汇编语言初始
汇编语言是一种低级的语言,这个语言更加接近硬件,可以绕开编译器的优化
缺点
难移植:我们为x86写的汇编语言无法使用在ARM架构下,但是对于高级语言不存在这个问题,高级的语言可以适配在任何底层硬件架构之下
优点
灵活:对于高级语言,都要受限制于底层的编译器,编译器会对指令进行优化,但是因为汇编语言和硬件打交道,所以可以绕开编译器,做各种自己需要做的事情,不经过编译器的处理
强大:可以直接对底层硬件进行控制
应用场景
- 直接访问底层硬件的地方:如写一个操作系统驱动,操作硬件
- 对性能极致的优化,不需要借助编译器进行优化
汇编语言语言语法介绍
- 一个完整的RISC-V汇编程序有多条语法(statement)组成
- 一条典型的RISC-V汇编语句包含3部分组成
[label:] [operation] [comment]
.S里面会保护一些预处理的指令
.s里面包含的就是纯粹的汇编指令
.asm里面会有一些注释,其他内容都一样
label
label可以理解为一个地址,不过给那个地址起了一个名字,任何以“:”结尾都是label
例如:看下面的代码
我们在汇编里面没有函数名这个概念,函数名对应的就是该函数所在的地址,我们把这个地址命名为label,所以我们用这个函数名就能够定位到我们需要的函数体里面
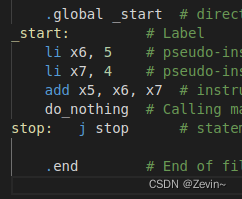
_start:
stop:
这两个都是label,其实都是对地址起了别名
operation
instruction(指令):直接对应二进制机器指令的字符串
pseudo-instruction(伪指令):为了提高编写代码的效率,可以用一条伪指令指示汇编器产生的多条实际指令(instruction)
伪指令,方便我们使用,类似就是把一个复杂的指令起了一个别名,汇编器能把他进行分解转化成真正的机器指令进行处理,
类似linux中alias ll=ls -l
还有li,sw,lw这些其实都是把一些指令起了一个别名,方便我们使用,提高效率
directive(指示/伪操作):通过类似指令的形式(以“.”开头),通知汇编器如何控制代码的产生,不对应任何具体的指令,只是汇编器里面的东西

.macro
.endm
.text
这些都是一个directive
macro:采用.macro/.endm自定义的宏,就类似于C语言的宏
comment
#开头往后的所有内容都是注释
汇编指令操作对象
寄存器
- 32个通用寄存器,x0~x31(RV32I(risc-v32位下的整数指令集)通用寄存器组),这里的每个寄存器都是32位
- 在risc-v中hart在执行算术逻辑运算时所操作的数据必须来自寄存器

xlen=32,因为是32位risc-v器,所以最低位为0,最高位为31
x0这个寄存器是一个特殊寄存器,不能对他进行写操作,我们读取出来的数据一定是0
其他寄存器都是可读可写的
pc寄存器,是不能进行访问的,内部是原来保存当前程序执行到哪个位置 的概念program counter,程序计算器
hart在执行算术逻辑运算时所操作的数据必须来自寄存器,处理完数据之后,先放到寄存器里面,保存下来,也要从寄存器里面再搬出去,放到别的地方去
内存
- Hart可以执行在寄存器和内存之间的数据读写的操作
- 读写操作使用字节为基本单位进行寻址
- rv32最多可以访问2^32个字节的内存空间
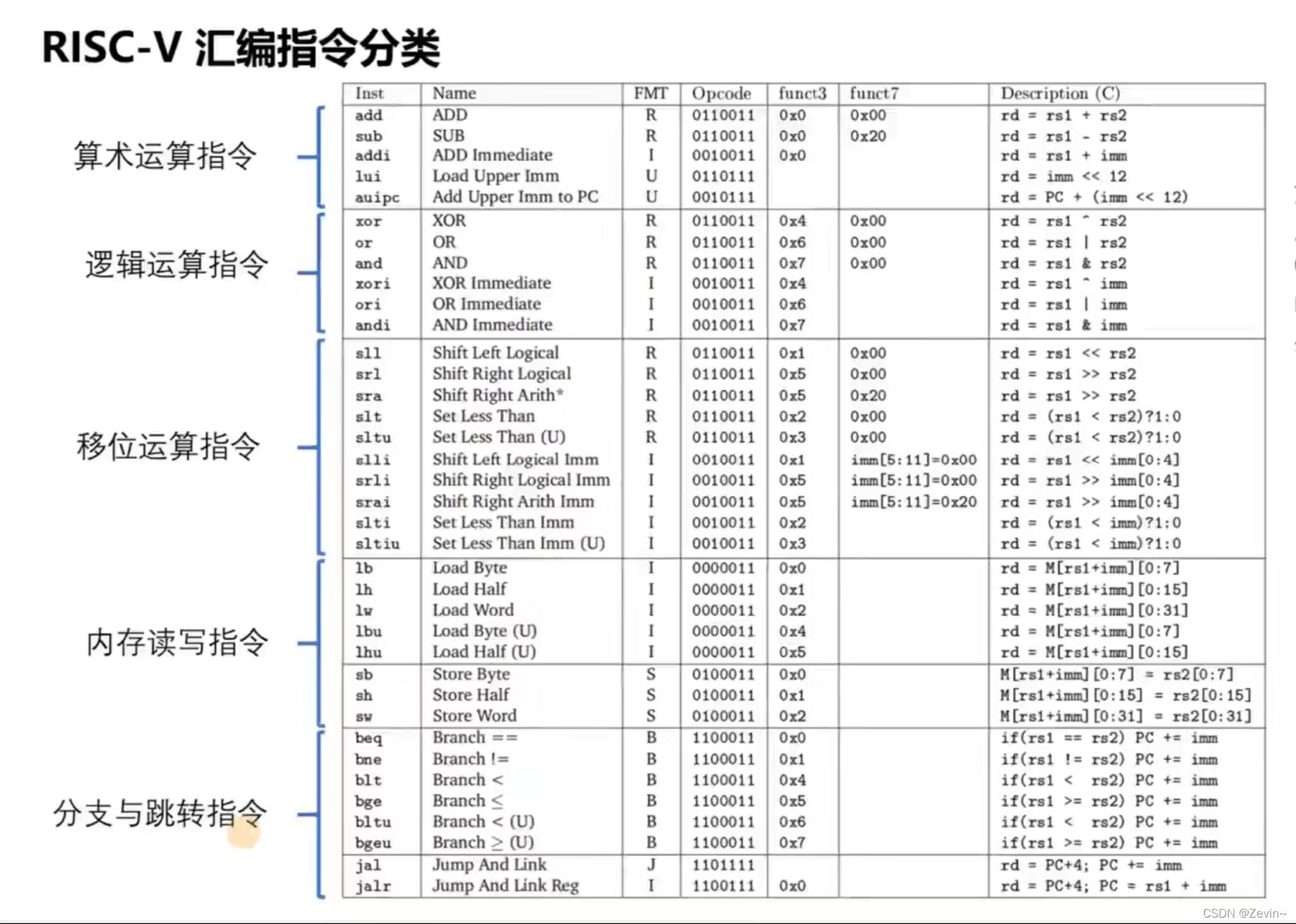
汇编指令编码格式

- 指令长度:ILEN1=32bits
- 指令对齐:IALIGN=32bits
- 32个bit划分成不同的域(field)
- func3/func7和opcode共同决定了最终的指令类型
- 指令在内存中按照小端序排列

这个是对opcode7个bit位的描述
opcode最后两位都是11
[2,4]位为一组
[5,6]为一组
我们观察上面add的opcode[2,4]=100,[5,6]=01,对比下面的指令,我们发现他对应的就是OP,说明ADD是一个基本指令
6种指令格式
- R-TYPE:每条指令中有3个field*,用于指定3个寄存器参数,rs,rd
rs:register source ,rd:register destination,例如a+b=c,则rs里面存放a,b;rd里面存放的是c,使用5个bit,代表是32位

常见的伪指令可以查看risc-v:25章