首先,我们思考一个问题,java中已经存在了NIO包,我们可以直接上手编写服务器了。那为什么还要再去封装一个netty框架呢?
在我之前的文章中谈到过NIO,也用NIO实现了一些简单的服务器,笔者曾经使用过“单Reactor-单线程模型”和“单Reactor-多线程模型”,后者虽然可以让Reactor只执行连接和读写工作,将业务处理都交给worker线程池,相对来说提高了性能。但这仍然不够,在这两种模式下,一个Reactor承担了所有的网络响应时间,在高并发情况下仍然存在着较大的性能问题。
netty帮我们封装了一种更高效的网络IO设计模式-->“主从Reactor模式”。在这种模式下,主Reactor负责接收服务端accept连接,将新建的Channel注册到从Reactor上,从Reactor负责事件的读写及发送,将具体的业务处理交给worker线程池处理,大大提高了性能。
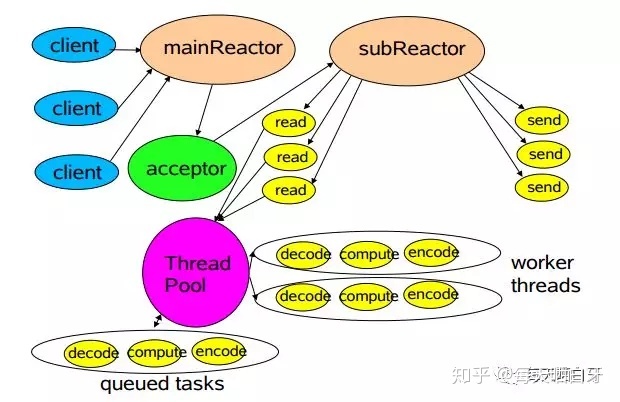
除了优秀的设计模式外,netty还有很多优点:
1.稳定性:相较于java NIO更加稳定,修复了selector的空轮询导致CPU占用100%等问题。
实际上netty并没有从本质上解决这个问题,而是以一种巧妙的方式避开了这种情况。
Netty 提供了一种检测机制判断线程是否可能陷入空轮询,具体的实现方式如下:
- 每次执行 Select 操作之前记录当前时间 currentTimeNanos。
- time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos,如果事件轮询的持续时间大于等于 timeoutMillis,那么说明是正常的,否则表明阻塞时间并未达到预期,可能触发了空轮询的 Bug。
- Netty 引入了计数变量 selectCnt。在正常情况下,selectCnt 会重置,否则会对 selectCnt 自增计数。当 selectCnt 达到 SELECTOR_AUTO_REBUILD_THRESHOLD(默认512) 阈值时,会触发重建 Selector 对象。
long time = System.nanoTime();
if (time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos) {
selectCnt = 1;
} else if (SELECTOR_AUTO_REBUILD_THRESHOLD > 0 &&
selectCnt >= SELECTOR_AUTO_REBUILD_THRESHOLD) {
selector = selectRebuildSelector(selectCnt);
selectCnt = 1;
break;
}Netty 采用这种方法巧妙地规避了 JDK Bug。异常的 Selector 中所有的 SelectionKey 会重新注册到新建的 Selector 上,重建完成之后异常的 Selector 就可以废弃了。
2.更高性能:Netty 提供了对象池、面向用户态的零拷贝技术等,在 I/O 读写时直接使用 DirectBuffer,避免了数据在堆内存和堆外内存之间的拷贝。
3.易用性:netty中封装了很多操作,为我们提供了很多现成的工具类,如
LengthFieldBasedFrameDecoder帧解码器工具类,有效地帮助我们解决了粘包拆包的问题。还有netty中pipeline和handler的设计,让开发者专注于业务的实现,而不需要过多关注其他方面。
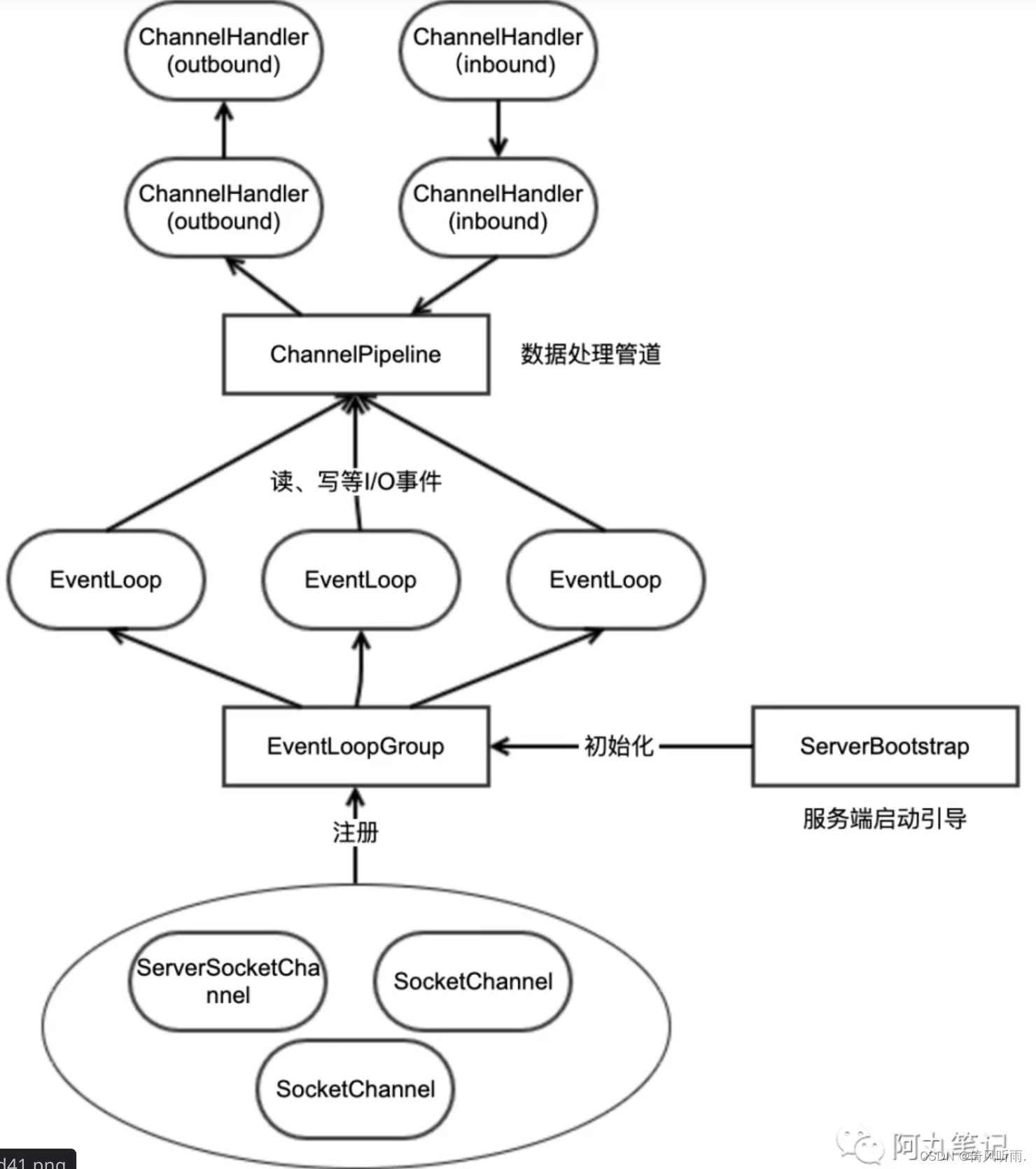
ChannlPipeline 内部是由一组 ChannelHandler 实例组成的,内部通过双向链表将不同的 ChannelHandler 链接在一起,如下图所示:

ChannelHandler 有两个重要的子接口:ChannelInboundHandler和ChannelOutboundHandler,分别拦截入站和出站的各种 I/O 事件。
从 ChannelPipeline 内部结构定义可以看出,ChannelHandlerContext 负责保存链表节点上下文信息。ChannelHandlerContext 是对 ChannelHandler 的封装,每个 ChannelHandler 都对应一个 ChannelHandlerContext,实际上 ChannelPipeline 维护的是与 ChannelHandlerContext 的关系。
ChannelHandlerContext 会默认调用 fireChannelRead 方法将事件默认传递到下一个处理器。如果我们重写了 ChannelInboundHandlerAdapter 的 channelRead 方法,并且没有调用 fireChannelRead 进行事件传播,那么表示此次事件传播已终止。
在这段时间netty的使用中,笔者发现了一些有意思的东西,在好奇心的驱使下了解了netty中的这些内容,今天来做一些总结:
一.异常
众所周知,netty在一条pipeline上串联了多个handler,每个handler上我们都可以前去自定义一种自己的操作,比如:
.addLast(new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.info("1");
super.channelRead(ctx,msg);
}
})
这个handler中没有什么操作,当然不会抛出什么异常,但是当我们添加了很多操作后,这个handler中可能就会产生异常,此时如果我们没有将异常捕捉而只是将异常在方法签名上声明,异常就会顺着入站处理的顺序在pipeline上进行传播,如果我们没有在一个handler中重写exceptionCaught方法用以捕捉异常,这个异常就会一直向后传播,直到到达pipeline的尾节点,这时tail节点会调用它的exceptionCaught方法,tail节点捕获了异常,会打出一个WARN日志,提示当前pipeline有未处理的异常抛出,如图(截取了tail节点处理异常的部分代码):
final class TailContext extends AbstractChannelHandlerContext implements ChannelInboundHandler {
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
// 处理最后的异常,方法如下
onUnhandledInboundException(cause);
}
// 省略...
}
/**
* 处理最后的异常
* Called once a {@link Throwable} hit the end of the {@link ChannelPipeline} without been handled by the user
* in {@link ChannelHandler#exceptionCaught(ChannelHandlerContext, Throwable)}.
*/
protected void onUnhandledInboundException(Throwable cause) {
try {
logger.warn(
"An exceptionCaught() event was fired, and it reached at the tail of the pipeline. " +
"It usually means the last handler in the pipeline did not handle the exception.",
cause);
} finally {
ReferenceCountUtil.release(cause);
}
}
// 省略...
}
在 Netty 应用开发的过程中,良好的异常处理机制会让排查问题的过程事半功倍。所以推荐用户对异常进行统一拦截,然后根据实际业务场景实现更加完善的异常处理机制。通过异常传播机制的学习,我们应该可以想到最好的方法是在 ChannelPipeline 自定义处理器的末端添加统一的异常处理器,此时 ChannelPipeline 的内部结构如下图所示。

在pipeline的结尾加上自己自定义的异常处理器,该异常处理器其实也就是一个入站处理器,这样,整个pipeline上所有的异常最终都会被这个类接收到,我们可以通过 以下这种方式实现对所有异常进行分类的捕捉。
nioSocketChannel.pipeline()
.addLast(new ChannelInboundHandlerAdapter(){
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
if(cause instanceof SQLException){
//具体操作...
}
//省略...
}
});
如果我们要专门写一个类来进行异常处理,需要注意要让该类继承ChannelInBoundHandlerAdapter类,并通过重写exceptionCaught方法进行异常的处理。
另一种处理方式是直接在每个handler中通过try-catch块将异常捉住并处理,不让异常通过handler进入pipeline中,这样也直接从源头上处理异常,不用像第一种方法一样需要专门写一个handler去处理异常。
二.自定义编/解码器
netty中封装了一些编解码的工具类,比如StringDecoder和StringEncoder可以将字符串包装成ByteBuf完成数据在客户端和服务端之间的传输,由于笔者在尝试使用netty框架实现一个简易聊天室,在这个项目中,客户端和服务端有很多种不同的类型的事件交互,笔者计划按照交互事件的类型设计出多种消息类别,并让它们都继承Message类,然后自定义一个继承于类“
ByteToMessageCodec<Message>”的编解码器,这个编解码器用于处理客户端与服务端之间进行交互所需的所有类型的消息。
自定义编解码器的核心步骤就是要实现将实例对象序列化成字节流,将生成的字节流写入ByteBuf中,借助ByteBuf将该字节流传输到服务端,服务端读取到相应字节流之后依靠反序列化将其转化成实例对象,这样就完成了一个实例对象从客户端到服务端的传输。消息的实例对象从服务端到客户端也是同样的道理。
但是,目前还有一个重要的问题需要解决,那就是粘包/半包问题,我们使用TCP协议进行通信,在以字节流进行传输消息时粘包和半包问题是经常会遇到的,好在netty比较给力,为我们提供了很多好用的工具来解决粘包和半包问题,比如基于行的解码器LineBasedFrameDecoder、基于分隔符的解码器DelimiterBasedFrameDecoder和帧解码器LengthFieldBasedFrameDecoder,笔者使用的就是LengthFieldBasedFrameDecoder,这个工具可以精准地解析出一个消息帧中消息的长度和消息内容的字节流。它有5个参数:
int maxFrameLength:指定一个消息帧的最大长度 int lengthFieldOffset:在传输来的ByteBuf中消息长度字段相对于ByteBuf首部的偏移量 int lengthFieldLength:消息长度字段所占的字节数 int lengthAdjustment:消息长度字段结束后一直到消息正文之间,有多少需要个跳过的字节 int initialBytesToStrip:需要剥离ByteBuf的长度(一般为0)
接下来,我们可以来看一下源码是如何进行处理的:
因为解码器先读到了消息的长度,根据长度再去截取消息内容,很容易就能处理粘包问题,这里我们着重关注一下半包问题,在当前情境下,半包又有两种情况:
1.当前半包还未包含完整的消息长度字段
2.包含了完整的消息长度字段,但是未包含完整的消息内容字段
在这两种情况下,LengthFieldBasedFrameDecoder都会直接返回null,以非阻塞的形式继续工作。
public LengthFieldBasedFrameDecoder(ByteOrder byteOrder, int maxFrameLength, int lengthFieldOffset, int lengthFieldLength, int lengthAdjustment, int initialBytesToStrip, boolean failFast) {
this.frameLengthInt = -1;
this.byteOrder = (ByteOrder)ObjectUtil.checkNotNull(byteOrder, "byteOrder");
ObjectUtil.checkPositive(maxFrameLength, "maxFrameLength");
ObjectUtil.checkPositiveOrZero(lengthFieldOffset, "lengthFieldOffset");
ObjectUtil.checkPositiveOrZero(initialBytesToStrip, "initialBytesToStrip");
if (lengthFieldOffset > maxFrameLength - lengthFieldLength) {
throw new IllegalArgumentException("maxFrameLength (" + maxFrameLength + ") must be equal to or greater than lengthFieldOffset (" + lengthFieldOffset + ") + lengthFieldLength (" + lengthFieldLength + ").");
} else {
this.maxFrameLength = maxFrameLength;
this.lengthFieldOffset = lengthFieldOffset;
this.lengthFieldLength = lengthFieldLength;
this.lengthAdjustment = lengthAdjustment;
this.lengthFieldEndOffset = lengthFieldOffset + lengthFieldLength;
this.initialBytesToStrip = initialBytesToStrip;
this.failFast = failFast;
}
}
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
long frameLength = 0L;
int readerIndex;
if (this.frameLengthInt == -1) {
if (this.discardingTooLongFrame) {
this.discardingTooLongFrame(in);
}
if (in.readableBytes() < this.lengthFieldEndOffset) {
//可读取的字节数还不到消息长度结尾时的索引,说明发生半包问题,直接返回null
return null;
}
readerIndex = in.readerIndex() + this.lengthFieldOffset;
//读取长度域的十进制值,最原始传过来的包的长度
frameLength = this.getUnadjustedFrameLength(in, readerIndex, this.lengthFieldLength, this.byteOrder);
if (frameLength < 0L) {
failOnNegativeLengthField(in, frameLength, this.lengthFieldEndOffset);
}
//此时的frameLength表示字节流内容之前全部信息的长度
frameLength += (long)(this.lengthAdjustment + this.lengthFieldEndOffset);
if (frameLength < (long)this.lengthFieldEndOffset) {
failOnFrameLengthLessThanLengthFieldEndOffset(in, frameLength, this.lengthFieldEndOffset);
}
//超过帧解码器的最大长度
if (frameLength > (long)this.maxFrameLength) {
this.exceededFrameLength(in, frameLength);
return null;
}
this.frameLengthInt = (int)frameLength;
}
//frameLengthInt指当前整个消息帧的长度
if (in.readableBytes() < this.frameLengthInt) {
// 解析完之后,发现不够一个帧长度,说明是半包
return null;
} else {
if (this.initialBytesToStrip > this.frameLengthInt) {
failOnFrameLengthLessThanInitialBytesToStrip(in, frameLength, this.initialBytesToStrip);
}
in.skipBytes(this.initialBytesToStrip);
readerIndex = in.readerIndex();
int actualFrameLength = this.frameLengthInt - this.initialBytesToStrip;
ByteBuf frame = this.extractFrame(ctx, in, readerIndex, actualFrameLength);
in.readerIndex(readerIndex + actualFrameLength);
this.frameLengthInt = -1;
return frame;
}
}
这一次的知识分享到这里就告一段落了。