 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
引言
AWS有两款兼容Redis的内存数据库产品,ElastiCache和MemoryDB,名字就可以看出定位的区别,缓存与数据库。论文中提到因为redis缺乏一致性保证,用户往往需要在redis之外再构建一个服务来存储相同的数据,并定期对帐,保证redis中数据的完整性。如此差劲的体验当然免不了被客户疯狂口嗨,所以MemoryDB的定位从开始就很明确:
- 内存数据库的性能(可以差一点,不能差太多)
- 多AZ可靠性
- strong consistency
- high availability
当然这和SSD KV又是不同的赛道,定位如此清晰产品,不愧是AWS。让我们来想想如果是我们自己来设计这样的产品应该怎么做,当然不同的约束做事情思路是不一样的。
如果不考虑后续兼容性,不考虑人力,重新开发一套走一致性协议的数据库并不是不可以,相比异步复制的内存数据库,就多了一致性/wal开销;当然好处是强一致/最终一致性是可调的,不需要ElastiCache和MemoryDB两个产品。我们组的支持redis协议的内存产品就是这样的路子。
但是考虑最小化修改代码的话和排期的话,这种稳扎稳打的思路就完全行不通了,不但后续redis的全部特性都需要重新实现,在redis引擎内部支持raft/paxos也不是容易的事情,人力物力消耗太大,而且需要非常多精力投入代码可靠性测试。这时AWS就给了我们很好的一个思路,即redis引擎和数据同步分离,增量数据写入 transaction log service,从节点直接从日志服务拉取增量来做到强一致性,而且这样做没有动redis引擎。
一个稳定的binlog可以带来无限的可能性,异地复制,PITR,流计算,构建稳定副本,存算分离等等。最近我们正在考虑在时序数据库之上基于binlog构建存储格式不一致的热备,以解决查询隔离,兼容开源生态等一系列问题。
一致性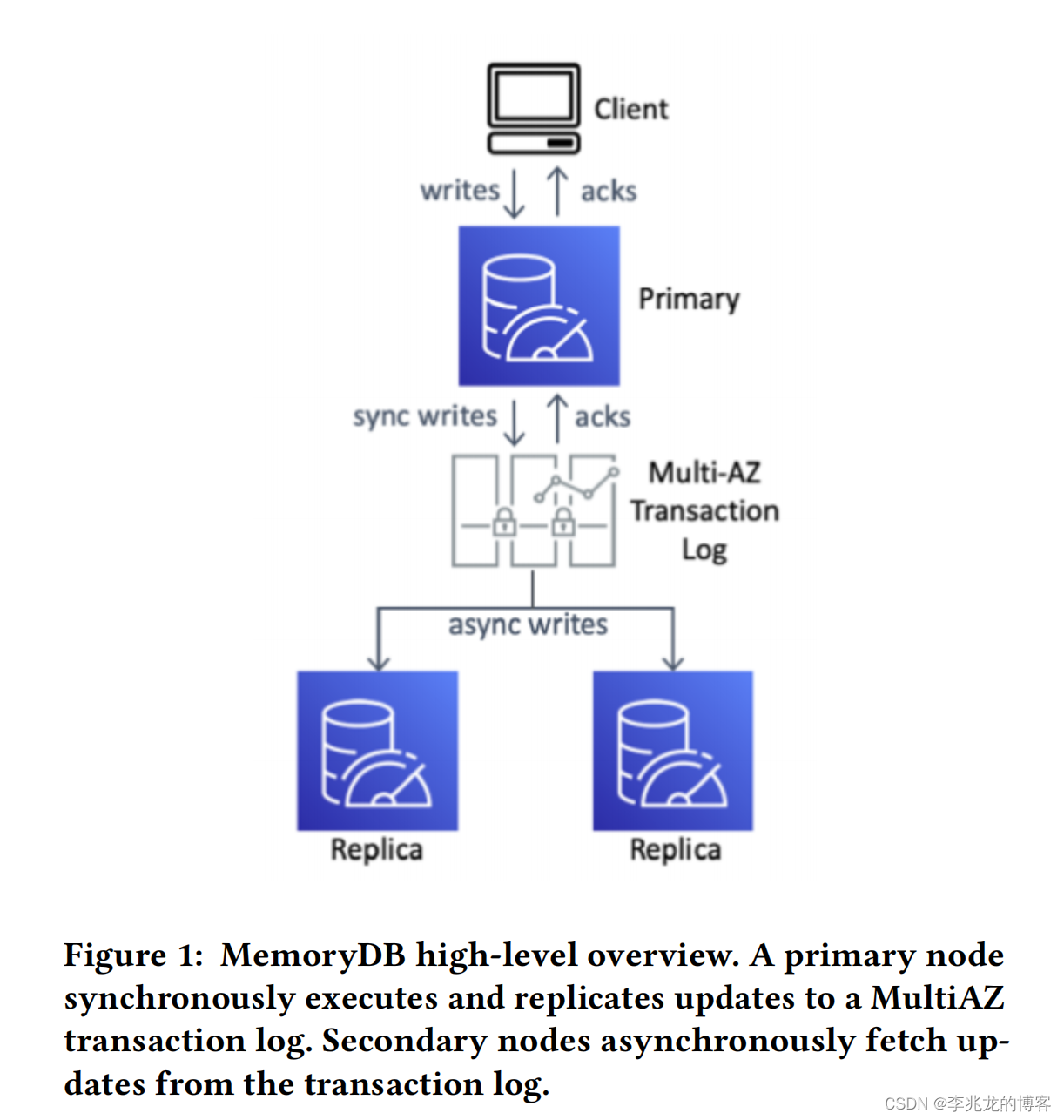
基于日志服务的同步构建强一致数据库的基本思路如下:
- 使用write-behind日志,在主节点执行请求,请求结束时生成复制信息
- 在日志写入日志服务前将请求存在tracker中,如果key被没有持久化的操作修改,所有的对该键的读取操作都会延迟,这样就可以做到读写线性一致,算是乞丐版MVCC,也没有办法,因为数据只有一份最新的,老数据已经被覆盖了,没法像MVCC那样读老版本数据,那只能阻塞读请求来保证读写一致了。
- 持久化日志服务完成,向用户返回这个操作的结果
- 从副本从日志服务中拉取数据
选主时机与选主
redis本身故障检测与故障转移做的并不好,具体的原理可以参考我之前写的一篇文章[7],用我自己的理解和论文的观点结合下基本总结有如下缺陷:
- 故障检测和剔除过慢:不仅需要集群中一半主节点探测后认为失败,其次所有的消息还是基于Gossip传播的。我们系统内部的arbiter对于明显的错误基本可以做到10s以内的识别+剔除。
- 脑裂:如果主节点与集群的其他节点隔离,它将继续提供数据服务,而在健康的分区上,从可能会被提升为主。
- 一致性差:存活的副本就能竞选并成为主,主的数据可能不是最新。
使用日志系统如何实现选主呢?日志服务提供了很强大的一个功能,论文中称为“conditional append API”,即满足某些条件才可以插入,基于这样的语义我们可以做到高效的切主,下面是[6]中举的小例子,已经足够清楚了。

这种思路最大的问题是follower的权限太高了,基本上一旦发起选主,就算主在任期内还是会被抢主。
故障检测MemoryDB使用了类似lease的方式,leader通过在事务日志中添加租约Term来定期续订租约,follower观察事务日志条目,并在观察到租约续订后启动一个预定的计时器。计时器的持续时间确保严格大于租约持续时间,在这段时间副本将避免争夺领导权,无法续约的主节点会在租期结束时主动停止读写服务,当副本节点在计时器结束后没有在事务日志中观察到任何租约续期条目时,会重新尝试竞选领导者。
这个思路类似Raft中lease read的思路[8],将lease read的思路带过来,实际上我们可以看出这里其实没有考虑时钟偏移的情况,当follower出现偏移时会立马成为主,当然也没有违反约束,
Recovery
2021年曾经在Tair实习时,导师问过我如何解决redis fork带来的请求时延抖动,当时的结论是cgroup隔离独立进程拉取AOF主动生成RDB,不依靠主进程本身生成RDB。三年后的今天,redis的三个顶级玩家已经有两个给出了自己的解决方案。
阿里云[9]直接修改fork接口,将fork调用过程中最耗时的页表拷贝部分从父进程移动到子进程,父进程因而可以快速返回用户态处理用户查询,以减少时延消耗。当然内存的消耗还是存在本机,机器仍旧需要预留部分内存给fork。
AWS在MemoryDB中则通过一个off-box的外部模块拉取日志系统数据在外部生成RDB,并上传S3,在迁移时直接从S3下载最新的RDB。
AWS决定不再从副本上做RDB的原因是:
- 客户可能从从副本读数据,fork会占用大量资源
- 主节点存在故障时,从节点对写入性至关重要,如果副本正在进行fork,可能会影响写入
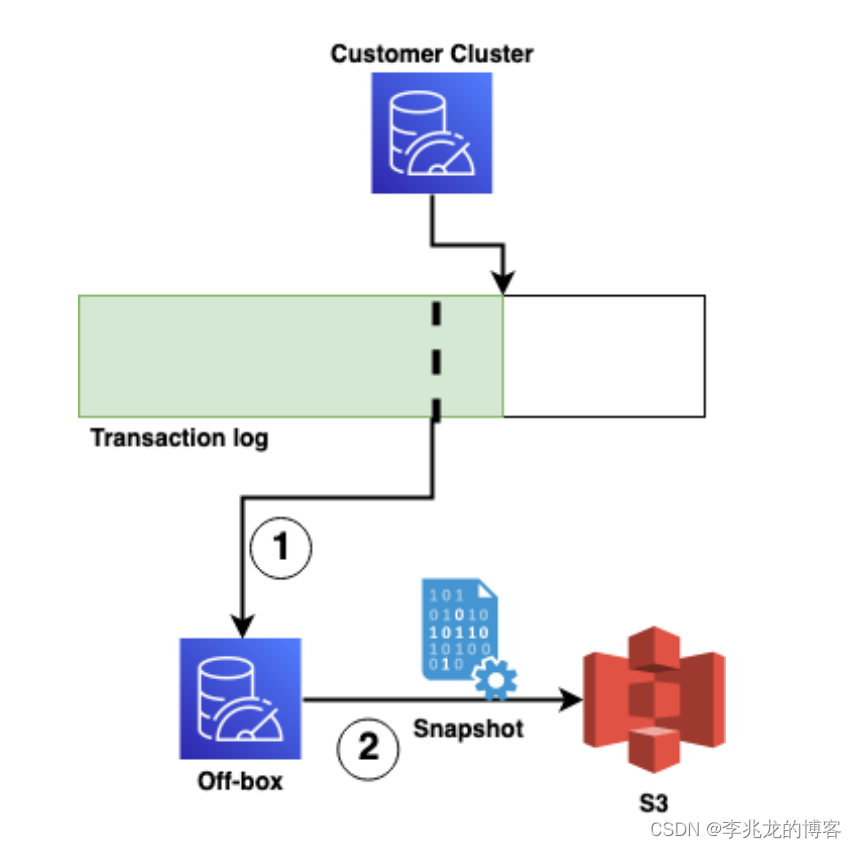
创建RDB的过程是动态调度的,基于最近RDB与最新日志之间的距离,总体思路比较清晰。
集群管理没有有意思的地方,没特别多值得提的地方。
正确性验证
升级的一致性保证
举个例子,现在三副本,从节点开始升级,主和一个从老版本,一从新版本。新老版本存在部分不兼容,这个新版本的从在租约到期后抢主成功,假设一部分命令主从不兼容,主此时宕机,从副本变为主,此时就丢失了一部分数据。
MemoeyDB通过升级保护来避免,即旧版本引擎发现复制流比自己版本新时,不再消费日志,旧版本的从就不会成为主。
我们内部也是基于N+1滚动更新的,所以原则上也可能会遇到这里提到的问题,我们一般是软件层面保持兼容来避免这个问题的。
RDB正确性验证
基本可以总结为下:
- 维护事务日志的running checksum,MemoryDB持续计算整个事务日志的checksum,并定期将当前的checksum注入到事务日志本身中。
- snapshot中数据的checksum,running checksum的基础以及最后一个日志的位置。
还原snapshot过程:
- 用数据的checksum校验整个snapshot是否有跳变
- 它使用其存储的位置标识符来查找要重放的后续事务日志
- 在重放事务日志时,它会以snapshot checksum为基础,重新计算运行中的running checksum,并将其与事务日志中checksum进行比较。
如果快照的checksum与它所捕获的事务日志前缀不匹配,验证将失败,只有验证成功的快照才提供给客户。
形式化验证
一致性测试框架使用Porcupine,对于我最感兴趣的形式化验证只是一笔带过,后续可以看下文中提到的文章[1][2][3],后续不出意外我应该会写几篇形式化验证的文章,最近苦于如何确保数据库在提供正确且稳定的服务,陷入无尽的测试和验证。
性能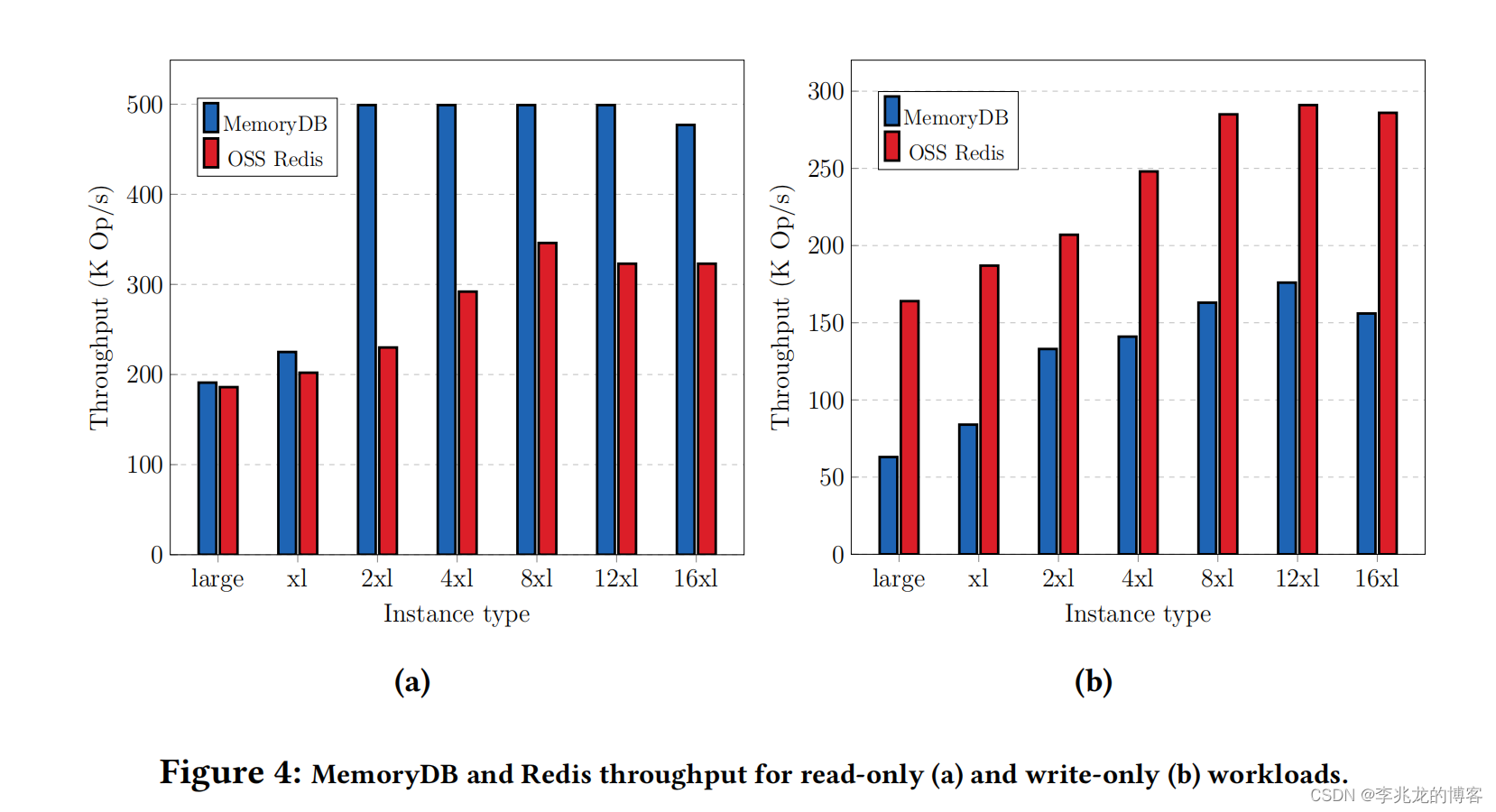
很奇怪的性能对比,写请求基本符合预期,读请求明眼人一看就知道耍花样了,仔细一看文章,果不其然,有兴趣的同学可以看下[5],事实上是所有的读请求可以看作走了batch。

总结
承接开头,MemoryDB相对ElastiCache的特性通过如下手段实现:
- 内存数据库的性能:使用redis引擎
- 多AZ可靠性:分离存储层和计算层,使用AWS内部的日志服务作为存储层,提供3AZ可靠性
- strong consistency:基于延迟所有未持久化修改操作的读操作
- high availability:基于
lease和conditional append API的选主
当然除此之外,文中提到的RDB思路和正确性验证都是很好的工程实践。
参考:
- Using Lightweight Formal Methods to Validate a Key-Value Storage Node in Amazon S3 sosp 2021
- P: Safe Asynchronous Event-Driven Programming
- How Amazon Web Services Uses Formal Methods
- Porcupine: A fast linearizability checker in Go.
- Amazon MemoryDB for Redis 功能
- SIGMOD 24 -Amazon MemoryDB
- Redis源码解析(19) 集群[2] 主从复制,故障检测与故障转移
- 关于Raft算法中lease read正确性相关的探讨
- Async-fork: Mitigating Query Latency Spikes Incurred by the Fork-based Snapshot Mechanism from the OS Level vldb2023