参考视频:阳哥带你学spring cloud
代码地址:https://github.com/PhoenixXC/LearnJava/tree/master/SpringCloud/ShangGuiGu
准备
版本对应关系
浏览器访问:https://start.spring.io/actuator/info
可以获得版本的详细对应关系

视频版本推荐
| 组件 | 版本 |
|---|---|
| cloud | Hoxton.SR1 |
| boot | 2.2.2.RELEASE |
| cloud alibaba | 2.1.0.RELEASE |
| Java | Java 8 |
| Maven | 3.5+ |
| MySQL | 5.7+ |
Cloud 停更
- 被动修复 bugs
- 不接受合并请求
- 不再发布新版本

资料
查看官网文档/社区中文版。
架构搭建
- 约定 > 配置 > 编码
微服务模块的创建
- 建立 module
- 修改 pom
- 编写 YML
- 主启动
- 业务类
热部署的开启
热部署在开发阶段中使用,不要在生产环境中使用
项目中添加 devtools
1
2
3
4
5
6
7<!-- pom.xml -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>在 pom.xml 中添加插件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<!-- pom.xml -->
<build>
<finalName>cloud-provider-payment8001</finalName>
<plugins>
<!-- 热部署 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<fork>true</fork>
<addResources>true</addResources>
</configuration>
</plugin>
</plugins>
</build>启用 automatic build

更新值
Idea 中 CTRL+SHIFT+ALT+/ :

点击 Registry
将框住的选项打钩

重启 IDEA
服务治理
服务治理:
管理服务之间的依赖关系,可以实现服务调用,负载均衡、容错等,实现服发现和注册
Eureka
集群原理
Eureka Server
服务注册
将服务信息注册进注册中心
服务发现
从注册中心上获取服务信息,实质:存
key服务名,取value调用地址
Service Provider
- 先启动 eureka 注册中心
- 启动服务提供者
- 服务提供者将自身的信息注册进 eureka
Service Consumer
- 消费者在需要调用接口时,使用服务别名去注册中心获取实际的 RPC 远程调用地址
- 消费者获取调用地址后,底层利用
HttpClient技术实现远程调用 - 消费者获取服务地址后会缓存在本地 Jvm 内存中,默认每隔 30 秒更新一次服务调用地址
自我保护机制
原因:
- 某时刻某一个微服务不可用了,Eureka 不会立刻清理,依旧会保留微服务信息
- CAP 理论中的 AP 分支
如何关闭:
yml中设置eureka.server.eable-self-preservation=false
Zookeeper
引入 zookeeper-discovery
排除自带的 zookeeper,引入版本合适的 zookeeper
yml文件配置
1
2
3
4
5
6
7spring:
application:
# 微服务注册名称
name: cloud-payment-service
cloud:
zookeeper:
connect-string: 169.22.2.2:2181SpringBoot 启动类加上注解:
@EnableDiscoveryClient
启动服务后,在 /services 下面会有有服务名称相同的节点,里面有一个临时节点存储了服务注册的信息。
Zookeeper 没有自我保护机制
Consul
Go 语言编写
作用
- 服务注册
- 健康检查
- KV存储
- 安全
- 多数据
三个注册中心异同
| 组件 | 语言 | CAP | 服务健康检查 | 对外暴露端口 | SpringCloud集成 |
|---|---|---|---|---|---|
| Eureka | Java | AP | 可配 | HTTP | 集成 |
| Consul | Go | CP | 支持 | HTTP/DNS | 集成 |
| Zookeeper | Java | CP | 支持 | 客户端 | 集成 |


负载均衡
关于
什么是负载均衡
将用户的请求平摊的分配到多个服务上,从而达到系统的 HA (高可用)。
常见的负载均衡有软件 Nginx,LVS,硬件 F5 等
本地负载均衡客户端 vs Nginx 服务端负载均衡
Nginx 是服务器负载均衡,客户端说起有请求都会交给 Nginx,然后由 Nginx 实现请求转发。
Ribbon 本地负载均衡,在调用微服务接口的时候,会在注册中心上获取注册信息服务列表之后缓存到 JVM 本地,从而在本地实现 RPC 远程服务调用技术。
集中式 vs 进程内
集中式
在服务的消费方和提供方之间使用独立的 LB 设施,由该设施负责把访问请求通过某种策略转发至服务的提供方。
进程内
将 LB 集成到消费方
Ribbon
Ribbon 是一个软负债均衡的客户端组件,可以和其他客户端配合使用。

工作分为两步:
- 先选择 EurekaServer,优先选择在同一个区域内负债较少的 server
- 根据用户指定的策略,在从 server 取到的服务注册列表中选择一个地址。
Ribbon 提供了多种策略,轮训、随机和根据响应时间加权等
引入 Eureka 的时候,默认引入了 Ribbon
IRule
Ribbon 内置了很多负载均衡策略:


替换负载均衡算法
创建自定义配置
自定义配置类不能放在
@CompoentScan所扫描的包以及子包下,否则这个自定义的配置类就会被所有的 Ribbon 客户端共享,达不到特殊化定制的目的。1
2
3
4
5
6
7
8
9
public class MySelfRule {
public IRule myRule() {
return new RandomRule();
}
}主启动类添加
@RibbonClient1
2
3
4
5
6
7
8
9
10
(name = "CLOUD-PAYMENT-SERVICE", configuration = MySelfRule.class)
public class OrderMain80 {
public static void main(String[] args) {
SpringApplication.run(OrderMain80.class);
}
}
负载均衡算法原理
轮训
rest 接口第几次请求数 % 服务器集群总数量 = 实际调用服务器位置下标,每次服务重启后 rest 从1开始计数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77private AtomicInteger nextServerCyclicCounter;
private static final boolean AVAILABLE_ONLY_SERVERS = true;
private static final boolean ALL_SERVERS = false;
private static Logger log = LoggerFactory.getLogger(RoundRobinRule.class);
public RoundRobinRule() {
nextServerCyclicCounter = new AtomicInteger(0);
}
public RoundRobinRule(ILoadBalancer lb) {
this();
setLoadBalancer(lb);
}
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
log.warn("no load balancer");
return null;
}
Server server = null;
int count = 0;
while (server == null && count++ < 10) {
List<Server> reachableServers = lb.getReachableServers();
List<Server> allServers = lb.getAllServers();
int upCount = reachableServers.size();
int serverCount = allServers.size();
if ((upCount == 0) || (serverCount == 0)) {
log.warn("No up servers available from load balancer: " + lb);
return null;
}
int nextServerIndex = incrementAndGetModulo(serverCount);
server = allServers.get(nextServerIndex);
if (server == null) {
/* Transient. */
Thread.yield();
continue;
}
if (server.isAlive() && (server.isReadyToServe())) {
return (server);
}
// Next.
server = null;
}
if (count >= 10) {
log.warn("No available alive servers after 10 tries from load balancer: "
+ lb);
}
return server;
}
/**
* Inspired by the implementation of {@link AtomicInteger#incrementAndGet()}.
*
* @param modulo The modulo to bound the value of the counter.
* @return The next value.
*/
private int incrementAndGetModulo(int modulo) {
for (;;) {
int current = nextServerCyclicCounter.get();
int next = (current + 1) % modulo;
if (nextServerCyclicCounter.compareAndSet(current, next))
return next;
}
}
public Server choose(Object key) {
return choose(getLoadBalancer(), key);
}
手写负载均衡算法
原理 + JUC(CAS + 自旋锁)
服务调用
OpenFegin
Fegin 是一个声明式的 WebService 客户端,使用 Fegin 可以让客户端更加简单。
使用方法:定义一个服务接口然后在上面添加注解,支持可拔插式的编码器和解码器。
SpringCloud 对 Fegin 进行了封装,使其支持 Spring MVC 标准注解和 HttpMessgaeConverts。Fegin 可以与 Eureka 和 Ribbon 组合使用以支持负载均衡

超时设置
1 | feign: |
日志
官网文档有,yml 中配置 config 或创建一个 config bean
服务降级
Hystrix
目前停更,但是用处很多,非常重要
resillience4j
国外用的多
sentinel
ali牛掰
复制分布式系统结构中的应用有数十个依赖关系,每个依赖关系在某些时候将不可避免的失败

服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的“扇出”。
如果扇出的链路上某个微服务的调用响应时间过长或不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,导致“雪崩效应”。

服务降级(fallback)
导致服务降级的原因:
程序运行异常
超时
服务熔断触发服务降级
线程池/信号量打满也会导致服务降级
服务熔断(break)
达到最大服务访问后,直接决绝访问,调用服务降级的方法返回友好提示。
服务限流(flowlimit)
秒杀高并发等操作,严禁一起来,先排队,一秒n个,有序进行
Hystrix

做用
服务降级
服务熔断
接近实时监控
服务降级 Pratice

使用注解 @HystrixCommand
8001
设置自身调用时间的峰值,峰值内可以正常运行
超过了需要有兜底的方法处理,作服务降级 fallback
服务端:
主启动类上添加:@EnableCircuitBreaker
服务上添加
1 | (fallbackMethod = "paymentInfoTimeoutHandler", commandProperties = { |
不管是运行超时还是服务异常,都会使用 fallback
服务降级既可以加在客户端,也可以加载服务端,一般加载客户端

客户端:
主启动类加上注解:@EnableHystrix
服务上:
1 | (fallbackMethod = "paymentInfoTimeoutFallbackMethod", commandProperties = { |
存在的问题:
- Fallback 代码与业务代码耦合
- 代码膨胀
解决方式:
大部分用通用 Fallback,类上配置注解:@DefaultProperties(defaultFallback = "paymentTimeoutFallbackMethod")
需要降级的方法上直接 @HystrixCommand
通用 Fallback 的返回值要兼容,且不能有参数
同时为了处理代码耦合,由于需要降级处理的都是来自 OpenFeign 的那个接口,所以可以让 Feign 开启 Hyxtrix,实现该接口,并在接口注解上指定实现类作为 fallback
1 |
|
1 |
|
1 | # feign 开启 hystrix |
这样当失败时,会调用指定的接口实现类中对应的方法,而且不会处理htstrixCommand指定的的fallback。
服务熔断

三种状态:



断路器起作用的条件:

如果断路器开启:

进入半开启:


Hystrix Dashboard
都要添加 actutor 依赖

被监控服务注入一个bean
1
2
3
4
5
6
7
8
9
10
11
12/**
* 配置服务器监控默认路径
*/
public ServletRegistrationBean getServlet() {
HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);
registrationBean.setLoadOnStartup(1);
registrationBean.addUrlMappings("/hystrix.stream");
registrationBean.setName("HystrixMetricsStreamServlet");
return registrationBean;
}打开监控页面,输入服务url:hystrix.stream

服务网关
zuul 停更,计划 zuul2,3名作者被挖走,大佬撕逼,导致 zuul2 夭折,Spring 社区受不了自己弄了 gateway。
Gateway


作用
- 反向代理
- 鉴权
- 流量控制
- 熔断
- 日志监控

优势
Neflix 一直跳票,Gateway 由 SpringCloud 研发,集成度更好。
Gateway 基于异步非阻塞模型开发,性能优秀。



Zuul 模型


Gateway
使用了 WebFlux :

路由(Route)
是构建网关的基本模块,由 ID、目标 URI、一系列的断言和过滤器组成,如果断言为 true 则匹配该路由。
断言(Predicate)
参考 Java8 的 java.util.function.Predicate
开发人员可以匹配 HTTP 请求中的所有内容(如请求参数和请求头),如果请求与断言相匹配则进行路由
过滤(Filter)
指的是 Spring 框架中 GateFilter 的实例,使用过滤器,可以在请求被路由前或路由后进行修改。

Gateway 工作流程

 核心逻辑:路由转发 +执行过滤器链
核心逻辑:路由转发 +执行过滤器链
配置
导入 Gateway
移除 starter-web 这个包,如果需要 web 支持,可以导入 starter-webflux
配置(静态)
yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15spring:
application:
name: cloud-gateway
cloud:
gateway:
routes:
- id: payment_routh # 路由ID,要求唯一,建议配合服务名
uri: http://localhost:8001 # 匹配后提供的路由地址
predicates:
- Path=/payment/get/** # 断言
- id: payment_routh # 路由ID,要求唯一,建议配合服务名
uri: http://localhost:8001 # 匹配后提供的路由地址
predicates:
- Path=/payment/lb/**创建Bean
1
2
3
4
5
6
7
8
9
public RouteLocator customRouteLocator(RouteLocatorBuilder routeLocatorBuilder) {
RouteLocatorBuilder.Builder routes = routeLocatorBuilder.routes();
routes.route("path_route_xcphoenix",
r -> r.path("/guonei")
.uri("https://news.baidu.com/"));
return routes.build();
}
配置(动态)
静态路由会写死 url,但是多数情况下是要部署集群的,这就需要通过微服务名实现动态路由

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21spring:
application:
name: cloud-gateway
cloud:
gateway:
discovery:
locator:
# 开启从注册中心动态创建路由的功能,利用微服务名进行路由
enabled: true
routes:
- id: payment_routh # 路由ID,要求唯一,建议配合服务名
# uri: http://localhost:8001 # 匹配后提供的路由地址
uri: lb://CLOUD-PAYMENT-SERVICE # 匹配后提供微服务的路由地址
predicates:
- Path=/payment/get/** # 断言
- id: payment_routh2 # 路由ID,要求唯一,建议配合服务名
# uri: http://localhost:8001 # 匹配后提供的路由地址
uri: lb://CLOUD-PAYMENT-SERVICE
predicates:
- Path=/payment/lb/** # 断言
Predicate
官方提供了很多 Predicate:


Filter

自定义:
1 |
|
服务配置
Config





The HTTP service has resources in the following form:
1 | /{application}/{profile}[/{label}] |
where application is injected as the spring.config.name in the SpringApplication (what is normally application in a regular Spring Boot app), profile is an active profile (or comma-separated list of properties), and label is an optional git label (defaults to master.)

不管是
.yml还是.properties都可以通过 xxxx.yml 或 xxxx.properties。其中
/{application}/{profile}[/{label}]这种格式返回的是一个json字符串其他四种返回的都是对应的文件内容
如果访问一个不存在的配置,那么返回一个表示错误的
json字符串
服务端配置
maven
1
2
3
4
5<!-- Config -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>yml
1
2
3
4
5
6
7
8
9spring:
application:
name: cloud-config-center
cloud:
config:
server:
git:
uri: /home/xuanc/桌面/LearnJava/SpringCloud/ShangGuiGu/springcloud-config
label: master可以使用 git 或者文件路径,git 可以需要配置用户名和密码,git 地址,仓库名等
客户端配置
maven
1
2
3
4
5
6<!-- 写错就是一个坑 -->
<!-- Config -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>配置
bootstrap.yml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17server:
port: 3355
spring:
application:
name: config-client
cloud:
config:
label: master
name: config
profile: dev
uri: http://config3344:3344
eureka:
client:
server-url:
defaultZone: http://eureka7001:7001/eurekacode
1
2
3
4
5
6
7
8
9
10
11
12
public class ConfigController {
("${config.info}")
private String configInfo;
("/configInfo")
public String getConfigInfo() {
return configInfo;
}
}config.info来自 config-server 中配置的信息(git或文件中的数据),客户端通过配置向服务端发送请求,获取到:1
2> {"name":"config","profiles":["dev"],"label":"master","version":"e7b77b33bada2e2812236072305022642242c58b","state":null,"propertySources":[{"name":"/home/xuanc/桌面/LearnJava/SpringCloud/ShangGuiGu/springcloud-config/config-dev.yml","source":{"config.info":"master branch,springcloud-config/config-dev.yml version=1"}}]}
>并取出其中的 propertySources 与添加到客户端的环境属性中,这样客户端可以直接通过
config.info去访问配置信息
boostrap.yml
application.yml 是用户级
bootstrap.yml 是系统级的,优先级更高

配置刷新
当文件发生变化后(git 需要 commit 才行),服务端可以感知到变化并更新配置,客户端不能立马感知。
设置动态刷新:
引入
actuator模块暴露监控端点
1
2
3
4
5management:
endpoints:
web:
exposure:
include: "*"控制类加上
@RefreshScope发送 POST 刷新
http://localhost:3355/actuator/refresh
缺点:
- 不能广播,批量刷新,同时保证精确刷新
消息总线
Bus
为了解决上面的动态刷新的问题,引入了 SpringCloud Bus


第二种架构更加合适,第一种:
- 破坏了微服务的职责单一性,微服务本身是业务模块,不应该承担配置刷新的职责
- 破坏了微服务各节点的对等性
- 有一定的局限性,比如当微服务迁移时,网络地址和常常会发生变化

Bus 支持两种 MQ:RabbitMQ、Kafka
Config自动刷新步骤
基于上面的手动刷新
添加依赖
1
2
3
4
5<!-- Bus: RabbitMQ -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-amqp</artifactId>
</dependency>需要amqp以及actuator依赖
yaml 配置 RabbitMQ
1
2
3
4
5
6# 配置rabbitmq
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
前两部分服务端和客户端都要配置
服务端暴露端点
1
2
3
4
5
6# rabbitmq相关配置,暴露bus刷新配置的端点
management:
endpoints:
web:
exposure:
include: '*'POST 请求:
http://ip:port/actuator/bus-refresh这样就可以自动刷新客户端的配置(控制器要有
@RefreshScope)
定点通知
在上面配置完成后,如果需要定点刷新,可以发送 POST /actuator/bus-refresh/{destination}
服务端收到请求后,会通过参数来指定需要更新配置的服务或实例
Cloud Stream
常用的 MQ(消息中间件)
- ActiveMQ
- RabbitMQ
- RocketMQ
- Kafka
MQ 太多,如果服务用到多个 MQ,那么切换、维护、开发都会带来困难
所以需要一种适配绑定的方式,自动的在各种 MQ 切换
那么 springcloud stream 就可以屏蔽 MQ 的细节
概述
是什么
屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型。
Spring Cloud Stream 是一个构建消息驱动微服务的框架。
应用程序通过 inputs 和 outputs 来与 Spring Cloud Stream 中 binder 对象交互
所以,只需要搞清楚如何与 Spring Cloud Stream 交互就可以方便使用消息驱动的方式。
通过使用 Spring Integration 来连接消息代理中间件以实现消息事件驱动。
Spring Cloud Stream 为一些供应商的消息中间件产品提供了个性化的自动化配置实现,引发了发布-订阅、消费组、分区的三个核心概念。
目前仅支持:RabbitMQ、Kafka
Binder 绑定器是屏蔽 MQ 的核心
设计思想
标准MQ
生产者/消费者之间靠消息媒介传递消息内容:Message
消息必须走特定的通道:消息通道MessageChannel
消息通道里的消息如何被消费,谁负责收发消息:消息通道的子接口 SubscribableChannel,由 MessageHandler 消息处理器所订阅
为什么用Cloud Stream
如果用到了多个 MQ,多个 MQ 的架构不同,直接使用会导致代码耦合,切换和适配就十分困难。

通过定义绑定器 Binder 作为中间层,实现了应用程序和消息中间件细节之间的隔离
Binder
INPUT
消费者
OUTPUT
生产者


通信方式
发布——订阅模式,使用 Topic 主题广播(RabbitMQ -> Exchange,Kafka -> Topic)
使用方法
组成
Binder
连接中间件,屏蔽差异
Channel
通道,是队列 Queue 的一种抽象,在消息通讯系统中就是实现存储和转发的媒介,通过 Channel 对队列进行配置
可以理解为参照对象是 Spring Cloud Stream 自身,从 Stream 发布消息就是输出,接受消息就是输入
常用注解

USE
导入依赖
1
2
3
4
5<!-- MQ -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>Yaml 配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29spring:
application:
name: cloud-stream-provider
cloud:
stream:
# 配置需要绑定的 rabbitmq 的服务信息
binders:
# 表示定义的名称,用于 binding 整合
defaultRabbit:
# 消息组件类型
type: rabbit
# mq 环境配置
enviroment:
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
# 服务资源整合
bindings:
# 通道名,消费端为input
output:
# 要使用的 Exchange 名称
destination: studyExchange
# 消息类型
content-type: application/json
# 设置绑定的消息服务的具体设置
binder: defaultRabbit生产者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 定义消息的推送管道
(Source.class)
public class MessageProviderImpl implements IMessageProvider {
/**
* 消息发送管道
*/
private MessageChannel output;
public String send() {
String serial = UUID.randomUUID().toString();
// 发送
output.send(MessageBuilder.withPayload(serial)
.build());
log.info("----> serial: " + serial);
return null;
}
}消费者
1
2
3
4
5
6
7
8
9
10
11
12
13
144j
(Sink.class)
public class ReceiveMessageController {
("${server.port}")
private String serverPort;
(Sink.INPUT)
public void input(Message<String> message) {
log.info("receive: " + message.getPayload() + "\t port: " + serverPort);
}
}泛型和生产者类型要匹配
分组消费和持久化
重复消费
如果有多个消费端,会出现消息被重复消费的问题;
这种就需要用到 消息分组 才解决,在 Stream 中,处于同一个 group 的多个消费者是竞争关系,能够保证消息只会被其中一个应用消费一次。
==不同组是可以重复消费的,同一个组存在竞争关系。==
不配置的话,默认情况下 group 是不同的
设置分组的方法:
修改 yaml 配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31spring:
application:
name: cloud-stream-consumer
cloud:
stream:
# 配置需要绑定的 rabbitmq 的服务信息
binders:
# 表示定义的名称,用于 binding 整合
defaultRabbit:
# 消息组件类型
type: rabbit
# mq 环境配置
enviroment:
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
# 服务资源整合
bindings:
# 通道名
input:
# 要使用的 Exchange 名称
destination: studyExchange
# 消息类型
content-type: application/json
# 设置绑定的消息服务的具体设置
binder: defaultRabbit
#设置分组
group: groupA这样只需要将同一应用的不同实例设置为同一个组就可避免单独消费
持久化:
- 没有配置 group,会导致错过消息
链路追踪
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的服务节点调用来协同产生最后的结果请求,每一个前端请求都会形成一条复杂的分布式服务调用链路,链路中任何一环出现高延时或错误都会引起请求最后的失败。
所以需要一套跟踪的框架去追踪。
Sleuth & Zipkin
Sleuth 复制搜集,zipkin 图像化呈现


Zipkin
1 | curl -fL -o 'zipkin.jar' 'https://repo1.maven.org/maven2/io/zipkin/zipkin-server/2.21.1/zipkin-server-2.21.1-exec.jar' |
浏览器打开 localhost:9411/zipkin
使用
添加依赖
1
2
3
4
5<!-- Sleuth & zipkin -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>配置 yaml
1
2
3
4
5
6
7spring:
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
# 采样率值介于 0 ~ 1,1表示全部收集
probability: 1
Nacos
Nacos(Naming, Configuration,Service)
概述
是什么
注册中心+配置中心 <==> Eureka + Config + Bus(注册+配置+总线)
作用
- 服务注册中心
- 服务配置中心
注册中心比较


Nacos 支持 CP 和 AP 的切换

安装运行
环境:Java8 + Maven
从 最新稳定版本 下载 nacos-server-$version.zip 包。
1 | unzip nacos-server-$version.zip 或者 tar -xvf nacos-server-$version.tar.gz |
Linux/Unix/Mac
启动命令(standalone代表着单机模式运行,非集群模式):
1 | sh startup.sh -m standalone |
如果您使用的是ubuntu系统,或者运行脚本报错提示[[符号找不到,可尝试如下运行:
1 | bash startup.sh -m standalone |
浏览器打开:http://localhost:8848/nacos/
用户名和密码都是:nacos
服务注册&发现和配置管理
服务注册
1 | curl -X POST 'http://127.0.0.1:8848/nacos/v1/ns/instance?serviceName=nacos.naming.serviceName&ip=20.18.7.10&port=8080' |
服务发现
1 | curl -X GET 'http://127.0.0.1:8848/nacos/v1/ns/instance/list?serviceName=nacos.naming.serviceName' |
发布配置
1 | curl -X POST "http://127.0.0.1:8848/nacos/v1/cs/configs?dataId=nacos.cfg.dataId&group=test&content=HelloWorld" |
获取配置
1 | curl -X GET "http://127.0.0.1:8848/nacos/v1/cs/configs?dataId=nacos.cfg.dataId&group=test |
服务注册
Nacos 默认支持负载均衡
服务端
启动服务
客户端
父项目添加依赖管理
1
2
3
4
5
6
7
8<!-- spring cloud alibaba 2.1.0.RELEASE -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.1.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>添加依赖
1
2
3
4<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>配置 yaml
1
2
3
4
5
6
7
8
9
10
11
12
13spring:
application:
name: nacos-payment-provider
cloud:
nacos:
discovery:
server-addr: localhost:8848
management:
endpoints:
web:
exposure:
include: '*'启用服务发现
主启动类加上注解:
@EnableDiscoveryClient服务调用
创建 RestTemplate bean,还需要加上
@LoadBalance注解添加负载均衡,使用服务名来调用服务Consumer 的应用可能还没像启动一个 Provider 应用那么简单。因为在 Consumer 端需要去调用 Provider 端提供的REST 服务。例子中我们使用最原始的一种方式, 即显示的使用 LoadBalanceClient 和 RestTemolate 结合的方式来访问。 pom.xml 和 application.properties 的配置可以参考 1.2 小结。启动一个 Consumer应用的示例代码如下所示:
Note 通过带有负载均衡的RestTemplate 和 FeignClient 也是可以访问的。
基础配置
添加依赖
1
2
3
4
5
6
7
8
9
10<!-- Nacos Config -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!-- Nacos 服务发现 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>修改 YAML 配置
Nacos 与 springcloud-config 一样,在项目初始化时,要先保证从配置中心进行配置拉取
拉取配置后,才能保证项目的正常启动。
springboot 配置文件的加载存在优先级,bootstrap 优先级高于 application
bootstrap.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15server:
port: 3377
spring:
application:
name: nacos-config-client
cloud:
nacos:
discovery:
server-addr: localhost:8848
config:
# Nacos 作为配置中心地址
server-addr: localhost:8848
# 指定为 yaml 格式
file-extension: yamlapplication.yml
1
2
3
4# 设置环境
spring:
profiles:
active: dev
启动类
与服务注册相同,使用 springcloud 原生注解
动态刷新
@Controller上添加@RefreshScope在 Nacos 管理界面更新配置信息后,客户端可以直接感知到配置文件的变化
Data ID 命名:
在 Nacos Spring Cloud 中,
dataId的完整格式如下:
2
>
prefix默认为spring.application.name的值,也可以通过配置项spring.cloud.nacos.config.prefix来配置。spring.profile.active即为当前环境对应的 profile,详情可以参考 Spring Boot文档。 注意:当spring.profile.active为空时,对应的连接符-也将不存在,dataId 的拼接格式变成${prefix}.${file-extension}file-exetension为配置内容的数据格式,可以通过配置项spring.cloud.nacos.config.file-extension来配置。目前只支持properties和yaml类型。
分类配置

Nacos 类似与 Java 里面的 package 和 类名,最外层的 namespace 可以区分部署环境,Group 和 DataID 逻辑上区分两个目标对象。

默认情况:Namespace=public,Group=DEFAULT_GROUP,Cluster=DEFAULT
- Namspace 主要用来实现隔离,比如有开发、测试、生产环境,就可以创建三个 Namespace,不同的 Namespace 之间是隔离的;
- Group 可以把不同的微服务划分到同一个分组里面去;
- Service 就是微服务,一个 Service 可以包含多个 Cluster,Cluster 是对指定微服务的一个虚拟划分
Nacos概念 https://nacos.io/zh-cn/docs/concepts.html
命名空间
用于进行租户粒度的配置隔离。不同的命名空间下,可以存在相同的 Group 或 Data ID 的配置。Namespace 的常用场景之一是不同环境的配置的区分隔离,例如开发测试环境和生产环境的资源(如配置、服务)隔离等。
配置集 ID
Nacos 中的某个配置集的 ID。配置集 ID 是组织划分配置的维度之一。Data ID 通常用于组织划分系统的配置集。一个系统或者应用可以包含多个配置集,每个配置集都可以被一个有意义的名称标识。Data ID 通常采用类 Java 包(如 com.taobao.tc.refund.log.level)的命名规则保证全局唯一性。此命名规则非强制。
配置分组
Nacos 中的一组配置集,是组织配置的维度之一。通过一个有意义的字符串(如 Buy 或 Trade )对配置集进行分组,从而区分 Data ID 相同的配置集。当您在 Nacos 上创建一个配置时,如果未填写配置分组的名称,则配置分组的名称默认采用 DEFAULT_GROUP 。配置分组的常见场景:不同的应用或组件使用了相同的配置类型,如 database_url 配置和 MQ_topic 配置。
DataID
指定spring.profile.active 和配置文件的 DataID 来使不同环境下读取不同的配置
Group
在配置文件中可以指定 group
1 | spring: |
Namespace
1 | spring: |
集群
集群模式部署
这个快速开始手册是帮忙您快速在你的电脑上,下载安装并使用Nacos,部署生产使用的集群模式。
集群部署架构图
因此开源的时候推荐用户把所有服务列表放到一个vip下面,然后挂到一个域名下面
VIP:虚拟IP,例如 Nginx 集群
http://ip1:port/openAPI 直连ip模式,机器挂则需要修改ip才可以使用。
http://VIP:port/openAPI 挂载VIP模式,直连vip即可,下面挂server真实ip,可读性不好。
http://nacos.com:port/openAPI 域名 + VIP模式,可读性好,而且换ip方便,推荐模式
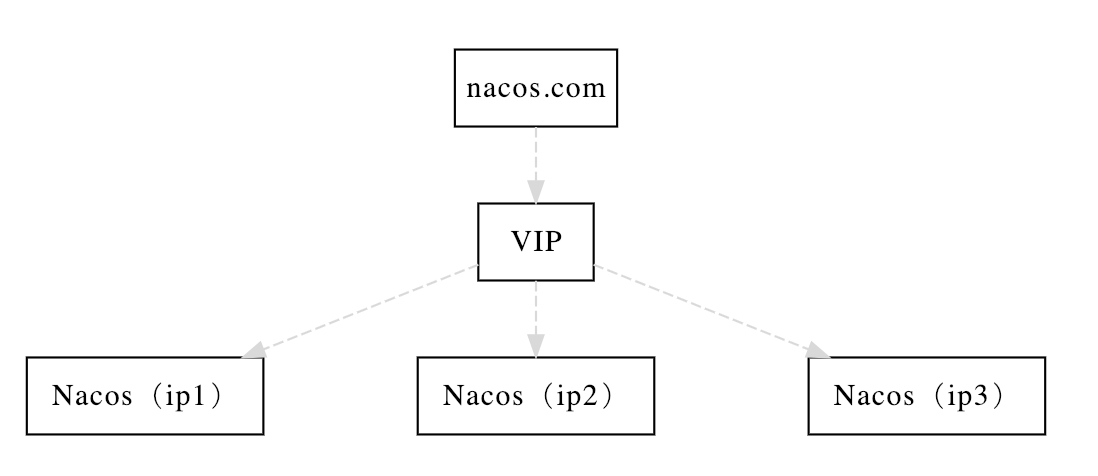
Nacos 默认使用嵌入式数据库(derby)保存数据,如果启动多个默认配置的 Nacos 节点,数据存储存在一致性问题,为了解决这个问题,Nacos 采用了集中式存储的放啊是来支持集群化部署,目前只支持 MySQL 的存储。
部署
部署 Nacos 集群
Clone 项目,进入根目录
1
2git clone https://github.com/paderlol/nacos-docker.git
cd nacos-docker修改配置
example/cluster-ip.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44version: "2"
services:
nacos1:
image: nacos/nacos-server:latest
container_name: nacos1
# 指定网络名和ip
networks:
Utils:
ipv4_address: 169.1.0.6
volumes:
- ./cluster-logs/nacos1:/home/nacos/logs
env_file:
- ../env/nacos-ip.env
restart: on-failure
nacos2:
image: nacos/nacos-server:latest
container_name: nacos2
networks:
Utils:
ipv4_address: 169.1.0.7
volumes:
- ./cluster-logs/nacos2:/home/nacos/logs
env_file:
- ../env/nacos-ip.env
restart: always
nacos_netcos3:
image: nacos/nacos-server:latest
container_name: nacos3
networks:
Utils:
ipv4_address: 169.1.0.8
volumes:
- ./cluster-logs/nacos2:/home/nacos/logs
env_file:
- ../env/nacos-ip.env
restart: always
networks:
Utils:
# 引入外部网络,默认是创建了一个新的网络
external:
name: Utilsenv/nacos-ip.env
1
2
3
4
5
6
7
8#nacos dev env
#配置集群ip、mysql信息
NACOS_SERVERS=169.1.0.6:8848 169.1.0.7:8848 169.1.0.8:8848
MYSQL_SERVICE_HOST=172.17.0.1
MYSQL_SERVICE_DB_NAME=nacos_config
MYSQL_SERVICE_PORT=3306
MYSQL_SERVICE_USER=root
MYSQL_SERVICE_PASSWORD=mysqlpass拉取进行生成容器
1
docker-compose -f example/cluster-ip.yaml up
配置 Nginx
使用 docker 创建镜像,并设置容器的网络ip
配置 nginx
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58# 设置nacos集群ip
upstream cluster {
server 169.1.0.6:8848;
server 169.1.0.7:8848;
server 169.1.0.8:8848;
}
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log /var/log/nginx/host.access.log main;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
# 匹配路径,设置代理到集群上
location /nacos {
#root /usr/share/nginx/html;
#index index.html index.htm;
proxy_pass http://cluster/nacos;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
最后nacos的yaml配置中直接填nginx ip就可以
Sentinel
概述
Hystrix:
- 需要手动搭建平台
- 没有 Web 界面可以细粒度化配置
Sentinel:
- 单独的一个组件
- web 界面配置
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Sentinel 具有以下特征:
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
- 完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
- 广泛的开源生态:Sentinel 提供开gaishu箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
- 完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
Sentinel 的主要特性:

简单来说,Sentinel 的功能:
- 服务雪崩
- 服务降级
- 服务熔断
- 服务限流
组成
- 核心库(Java客户端),不依赖于任何框架/库,能够运行于所有的 Java 环境
- 控制体(Dashboard),基于 Spring Boot 开发,可以直接运行
安装
jar 包地址:https://github.com/alibaba/Sentinel/releases,下载 dashboard
使用
服务端
运行 jar 包
客户端
添加依赖
1
2
3
4
5
6
7
8
9
10<!-- sentinel -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
<!-- 后续做持久化 -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>yaml 配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
server-addr: localhost:8848
sentinel:
transport:
dashboard: localhost:12345
# 默认8719,如果被占用会自动从8719开始+1扫描
port: 8719
# 监控
management:
endpoints:
web:
exposure:
include: '*'编写 controller 并访问,就可以看到 sentinel 控制台显示的信息
sentinel 是懒加载,只有当访问了之后才会显示出来
流量控制(流控,flow control)
Doc: 流量控制
概述
流量控制(flow control),其原理是监控应用流量的 QPS 或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。
一条限流规则主要由下面几个因素组成,我们可以组合这些元素来实现不同的限流效果:
resource:资源名,即限流规则的作用对象count:限流阈值grade: 限流阈值类型(QPS 或并发线程数)limitApp: 流控针对的调用来源,若为default则不区分调用来源strategy: 调用关系限流策略controlBehavior: 流量控制效果(直接拒绝、Warm Up、匀速排队)
流控模式
设置
资源名
唯一资源,默认请求路径
针对来源
Sentinel 可以针对调用者进行限流,填写服务名,默认 default(不区分来源)
阈值类型/单机阈值
QPS(每秒的请求数量)
当调用该 api 的 QPS 达到阈值的时候,进行限流
线程数
当调用该 api 的线程数达到阈值的时候,进行限流
处理该 api 请求的线程数达到阈值,再来请求就会直接拒绝;
而 QPS 是每秒并发请求数的限制;这个是最大并发请求线程树的限制。
当选择 线程数 时,【流控效果】只能是 快速失败。
流控模式
直接
当 api 达到限流条件时,直接限流
关联
当关联的资源达到阈值时,限流
当两个资源之间具有资源争抢或者依赖关系的时候,这两个资源便具有了关联。比如对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度。如果放任读写操作争抢资源,则争抢本身带来的开销会降低整体的吞吐量。可使用关联限流来避免具有关联关系的资源之间过度的争抢
链路
只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就进行限流),api 级别的针对来源
流控效果(只有是 QPS 时才可以设置)
快速失败
直接拒绝(
RuleConstant.CONTROL_BEHAVIOR_DEFAULT)方式是默认的流量控制方式,当QPS超过任意规则的阈值后,新的请求就会被立即拒绝,拒绝方式为抛出FlowException。这种方式适用于对系统处理能力确切已知的情况下,比如通过压测确定了系统的准确水位时。Warm Up
当流量突然增大的时候,我们常常会希望系统从空闲状态到繁忙状态的切换的时间长一些。即如果系统在此之前长期处于空闲的状态,我们希望处理请求的数量是缓步的增多,经过预期的时间以后,到达系统处理请求个数的最大值。Warm Up(冷启动,预热)模式就是为了实现这个目的的。
默认
coldFactor为 3,即请求 QPS 从threshold / 3开始,经预热时长逐渐升至设定的 QPS 阈值。限流-冷启动:冷启动
设置界面单位是 5

可以看到,最开始的阈值是 100/3,慢慢的再一段时间内才开始上升到设置的 100
排队等待
匀速排队(
RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。Leaky Bucket 对应 流量整形 中的匀速器。它的中心思想是,以固定的间隔时间让请求通过。当请求到来的时候,如果当前请求距离上个通过的请求通过的时间间隔不小于预设值,则让当前请求通过;否则,计算当前请求的预期通过时间,如果该请求的预期通过时间小于规则预设的 timeout 时间,则该请求会等待直到预设时间到来通过(排队等待处理);若预期的通过时间超出最大排队时长,则直接拒接这个请求。
设置界面单位是 ms

设置 QPS = 10,每秒匀速 10 个,间隔时间:1000ms / 10 = 100ms
超时时间 20 * 1000ms = 20s
如果请求等待时间超过 20s,就会失败:

Jmeter 绝对并发:

熔断降级
概述
除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一。由于调用关系的复杂性,如果调用链路中的某个资源不稳定,最终会导致请求发生堆积。Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。
当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出 DegradeException)。
==❈ Setinel 的断路器没有半开状态:半开状态时系统会自动检测是否请求有异常,没有异常就关闭断路器恢复使用,有异常就继续打开断路器不可用(Hystrix)。==
策略
源码:com.alibaba.csp.sentinel.slots.block.degrade.DegradeRule
我们通常用以下几种方式来衡量资源是否处于稳定的状态:
平均响应时间 (
DEGRADE_GRADE_RT):当资源的平均响应时间超过阈值(DegradeRule中的count,以 ms 为单位)之后,资源进入准降级状态。接下来如果持续进入 5 个请求,它们的 RT 都持续超过这个阈值,那么在接下的时间窗口(DegradeRule中的timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地返回(抛出DegradeException)。注意 Sentinel 默认统计的 RT 上限是 4900 ms,超出此阈值的都会算作 4900 ms,若需要变更此上限可以通过启动配置项-Dcsp.sentinel.statistic.max.rt=xxx来配置。Github Wiki 没有强调 5 个请求
异常比例 (
DEGRADE_GRADE_EXCEPTION_RATIO):当资源的每秒请求量 >= N(可配置),并且每秒异常总数占通过量的比值超过阈值(DegradeRule中的count)之后,资源进入降级状态,即在接下的时间窗口(DegradeRule中的timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地返回。异常比率的阈值范围是[0.0, 1.0],代表 0% - 100%。N 默认是5,目前没有找到配置 N 的地方
异常数 (
DEGRADE_GRADE_EXCEPTION_COUNT):当资源近 1 分钟的异常数目超过阈值之后会进行熔断。注意由于统计时间窗口是分钟级别的,若timeWindow小于 60s,则结束熔断状态后仍可能再进入熔断状态。
注意:异常降级仅针对业务异常,对 Sentinel 限流降级本身的异常(BlockException)不生效。为了统计异常比例或异常数,需要通过 Tracer.trace(ex) 记录业务异常。示例:
1 | Entry entry = null; |
开源整合模块,如 Sentinel Dubbo Adapter, Sentinel Web Servlet Filter 或 @SentinelResource 注解会自动统计业务异常,无需手动调用。
热点key
概述
何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行限制。比如:
- 商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制
- 用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
Sentinel 利用 LRU 策略统计最近最常访问的热点参数,结合令牌桶算法来进行参数级别的流控。热点参数限流支持集群模式。
简单使用
用 @SentineResource 注解,设置参数,同时在控制台设置参数索引、阈值、时间窗口等参数进行热点key限流;
不使用注解无效
参数例外项

偶尔期望参数是某个特殊值时,限流值要特殊设置。
仅支持基本类型和String
系统规则(系统自适应限流)
Sentinel 系统自适应限流从整体维度对应用入口流量进行控制,结合应用的 Load、CPU 使用率、总体平均 RT、入口 QPS 和并发线程数等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
系统保护规则是从应用级别的入口流量进行控制,从单台机器的 load、CPU 使用率、平均 RT、入口 QPS 和并发线程数等几个维度监控应用指标,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量生效。入口流量指的是进入应用的流量(EntryType.IN),比如 Web 服务或 Dubbo 服务端接收的请求,都属于入口流量。
系统规则支持以下的模式:
Load 自适应(仅对 Linux/Unix-like 机器生效):系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的
maxQps * minRt估算得出。设定参考值一般是CPU cores * 2.5。CPU usage(1.5.0+ 版本):当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏。
平均 RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
@SentinelResource
概述
Sentinel 提供了 @SentinelResource 注解用于定义资源,并提供了 AspectJ 的扩展用于自动定义资源、处理 BlockException 等。使用 Sentinel Annotation AspectJ Extension 的时候需要引入以下依赖:
1 | <dependency> |
注意:注解方式埋点不支持 private 方法。
参数说明
@SentinelResource 用于定义资源,并提供可选的异常处理和 fallback 配置项。 @SentinelResource 注解包含以下属性:
value:资源名称,必需项(不能为空)entryType:entry 类型,可选项(默认为EntryType.OUT)blockHandler/blockHandlerClass:blockHandler对应处理BlockException的函数名称,可选项。blockHandler 函数访问范围需要是public,返回类型需要与原方法相匹配,参数类型需要和原方法相匹配并且最后加一个额外的参数,类型为BlockException。blockHandler 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定
blockHandlerClass为对应的类的Class对象,注意对应的函数==必需为 static 函数==,否则无法解析。如果被热点限流,且没有设置这个参数,就会直接返回异常错误页面
仅被限流时会处理,运行时异常不会处理
fallback/fallbackClass:fallback 函数名称,可选项,用于在抛出异常的时候提供 fallback 处理逻辑。fallback 函数可以针对所有类型的异常(除了exceptionsToIgnore里面排除掉的异常类型)进行处理。fallback 函数签名和位置要求:- 返回值类型必须与原函数返回值类型一致;
- 方法参数列表需要和原函数一致,或者可以额外多一个
Throwable类型的参数用于接收对应的异常。 - fallback 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定
fallbackClass为对应的类的Class对象,注意对应的函数必需为 static 函数,否则无法解析。
defaultFallback(since 1.6.0):默认的 fallback 函数名称,可选项,通常用于通用的 fallback 逻辑(即可以用于很多服务或方法)。默认 fallback 函数可以针对所有类型的异常(除了exceptionsToIgnore里面排除掉的异常类型)进行处理。若同时配置了 fallback 和 defaultFallback,则只有 fallback 会生效。defaultFallback 函数签名要求:- 返回值类型必须与原函数返回值类型一致;
- 方法参数列表需要为空,或者可以额外多一个
Throwable类型的参数用于接收对应的异常。 - defaultFallback 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定
fallbackClass为对应的类的Class对象,注意对应的函数必需为 static 函数,否则无法解析。
exceptionsToIgnore(since 1.6.0):用于指定哪些异常被排除掉,不会计入异常统计中,也不会进入 fallback 逻辑中,而是会原样抛出。
注:1.6.0 之前的版本 fallback 函数只针对降级异常(
DegradeException)进行处理,不能针对业务异常进行处理。
特别地,若 blockHandler 和 fallback 都进行了配置,则被限流降级而抛出 BlockException 时只会进入 blockHandler 处理逻辑。若未配置 blockHandler、fallback 和 defaultFallback,则被限流降级时会将 BlockException 直接抛出(若方法本身未定义 throws BlockException 则会被 JVM 包装一层 UndeclaredThrowableException)。
示例:
1 | public class TestService { |
从 1.4.0 版本开始,注解方式定义资源支持自动统计业务异常,无需手动调用 Tracer.trace(ex) 来记录业务异常。Sentinel 1.4.0 以前的版本需要自行调用 Tracer.trace(ex) 来记录业务异常。
SpringCloud 不需要额外配置就可以使用注解,基于 AOP (SpringMVC、SpringBoot)都需要额外配置。
自定义限流处理
通过设置属性 blockHandlerClass 来将兜底方法与业务代码分开
Feign
需要在配置文件中开启 sentinel 对 feign 的支持:
1 | feign.sentinel.enabled=true |
持久化
微服务重启或 Sentinel 重启都会丢失配置规则;
可以将 sentinel 的配置保存在 Nacos 上或 Redis 中;
一般来说,规则的推送有下面三种模式:
推送模式 说明 优点 缺点 原始模式 API 将规则推送至客户端并直接更新到内存中,扩展写数据源( WritableDataSource)简单,无任何依赖 不保证一致性;规则保存在内存中,重启即消失。严重不建议用于生产环境 Pull 模式 扩展写数据源( WritableDataSource), 客户端主动向某个规则管理中心定期轮询拉取规则,这个规则中心可以是 RDBMS、文件 等简单,无任何依赖;规则持久化 不保证一致性;实时性不保证,拉取过于频繁也可能会有性能问题。 Push 模式 扩展读数据源( ReadableDataSource),规则中心统一推送,客户端通过注册监听器的方式时刻监听变化,比如使用 Nacos、Zookeeper 等配置中心。这种方式有更好的实时性和一致性保证。生产环境下一般采用 push 模式的数据源。规则持久化;一致性;快速 引入第三方依赖
持久化到 Nacos
添加依赖
1
2
3
4
5<!-- 后续做持久化 -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>修改 yaml 配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
server-addr: localhost:8848
sentinel:
transport:
dashboard: localhost:12345
# 默认8719,如果被占用会自动从8719开始+1扫描
port: 8719
# 配置datasource
datasource:
# 数据源名
ds1:
# 使用nacos
nacos:
server-addr: localhost:8848
dataId: cloudalibaba-sentinel-service
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow可以看到,可以使用多种数据源来持久化

添加 Nacos 配置,在上一步设定的配置信息中:
1
2
3
4
5
6
7
8
9
10
11[
{
"resource": "bbyResource",
"limitApp": "default",
"grade": 1,
"count": 5,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]这样重启会后也可以持久化
然而控制台添加的规则还是在内存里面,不会从存储到 nacos 中
当新建配置时,会发送一个 post 请求:
直接复制请求的 json 到 nacos 中就可以(nacos 中的配置是一个数组,将 json 对象添加到数组中)
如果想在控制台修改的数据自动同步到 Nacos 中,可以参考:Sentinel-Nacos实现规则持久化
参考:

Seata
分布式事务
概述
单体应用被拆分成微服务,每个服务内部的数据一致性由本地事务保证,但是全局的数据一致性没办法保证。
一次业务操作需要跨多个数据源或多个系统进行远程调用,就会产生分布式事务问题。
2.分布式事务产生原因
当架构由单体向多服务演进时,整个系统的可靠性变得难以控制,在单体服务中,一个请求的整个周期,从请求到响应结果,都是在一台服务器上,本地事务就可以保证一组数据操作的一致性。
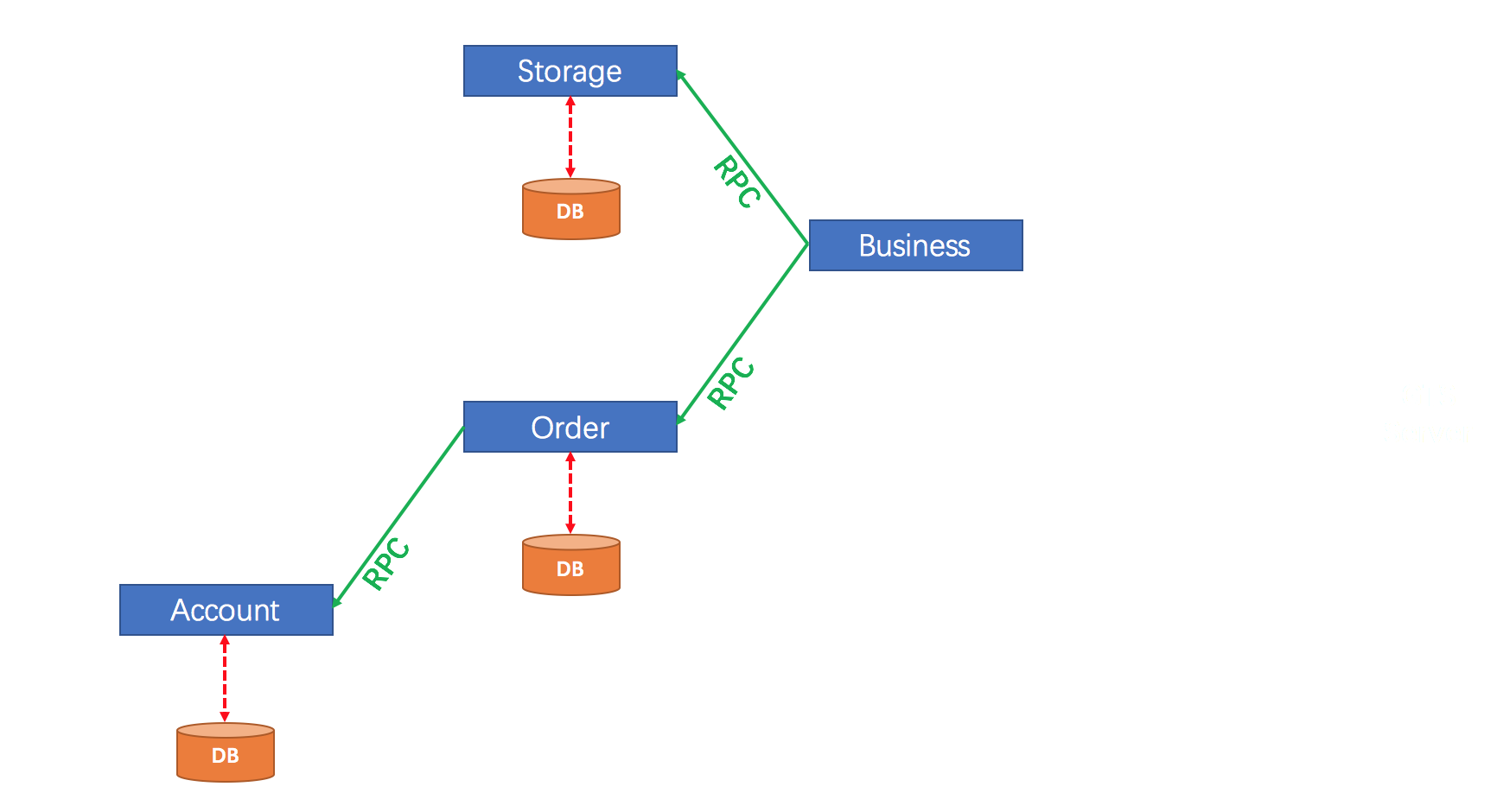
在微服务中,从请求到响应,之间可能跨越多台服务器,多个数据库,如下图,假设有个金融系统,拆分为了多个微服务,每个微服务有自己的数据库,我们现在发起借款这个操作,需要用到以下几个微服务:
这个借款操作,可以抽象概括为以下几个步骤:
1.用户发起借款,调用借款服务的借款接口;
2.借款同时,在授信服务里 减少授信额度;
3.借款同时,在资金服务里 增加账户余额;
4.借款同时,在日志服务里 增加流水记录;
……
这里只是假设,实际金融项目中的借款这个动作发生的事情远比上图复杂。
由于每个服务都是单独部署的,在理想状态下,上述的操作,可以顺利得以执行。
如果中间有服务发生故障了呢?
假设一个常见的场景,资金服务由于没有合理使用线程池和连接池,现在内存爆掉,无法正常处理请求,那么,这个链路成为了如下的样子:
1.用户发起借款,调用借款服务的借款接口;
2.借款同时,在授信服务里 减少授信额度;
3.借款同时,在资金服务里 增加账户余额;x
4.借款同时,在日志服务里 增加流水记录;
……
此时,由于是在多个服务中,本地的Transaction已经无法应对这个情况了,现在系列操作导致了上述的情况,用户的授信额度减少了,流水也记录了,但是用户没有收到钱。


SOURCE 再有人问你分布式事务,把这篇扔给他
分布式事务过程(一ID + 三组件)
Transaction ID XID 全局唯一的事务 ID
三组件
Transaction Coordinator(TC)
事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或混滚;
Transaction Manager(TM)
控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议;
Resource Manager(RM)
控制分支事务,负责分支注册、状态汇报、并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚
一个典型的分布式事务过程:
- TM 向 TC 申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的 XID。
- XID 在微服务调用链路的上下文中传播。
- RM 向 TC 注册分支事务,将其纳入 XID 对应全局事务的管辖。
- TM 向 TC 发起针对 XID 的全局提交或回滚决议。
- TC 调度 XID 下管辖的全部分支事务完成提交或回滚请求。

Seata
概述
Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。
下载安装
新建数据库,导入 sql
sql 地址:https://github.com/seata/seata/blob/1.2.0/script/server/db/mysql.sql
修改 file.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31## transaction log store, only used in seata-server
store {
## store mode: file、db
# 设置为db
mode = "db"
## file store property
file {
## ....
}
## database store property
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "druid"
## mysql/oracle/postgresql/h2/oceanbase etc.
dbType = "mysql"
driverClassName = "com.mysql.jdbc.Driver"
# 数据库配置
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "root"
password = "mysqlpass"
minConn = 5
maxConn = 30
globalTable = "global_table"
branchTable = "branch_table"
lockTable = "lock_table"
queryLimit = 100
maxWait = 5000
}
}修改 register.conf
1
2
3
4
5
6
7
8
9
10
11
12
13registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
nacos {
application = "seata-server"
serverAddr = "localhost:8848"
namespace = ""
cluster = "default"
username = ""
password = ""
}
## ....启动 Nacos
运行脚本:
| -h | –host | 指定在注册中心注册的 IP | 不指定时获取当前的 IP,外部访问部署在云环境和容器中的 server 建议指定 |
| —- | ———— | ————————– | ———————————————————— |
| -p | –port | 指定 server 启动的端口 | 默认为 8091 |
| -m | –storeMode | 事务日志存储方式 | 支持file和db,默认为file|
| -n | –serverNode | 用于指定seata-server节点ID | ,如1,2,3…, 默认为1|
| -e | –seataEnv | 指定 seata-server 运行环境 | 如dev,test等, 服务启动时会使用registry-dev.conf这样的配置 |如:
1
$ sh ./bin/seata-server.sh -p 8091 -h 127.0.0.1
使用
用例来自官网文档
用户购买商品的业务逻辑。整个业务逻辑由3个微服务提供支持:
- 仓储服务:对给定的商品扣除仓储数量。
- 订单服务:根据采购需求创建订单。
- 帐户服务:从用户帐户中扣除余额。
配置
官网 WIKI 莫得配置说明就很难受 emmm
参考:
架构图
步骤
在 MySQL 中分别创建三个数据库
每个数据库中创建 undo_log 回滚日志表
在业务相关的数据库中添加 undo_log 表,用于保存需要回滚的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16CREATE TABLE `undo_log`
(
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`branch_id` BIGINT(20) NOT NULL,
`xid` VARCHAR(100) NOT NULL,
`context` VARCHAR(128) NOT NULL,
`rollback_info` LONGBLOB NOT NULL,
`log_status` INT(11) NOT NULL,
`log_created` DATETIME NOT NULL,
`log_modified` DATETIME NOT NULL,
`ext` VARCHAR(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8地址:https://github.com/seata/seata/blob/develop/script/client/at/db/mysql.sql
引入依赖
1
2
3
4
5
6
7
8
9
10
11<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.1.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<!-- Seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<exclusion>
<artifactId>seata-all</artifactId>
<groupId>io.seata</groupId>
</exclusion>
</exclusions>
</dependency>
<!-- seata 1.2 -->
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-all</artifactId>
<version>1.2.0</version>
</dependency>==导入Maven包时,一定要注意,seato-all的版本和本地服务的版本是否一致!!!不然即使配置OK,也可能会出现运行错误!!==
exclude排除包之后,引入与服务端版本匹配的 jar 包添加Seata 配置文件
registry.conf
该配置用于指定 TC 的注册中心和配置文件,默认都是 file; 如果使用其他的注册中心,要求 Seata-Server 也注册到该配置中心上
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76# 注册中心(要与服务端注册中心相同)
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "file"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
eureka {
serviceUrl = "http://localhost:8761/eureka"
application = "default"
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = "0"
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
# 配置中心,只有为'file'时,file.conf才会生效,需要配置
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "file"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
consul {
serverAddr = "127.0.0.1:8500"
}
apollo {
app.id = "seata-server"
apollo.meta = "http://192.168.1.204:8801"
}
zk {
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
etcd3 {
serverAddr = "http://localhost:2379"
}
file {
name = "file.conf"
}
}
file.conf
该配置用于指定TC的相关属性;如果使用注册中心也可以将配置添加到配置中心
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121transport {
# tcp udt unix-domain-socket
type = "TCP"
#NIO NATIVE
server = "NIO"
#enable heartbeat
heartbeat = true
#thread factory for netty
thread-factory {
boss-thread-prefix = "NettyBoss"
worker-thread-prefix = "NettyServerNIOWorker"
server-executor-thread-prefix = "NettyServerBizHandler"
share-boss-worker = false
client-selector-thread-prefix = "NettyClientSelector"
client-selector-thread-size = 1
client-worker-thread-prefix = "NettyClientWorkerThread"
# netty boss thread size,will not be used for UDT
boss-thread-size = 1
#auto default pin or 8
worker-thread-size = 8
}
shutdown {
# when destroy server, wait seconds
wait = 3
}
serialization = "seata"
compressor = "none"
}
service {
#vgroup->rgroup
vgroup_mapping.my_test_tx_group = "default"
#only support single node
default.grouplist = "127.0.0.1:8091"
#degrade current not support
enableDegrade = false
#disable
disable = false
#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanent
max.commit.retry.timeout = "-1"
max.rollback.retry.timeout = "-1"
}
client {
async.commit.buffer.limit = 10000
lock {
retry.internal = 10
retry.times = 30
}
report.retry.count = 5
}
## transaction log store
store {
## store mode: file、db
mode = "file"
## file store
file {
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
max-branch-session-size = 16384
# globe session size , if exceeded throws exceptions
max-global-session-size = 512
# file buffer size , if exceeded allocate new buffer
file-write-buffer-cache-size = 16384
# when recover batch read size
session.reload.read_size = 100
# async, sync
flush-disk-mode = async
}
## database store
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "dbcp"
## mysql/oracle/h2/oceanbase etc.
db-type = "mysql"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "mysql"
password = "mysql"
min-conn = 1
max-conn = 3
global.table = "global_table"
branch.table = "branch_table"
lock-table = "lock_table"
query-limit = 100
}
}
lock {
## the lock store mode: local、remote
mode = "remote"
local {
## store locks in user's database
}
remote {
## store locks in the seata's server
}
}
recovery {
committing-retry-delay = 30
asyn-committing-retry-delay = 30
rollbacking-retry-delay = 30
timeout-retry-delay = 30
}
transaction {
undo.data.validation = true
undo.log.serialization = "jackson"
}
## metrics settings
metrics {
enabled = false
registry-type = "compact"
# multi exporters use comma divided
exporter-list = "prometheus"
exporter-prometheus-port = 9898
}需要注意的是
service.vgroup_mapping这个配置,在 Spring Cloud 中默认是${spring.application.name}-fescar-service-group,可以通过指定application.properties的spring.cloud.alibaba.seata.tx-service-group这个属性覆盖,但是必须要和file.conf中的一致,否则会提示no available server to connect。(jar包与服务端版本号不一致有时也会出现这个问题)
注入数据源
Seata 通过代理数据源的方式实现分支事务;MyBatis 和 JPA 都需要注入
io.seata.rm.datasource.DataSourceProxy, 不同的是,MyBatis 还需要额外注入org.apache.ibatis.session.SqlSessionFactoryMybatis
需要引入依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18> <dependency>
> <groupId>mysql</groupId>
> <artifactId>mysql-connector-java</artifactId>
> </dependency>
> <dependency>
> <groupId>com.alibaba</groupId>
> <artifactId>druid-spring-boot-starter</artifactId>
> <version>1.1.10</version>
> </dependency>
> <dependency>
> <groupId>org.mybatis.spring.boot</groupId>
> <artifactId>mybatis-spring-boot-starter</artifactId>
> </dependency>
> <dependency>
> <groupId>org.springframework.boot</groupId>
> <artifactId>spring-boot-starter-jdbc</artifactId>
> </dependency>
>官网示例引入了 Druid
配置文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class DataSourceProxyConfig {
(prefix = "spring.datasource")
public DataSource dataSource() {
return new DruidDataSource();
}
public DataSourceProxy dataSourceProxy(DataSource dataSource) {
return new DataSourceProxy(dataSource);
}
public SqlSessionFactory sqlSessionFactoryBean(DataSourceProxy dataSourceProxy) throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSourceProxy);
return sqlSessionFactoryBean.getObject();
}
}这种方式由于手动创建了
SqlSessionFactory,所以 application.yml/properties 中的配置需要手动注入并设置才会生效启动类也要添加注解:
1
2
3
4// import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
(exclude = DataSourceAutoConfiguration.class)
启动必要的服务:包括 Seata-server 以及依赖的注册或配置中心
使用
@GlobalTransactional开启事务在业务的发起方的方法上使用
@GlobalTransactional开启全局事务,Seata 会将事务的 xid 通过拦截器添加到调用其他服务的请求中,实现分布式事务
参考:
2.2.0.RELEASE+ 不需要手动配置数据源代理,直接创建一个
2
3
4
5
6
> (prefix = "spring.datasource")
> public DataSource dataSource() {
> return new DruidDataSource();
> }
>
即可,如果不是 2.2.0 及以上但 Seata 版本高于 1.1.0,可以参考:(貌似0.8以上的支持参数配置,1.1.0 使用注解代替)
seata1.1.0版本新加入以下注解,用于开启数据源自动代理功能
@EnableAutoDataSourceProxy
对于使用seata-spring-boot-starter的方式,默认已开启数据源自动代理,如需关闭,请配置seata.enableAutoDataSourceProxy=false,该项配置默认为true。 如需切换代理实现方式,请通过seata.useJdkProxy=false进行配置,默认为false,采用CGLIB作为数据源自动代理的实现方式。
对于使用seata-all的方式,请使用@EnableAutoDataSourceProxy来显式开启数据源自动代理功能。如有需要,可通过该注解的useJdkProxy属性进行代理实现方式 的切换。默认为false,采用CGLIB作为数据源自动代理的实现方式。