 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
记得两年以前就和实验室的朋友们讨论过如何使得指定CPU跑到指定特定百分比,但可惜当时并没有令我信服的答案出现,两年以后再学习了Chaosblade,Chaos-mesh,stress-ng的部分源码以后终于可以说我知道这个问题该如何优雅的解决了。
问题抽象一下,其实就是保证每秒某个CPU只跑到目前频率(不考虑变频)的百分比,其实满足此需求的工具已经非常多了,国内ChaosBlade中CPU实验允许使得指定CPU burn 到指定CPU频率,比如目前是40%,我们指定60%,最后CPU会维持在60%,无论其他任务的CPU如何变动,最终会动态维护在60%;而Chaos-mesh则是在内部调用stress-ng --cpu-load来达到目标百分比,但是行为和chaosblade不太一样,比如目前是40%,我们指定60%,一个进程会一直维护60%负载率,在这一刻CPU负载为100%。
指定CPU百分比
关于跑满指定CPU的特定负载其实本质上在于一点,即如何准确的使得CPU在每一秒近似准确的执行目标频率的百分比。当我们需要在一秒内跑满70%的CPU时,简单实现的伪码是这样的:
func main() {
const period = int64(1000000000)
burn := 7 * period / 10
for {
startTime1 := time.Now().UnixNano()
for time.Now().UnixNano()-startTime1 < burn {
}
endTime1 := time.Now().UnixNano()
startTime2 := time.Now().UnixNano()
time.Sleep(300 *time.Millisecond)
endTime2 := time.Now().UnixNano()
fmt.Printf("%s %s\n", endTime1 - startTime1, endTime2 - startTime2)
}
}
但是这样做有什么问题呢?一个问题是for time.Now().UnixNano()-startTime < q {}在startTime为0,burn为0.7的情况下是否真的可以使得CPU利用率上升70%;另一个问题是sleep陷入睡眠时间是否真的是0.3秒。
跑个简单的小demo,结果如下:
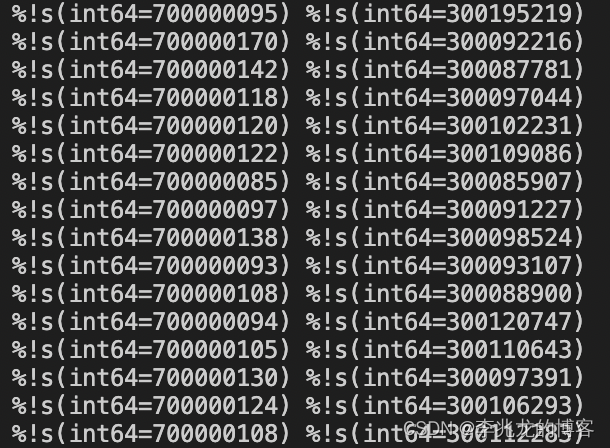
基本上精度还是比较高的,CPU循环的精度在百纳秒级别,sleep精度在百微秒级别,已经是可以忽略的级别了。
stress-ng中给出了另一种方案,粒度相比于上一种更小,伪代码如下:
func main() {
burn := 70
bias := 0.0
startTime := time.Now().UnixNano()
for {
if time.Now().UnixNano()-startTime > burn {
break
}
startTime1 := time.Now().UnixNano()
for {
dosomething
}
endTime1 := time.Now().UnixNano()
delay := (((100 - burn) * (endTime1 - startTime1)) / (double)burn);
delay -= bias
if delay < 0.0 {
bias = 0.0;
} else {
startTime1 := time.Now().UnixNano()
time.sleep(delay)
endTime2 := time.Now().UnixNano()
bias = (endTime2 - startTime1 )- delay
}
}
}
这是更加优雅的一种做法,但是精度是否优于第一种简单实现真的不好说,
获取精确的CPU负载
感谢张玉哲学长的指点!
以上的方案在Chaos-mesh和stress-ng场景中已经够了,但是Chaosblade还不太够,因为我们需要时刻对现有的CPU频率做采集,使得CPU负载动态维护在一个水平线上,这需要我们不停的获取当前CPU频率。
有什么好的方法呢?以go语言举例子,github.com/shirou/gopsutil/cpu:Percent就可以计算当前CPU的实际负载,但是并不精准,因为和top之类的工具一样,所有数据都是从/proc/xxx/stat获取的,从show_stat可以看到而proc中的数据除了idle和iowait外,其余的时间信息数据都是来自于cpustat数组:
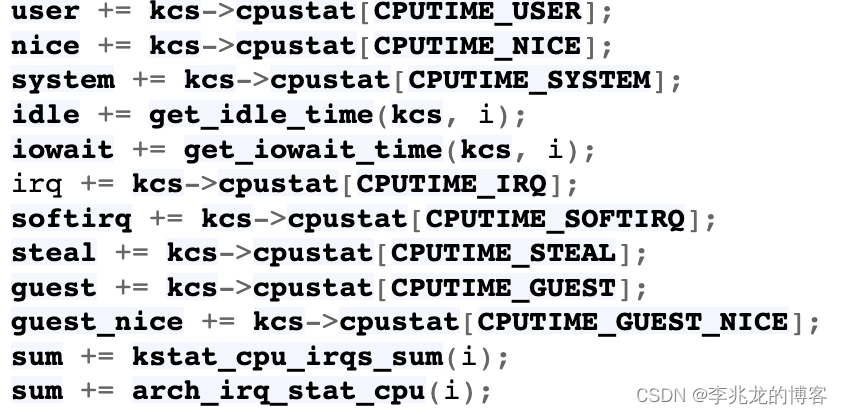
cpustat数组的更新取决于Tick的频率,根据Tick产生时是在用户态还是内核态以及idle进程的上下文等信息,选择不同的函数进行处理,然后把每Tick对应的ns加到对应的cpustat数组中。Tick是每发生一次HZ的中断时间,计算方式是HZ的倒数,可以使用如下方法观察HZ,我的机器是1000:
cat /boot/config-`uname -r` | grep ‘^CONFIG_HZ=’
这意味着事实上一般上机器/proc的精度是在微秒级别,而且本身基于Tick的方式对于idle,sys有些时候也不太精确。
github.com/shirou/gopsutil/cpu:Percent的其核心代码如下:
func calculateBusy(t1, t2 TimesStat) float64 {
t1All, t1Busy := getAllBusy(t1)
t2All, t2Busy := getAllBusy(t2)
if t2Busy <= t1Busy {
return 0
}
if t2All <= t1All {
return 100
}
return math.Min(100, math.Max(0, (t2Busy-t1Busy)/(t2All-t1All)*100))
}
其中TimesStat是某个CPU核心某一刻的stat信息,可以看出是首先计算斜率,然后乘以100计算一段时间内的CPU利用率,因为基于proc本身不够准确,精度在微秒级别。
其实就第一遍指定CPU百分比来看微秒级别的延迟足够用了,但是其实有办法获取纳秒级别的CPU利用率,就是基于perf的CPU_CYLES和CPU_CLOCK统计实际的执行的CPU时钟数,然后与CPU频率(CPU可能出现变频)相除则可以获取精确的CPU利用率,数据的提取需要基于eBPF来做,不过目前看起来不用大费周章的提高精度了。
总结
有意思的一个问题,再次告诉我们一个道理,简简单单,平平淡淡才是真,花里胡哨的东西能不用就不用。
再提一点,我一直在思考讲eBPF引入ChaosBlade社区,但是始终想不到一个真正杀手级别的功能来说服别人,开始是想引入纳秒级别的CPU利用率,最后发现完全没有这个必要;后来天真的认为链路层端口级别的丢包只能基于eBPF来说,后来发现了tcconfig[2]。
混沌工程工具是否真的需要引入eBPF呢?eBPF对于Trace,网络,容器安全的贡献令人惊叹,但是混沌工程强调通过故障找到系统的薄弱点,那我们一定是在软件交互级别做注入的,而内核与用户的交互是通过系统调用,理论来说在系统调用层注入故障已经满足了用户态程序的一切注入需求(不是eBPF相关工具或者systemtap也可以完成这样的功能),内核中的注入可以替换为在系统调用做注入,这对于用户来说是没什么区别。
暂时能想到唯一eBPF做注入的地方就是使用eBPF开发的地方,我们可以提供内核某些关键函数的注入供eBPF开发者使用,但是有能力做eBPF开发的人也很容易可以自己写一套工具,但是显然如果以这个思路考虑使用eBPF注入的学习成本是很高且收益不大的。
虽然注入不太好用,但是系统级别指标分析(从PRINCIPLES OF CHAOS ENGINEERING第一条来看一般不用这个当指标)也是一个eBPF可以大显身手的地方,从[4]来看,chaos-mesh目前对于eBPF的尝试也处于初级阶段,如果Pingcap的工程师们真的认为eBPF可以用于混沌工程工具我觉得他们早动手了,所以我认为他们和我想的差不多。
笔者认知不够,水平有限,文章难免出错,对于存疑的观点大家多多讨论。
参考: