std::alloc 运行模式

在alloc中维护一个长度为16的数组,每个元素的内容是一根指针。初值为 0(nullptr)

这根指针又指向一个链表,这个链表即为待分配的内存。
#0 指向内存块为 8 bytes ----当申请的对象的大小为 <= 8 时,从 #0 上分配内存
#1 指向内存块为 16 bytes ----当申请的对象的大小为 >8 && <= 16 时,从 #1 上分配内存
#2 指向内存块为 24bytes ----当申请的对象的大小为 >16 && <= 24 时,从 #2 上分配内存
… 每次加 8 个字节,
#15 指向内存块为 128 bytes ----当申请的对象的大小为> 120 && <= 128 时,从 #15 上分配内存
问题来了,当申请的对象的大小超过 128 bytes 时怎样分配?
如果申请对象超过了 128 bytes时,就不有 alloc 分配,直接调用malloc()来分配
alloc中还存在 pool 这个概念,每次需要分配内存时,先查看 pool 中是否能分配出 一个以上的 内存块,如果可以就不用申请,如果pool中连一个内存块都无法分配,则向系统申请.申请到的内存都放到 pool 中,然后在想pool 中查询 .那么每次申请的个数是多少呢?
假设当前申请内存字节大小为 curr bytes,一共分配过 RoundUp bytes.
每次申请的内存 = curr * 20 * 2 + RoundUp(0>>4)
20: 20为20个 curr 的 bytes,每次申请最多20个,最少 1 个
*2: 每次分配两倍的量.其中一半用来给当前准备,另一部分还在 pool 中,当每次需要内存时,先查找 pool,减少了malloc()的使用
0>>4 : 给RoundUp/16,右移4位
RoundUp:当前累积量(到目前为止,一共分配内存的大小)
举个例子, 假如我们需要申请 32 bytes.
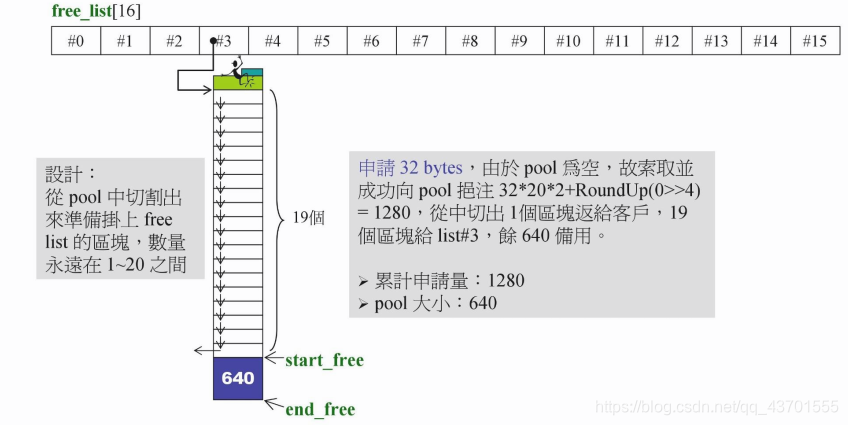
32 bytes 属于 #3的链表上
开始时,#3指向这个链表的头结点,然后将头结点分配出去,#3就指向下一个内存块.
640为pool中所有的大小.
这里还有一个点值得说一下–指针
这里的指针用的 特别巧妙.这个指针没有占用多余的空间。
每一个没有分配出去的内存块,它的前4个字节就是指向下一个内存块的指针。
每次分配一个内存块出去时,将#3指向下一个地址,然后当前内存块的前4个字节就会被新的数据覆盖。
这种指针被称为 嵌入式指针。
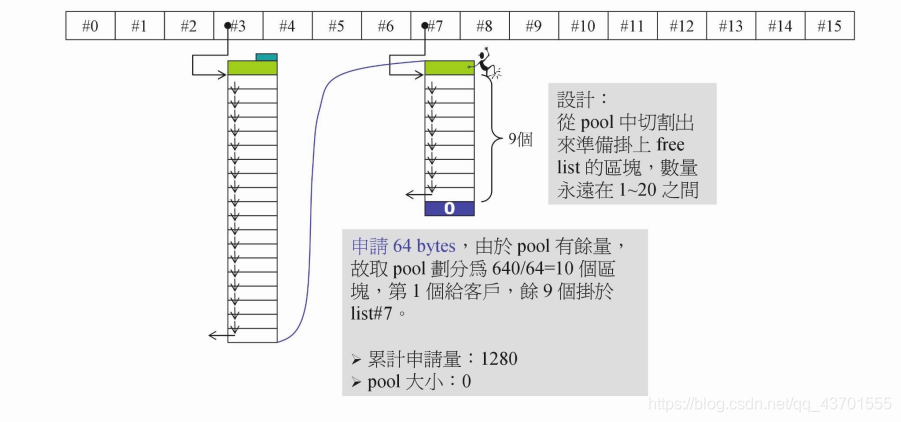
当我们再次申请64 bytes的对象时,首先在 pool 中 查看,如果能分配出 一个以上的 内存块,如果可以就不用申请。直接在pool中切割对应大小的内存块。
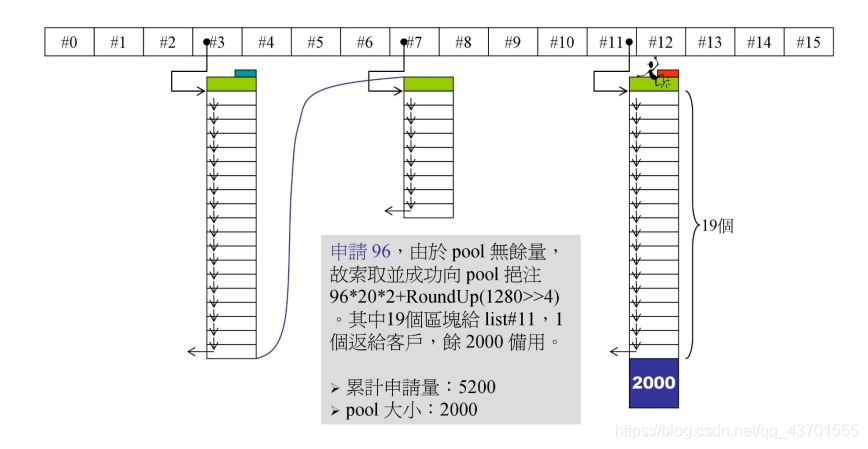
申请 96 bytes,因为pool 已经没有字节可以分配,所以先申请,将申请的到的字节存放在pool中,然后再向系统申请内存。
96 bytes 应该挂在#11 节点下,pool中剩余了 2000 bytes
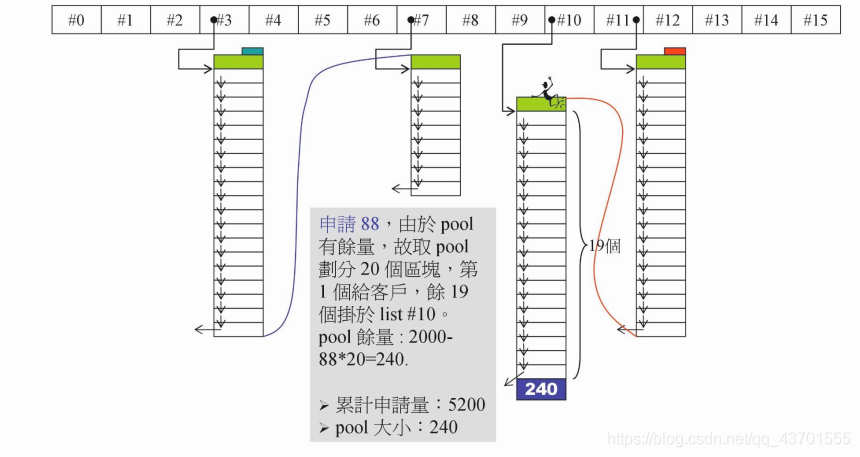
申请88 bytes,先从pool中取。
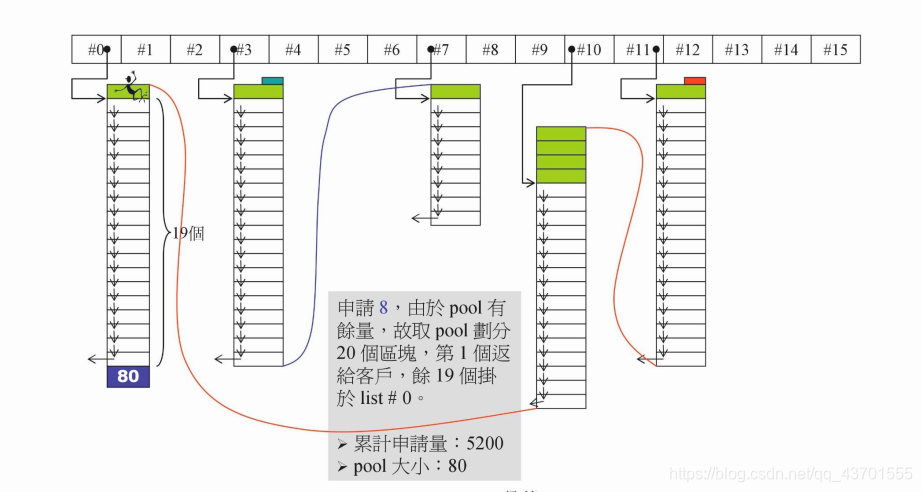
同上
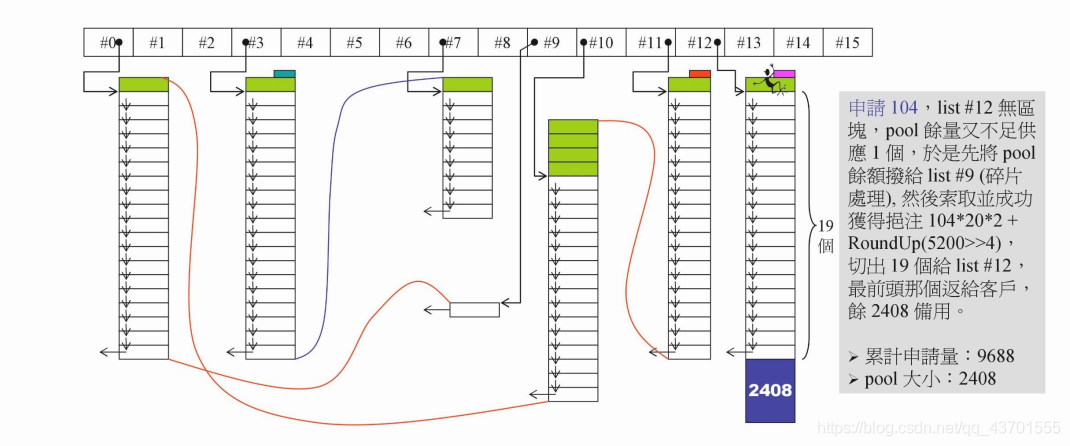
这里有一个注意点。
当我们申请的内存块大于pool中剩余的空间,但是,pool尚且还有内存,直接舍弃有点浪费。所以就现将pool中的内存先挂在对应的指针上,然后先去申请空间。
注意,上面那幅图的 #9 上还没有内存块。因为这里申请的空间为104,pool中只有80个bytes,所以先将这 80 bytes挂在 #9 上。
这样分配下去,迟早有一次系统没有足够的内存了,该怎么办?假设设置最大只能分配10000个bytes
例如 这是我们当前的场景
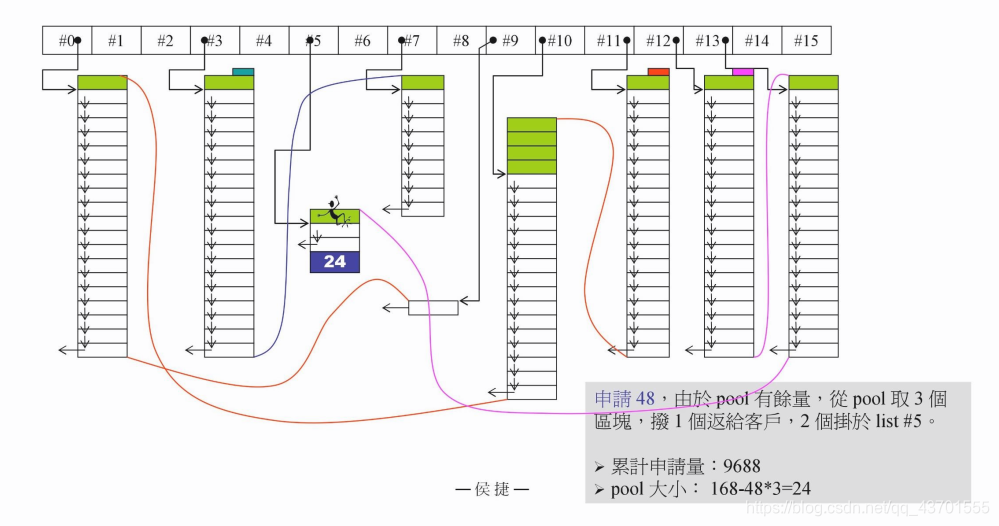
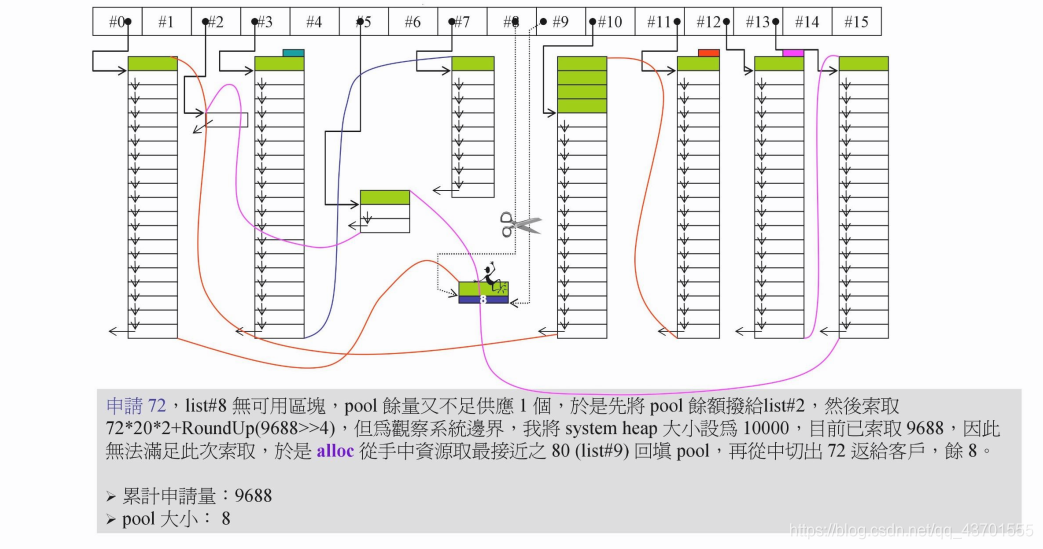
当我们申请 72 bytes时,由于pool中只剩下 24 ,不够,所以现将24 挂在 #2 上,然后向系统索要内存。
此时需要分配的内存为 72 *20 * 2 + (RoundUp(0>>4)) 远远超过了 10000(总共的内存) - 9688(已经分配的内存) = 312(剩余的内存)
重点来了
此时,alloc会向右搜索(从 #8 ),从右边多余的内存中去出一块返回给用户,然后将多余的内存放到 pool 中。但是如果没有找到一块内存的话,就分配失败了。
如图:
本来 #9 上还有一块内存,然后将这块内存分配给了 #8,然后将多余的(这里是 8 bytes),放到pool中