个文件时不会对另一个文件有影响,仅仅是数据块的引用计数减一。当引用计数为0时,系统才会清除此数据块。
- 建立一个硬链接
ln 原文件名称 硬链接文件名称

-i显示inode,发现两个文件的inode都相同,说明他们指向了同一块数据块。所以两个文件的内容是一样的
硬链接不允许跨分区来建立,也不允许跨文件系统来建立,同一类型的文件系统也不行,主要是受限于inode指向数据块的名字空间。
硬链接只能在同一个分区内建立
- 建立一个软链接
ln -s 原文件 软链接文件名称

我们发现软链接文件softsource.txt和源文件source.txt的inode号是不一样的,这说明他们指的完全是两个不同的数据块。软链接的权限栏是l。

红色表示警告,说明这是一个有问题的文件,无法找到他所表示的目标文件。
- 创建目录文件
硬链接不允许链接到目录

为什么?
系统中的硬链接有两个限制
不能跨越文件系统
不允许普通用户对目录作硬链接
系统限制对目录进行硬链接只是一个硬性的规定,并不是逻辑上不允许或技术上不可行。
- 对有些目录使用ls -l可以看到它的链接数至少是2,这说明系统中是存在基于目录的硬链接的。
- 命令
ln -d(表示针对目录建立硬链接)也允许root用户尝试对目录做硬链接。为什么?
- 如果引入了对目录的硬链接就有可能在目录中引入***循环链接***,那么在目录遍历的时候会陷入无限循环当中。
- 符号链接不也可以引入循环链接吗,为什么不限制目录的符号链接呢?
- Linux系统中,每个文件(目录也是文件)都对应一个inode结构,其中inode数据结构中包含了文件类型(目录,普通文件,符号链接文件等)的信息,也就是说操作系统在遍历目录的时候可以判断出其是否是符号连接。既然可以判断出它是否是符号链接,当然就可以采取一些措施来防范进入过大过深的循环层次,于是大部分系统会规定在***连续遇到8个符号链接后就停止遍历。***但是对于硬链接,由于操作系统中采用的数据结构和算法限制,目前不能防范这种死循环。
软链接可以


可以通过进入test_two来“进入”test_one
ln -n

如果加上-n

- 系统就会发现软链接重复定义的问题于是就会报错!!!
find 查找目录或文件
要在某个目录下(也包括其子文件夹里)寻找某个具体文件
find [path...] -name [pattern]:可以同时指定多个***要搜索***的文件夹
find . name 文件名称
- 分析一下
.:告诉find命令“我们要在那一个文件夹里进行搜索”。点好表示在当前所在文件夹-name 文件名:表示我们要搜索该文件夹里有没有叫文件名的文件或文件夹
*- 实验

- find会从左到右一次搜索每一个文件夹,如果存在则搜索,如果不存在,则报错并继续搜索下一个文件夹,直到所有文件夹都搜索完成为止。


find可以指定要搜索的对象的类型
文件种类 搜索符号 普通文件 f 目录(文件夹) d 符号链接文件 l 管道文件 p 块设备 b 字符设备 c socket套接字 s
find [path...] -type 类型符号 名称
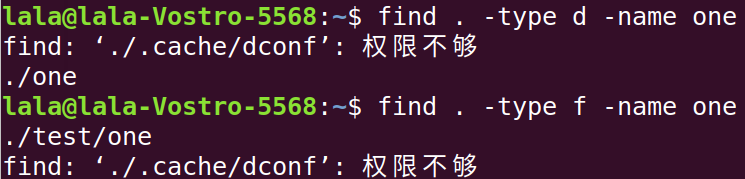
指定文件名后缀
- 找到文件的后缀为".c"的所有普通文件
更加精准的匹配(结合-regex)
- 名字以e开头,名字含有avi子串,名字以数字编号结尾
按属主和属组来搜索
-uesr 选项指定属主
-group 选项指定属组
- 想查找当前目录及子目录下属主是"lala",属组也是"lala"的普通文件
按照权限来搜索
-perm 数字-perm:permission(权限)
-exec ls -l {} \;
声明两点:
{} 和 \ 之间有空格 \ 和 ; 没有空格,如果不这样下会出现这个情况
-l 和 {}之间也必须有空格,否则会出现这样的状况
分析这个用法:
exec的作用就是允许我们将find出来的每一个对象指定为特定shell命令的参数来执行。告诉find我们要针对它搜索到的每一个对象执行特定的shell命令。ls -l便是我们指定的shell命令{}在-exec用法中,{}指代find搜索到的每一个对象\在-exec用法中,分号表示特定shell命令结束,为了防止转义,我们必须在分号前面加上反斜杠( \ )




按时间来搜索文件
序号 参数 含义 1 -mmin± n +(-)n:在n分钟***以前(以内)***文件被修改过 2 -cmin±n +(-)n:在n分钟***以前(以内)***文件状态有过改变 3 -amin±n +(-)n:在n分钟***以前(以内)***文件被访问过 4 -mtime±n 用法和1一样,不过单位是天 5 -ctime±n 用法和2一样,单位是天 6 -atime±n 用法和3一样,单位是天 7 -newer file 搜索修改时间比file文件的修改时间近的 8 -anewer file 搜索访问时间比file文件的访问时间近的 9 -cnewer file 搜索状态变化时间比file文件的状态变化时间近的 10 -newerXY 搜索X时间比file文件的Y时间近的
-newerXY
- 在使用这个选项的时候一定要制定一个参数作为比较的对象,这个参数可以是一个具体的文件,也可以是一个具体的时间值。
- XY其实是两个占位符,可以换成下面的东西
东西 含义 a 访问时间 B 诞生时间(往往只有BSD系统才有) c 状态变化时间 m 修改时间 t 讲所制定的参数理解为一个具体的时间值
- 搜索当前文件夹下修改时间新于one文件的访问时间的普通文件
- 搜索该文件夹下修改时间新于2016-02-14的普通文件
- 搜索该文件夹下修改时间新于2016-02-14 17:44:00的普通文件
关于大小
参数 含义 -size +40M 表示搜索大于40MB的文件 -size -40M 表示搜索小于40MB的文件 -size 40M 表示搜索恰好等于40MB的文件
单位 含义 b 512-byte数据块 c bytes w 两字节的字(words) k KB M MB G GB
- 查找当前目录及子目录下文件大小大于1MB的文件




大家都知道,find命令默认是***会搜索指定文件夹里的子文件夹的,而且是递归向下搜索***
-maxdepth控制搜索的深度
find可以设置多条件
-a表示与关系
- find命令在指定搜索文件夹的参数位置后,就都会被看做表达式
- -type f是一个表达式
- -name "*.c"是另一个表达式
- 用-a连接后组成一个大的表达式
find [路径...]表达式1 表达式2==find[路径...] 表达式1 -a 表达式2


表达式
- (expr):我们可以把一个表达式用小括号括起来,这样可以提升它的处理优先级。
- !expr:我们可以对一个表达式取反,取反后依然是一个表达式。
- expr1 expr2:表示进行与关系处理
- expr1 -a expr2:和上面等价
- expr1 -o expr2:或关系,如果expr1为真,咋不会评估expr2
- expr1,expr2:列表表达式,两个都会被评估,但结果总是expr2的结果
find引出的正则表达式
英文名“Regular Expression”,简写“regex,regexp,RE”
正则表达式—使用单个字符串来描述,匹配一系列符合某个句法规则的字符串
find命令支持使用正则表达式类型的,正则表达式类型有下列几种:
类型 含义 emacs 采用和GNU emacs编辑器兼容的正则表达式。find的默认选项 posix-awk 采用和POSIXawk命令兼容的正则表达式 posix-basic POSIX的基础正则表达式 posix-egrep 和POSIX的egrep命令兼容的正则表达式 posix-eextended POSIX的扩展正则表达式 emacs类型
- emacs不支持字符形式类型的,如[[:digit:]] 类似于[0-9]不被支持
符号 含义 . 匹配除换行之外的任何单个字符 + 代表前面元素出现一次或多次 ? 代表前面元素出现0次或1次 \ +(无空格) 匹配加号 ? 匹配问号 [] 用来表示一组字符集,[0-9]只能正序能[a-z]不能[z-a],在[]中“\”表示他字面的含义 \ |(无空格) 或符号 ^ 匹配某一字符串的开端 $ 匹配某一字符串的结尾
- emacs采用的是贪婪匹配,也就是总会匹配符合条件的最长串。支持一些常见的匹配类型
符号 含义 \w 匹配一个word(即单词,由字母数字下划线) \W 和w相反,用来匹配一个非单词 \ < 匹配一个word的开始 \ > 匹配一个word的结尾 \b 匹配一个word的两端 \B 匹配一个非word的两端 \ ’ 匹配整个输入的结尾 \ ` 匹配整个输入的开头 Posix-awk类型
- 支持字符形式的类型[[:digit:]]表示单个十进制的数字
- ‘\w’,’\W’,’<’,’>’,’\b’,’\B’,’`’,’ \ ’ '没有特殊含义。指代‘w’等
- 分组的话,使用()表示。用“\数字”的形式来指代某个分组。"\2"表示代表第二个括号分组。分组的次序主要取决于左小括号出现的顺序。
- 支持区间匹配,{}表示前一个字符出现的次数范围。
- a{m,n}表示匹配a出现的次数范围为m到n次
- 采用贪婪匹配。总会匹配符合条件的最长串
符号 含义 . 匹配除null之外的任何单个字符 + 代表前面元素出现一次或多次 ? 代表前面元素出现零次或一次 \ + 匹配加号 \ ? 匹配问号 [] 用来代表一组字符集,不能倒序,在[]中反斜线用于转义它后面的字符 | 或符号 ^ 代表一个字符串的开头,如果^出现在[]中,则表示[]中原本只带的字符成员的相反内容。[ ^0-9 ]表示非数字 $ 一个字符串的结尾 posix-basic类型
- 简称BRE Basic Regular Expression
- +和?指代其字面含义,特殊含义要用\ {1,\ }和\ {0,1\ }来代替
- 分组的话用
\(和\)括起来。而后用"\数字"的形式指代某个分组。”\2“表示第二个括号分组。分组的次序主要取决于左小括号出现的顺序。
符号 含义 . 匹配除换行意外的任何单个字符 * 代表前面的元素出现零次或多次 ^ 匹配某一字符串的开端 $ 匹配某一字符串的结尾 \ { \ } 前一字符出现的次数.a \ {m,n\ }表示匹配a出现的次数范围为m到n次 posix-egrep类型
- 支持字符形式的类型[[:digit:]]表示单个十进制的数字
- 分组的话直接使用(),用“\数字”指代某个分组。分组的次序主要取决于左小括号出现的顺序。
- 贪婪匹配,会匹配符合条件的最长串
符号 含义 . 匹配除换行以外的任何单个字符 + 代表前面元素出现一次或多次 ? 代表其前面元素出现零次或一次 \ + 匹配加号 \ ? 匹配问号 [] 用来代表一组字符集,不能倒序,在[]中反斜线用于转义它后面的字符 \ w 匹配一个word \ W 和上面相反 \ < 匹配一个word的开始 \ > 匹配一个word的结尾 \b 匹配一个word的两端 \B 和上面相反 \ ` 匹配整个输入的开头 \ ’ 匹配整个输入的结尾 | 或符号 ^ 代表一个字符串的开头,如果^出现在[]中,则表示[]中原本只带的字符成员的相反内容。[ ^0-9 ]表示非数字 $ 一个字符串的结尾 * 代表零个或多个 + 代表一个或多个 ? 代表0个或一个 {} 前一个字符出现的次数范围。a{m,n}表示匹配a出现的次数范围为m到n次 posix-extended类型
- 支持字符形式的类型[[:digit:]]表示单个十进制的数字
- 分组的话直接使用(),用“\数字”指代某个分组。分组的次序主要取决于左小括号出现的顺序。
- 贪婪匹配,会匹配符合条件的最长串
符号 含义 . 匹配除null之外的任何单个字符 + 前面元素出现一次或多次 ? 前面元素出现0次或1次 \ + 匹配加号 \ ? 匹配问号 [] 用来代表一组字符集,不能倒序,在[]中反斜线用于转义它后面的字符 \ w 匹配一个word \ W 和上面相反 \ < 匹配一个word的开始 \ > 匹配一个word的结尾 \b 匹配一个word的两端 \B 和上面相反 \ ` 匹配整个输入的开头 \ ’ 匹配整个输入的结尾 | 或符号 ^ 代表一个字符串的开头,如果^出现在[]中,则表示[]中原本只带的字符成员的相反内容。[ ^0-9 ]表示非数字 {} 前一个字符出现的次数范围。a{m,n}表示匹配a出现的次数范围为m到n次
- 八大匹配是\w,\W,\ <,\ >,\b,\B,\ `,\ ’
du 磁盘占用
disk usage,用来展示磁盘使用量的统计时间
命令 含义 du 侧重在文件夹和文件的磁盘占用方面 df 侧重在文件系统级别的磁盘占用方面
参数 含义 -s 只显示总和大小 -h 以恰当的K/M/G单位展示 -c 显示文件和文件夹的总和 –max-depth=层数 控制深度 -a 显示所有文件的大小 –exclude=文件 忽略指定的文件
查看当前所在文件夹的总磁盘占用量
-s:–summarize
-h:–human-readable
-c:显示文件和文件夹的总和(通常计算某一段时间范围内的日志文件的磁盘使用量)
注意区别
- 当
--max-depth=0时,只显示当前文件夹的总大小




-a:隐藏文件也会显示出来
du只会关心文件夹,输出的都是文件夹的空间使用量,而不会关注单个文件。所以想让他关注单个文件
- 通过参数形式直接指定
- 通过-a
如果想要忽略一些文件?
- 可以使用正则匹配
和sort结合
- 想查看当前文件夹下第一级的大小排序
- 想看当前文件夹和其子文件夹的大排序




单位
- 默认单位是KB,1024bytes
- 如果你通过
--block-size选项设置了块大小,那么这就会成为你du输出信息的单位- 加入上一条没有满足,且你设置了环境变量DU_BLOCK_SIZE,则这会成为你du输出信息的单位
- 上两个都没有,且你设置了环境变量BLOCK_SIZE,则这会成为你du输出信息的单位
- 前三个都没有,且你设置了环境变量BLOCKSIZE,则这会成为你du输出信息的单位
- 前四个都没有,你开启了环境变量POSIXLY_COR-RECT,则du输出信息的单位会是512bytes
- 前五个都不,du输出的单位是1024bytes,就是KB
关于du和ls
why?
含义 du 磁盘空间占用量 ls 文件内容的大小
- 月饼礼盒,月饼的体积可以认为是文件内容的大小,加上包装礼盒的总体积可以认为是磁盘空间使用量
- 文件需要包装吗?
- Linux文件系统的原理
- 文件系统进驻磁盘之处,就会将磁盘按照固定数据块大小进行分割切块,通常情况下每一个固定数据开大小会被设定为4096bytes,也就是4KB
- 规定:
- 一个数据块最多存放一个文件的内容,当没存满时,剩余的空间不得被其他文件使用
- 当一个文件的内容比较大时可以存储到多个数据块中
- 所以:
- myword中有三个字符,两个可见字符和一个控制字符。因此这个文件的内容大小就是3bytes,但是限于Linux文件系统的控制,他需要占用一个数据块来存储这个文件。因此这个文件实际占用的磁盘空间就是4KB。
- 这种情况使du比ls大
- 还有小的情况
- “空洞”可以让一个文件的ls输出值很大,但du的输出值很小
dd命令

- 因为一个文件的空洞并不实际占用磁盘空间,但是这个空洞本身会被认为是文件内容的一部分。一个存在空洞的文件叫“稀疏文件”,“sparse file”,本质是由文件偏移来控制的


