再谈端口号
端口号标识主机上特定的程序,如http的默认端口是80,我们就可以通过ip+port来找到对应的主机
端口号的划分
- 0-1023:知名端口号,HTTP,FTP,SSH等这些广为应用的协议,他们的端口号都是固定的
- 1024-65535:操作系统动态分配的端口号,客户端程序的端口号就是在这个范围内
知名端口号
有些服务器是非常常用的,为了使用方便,人们约定一些常用的服务器,都是用以下的固定端口号
- http :80
- ssh:22
- ftp: 21
- https:443
- telnet :23
执行这个命令可以查看知名端口号
cat /etc/services
传输层命令
pidof
获得进程的pid
pidof [进程名]

netstat
用来查看网络状态
n:查看信息的时候,把全部东西都显示成数字,不带n就是按照文件名和主机名的形式来进行展示
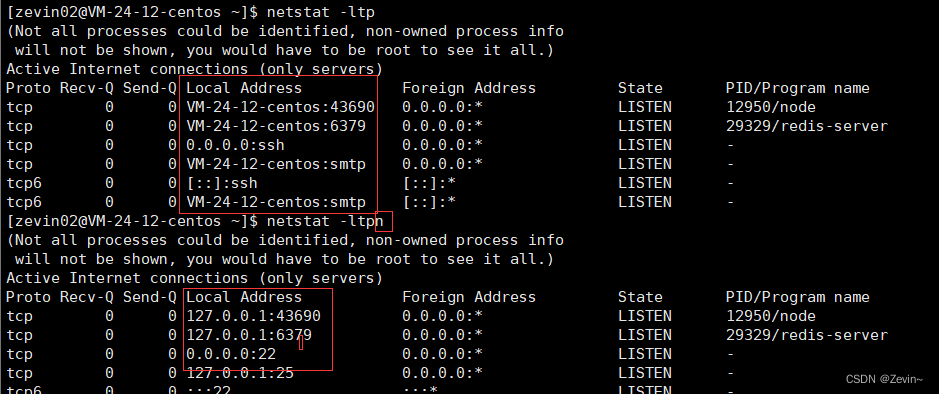
l:查看监听状态,不带的话,就是查看普通状态的套接字
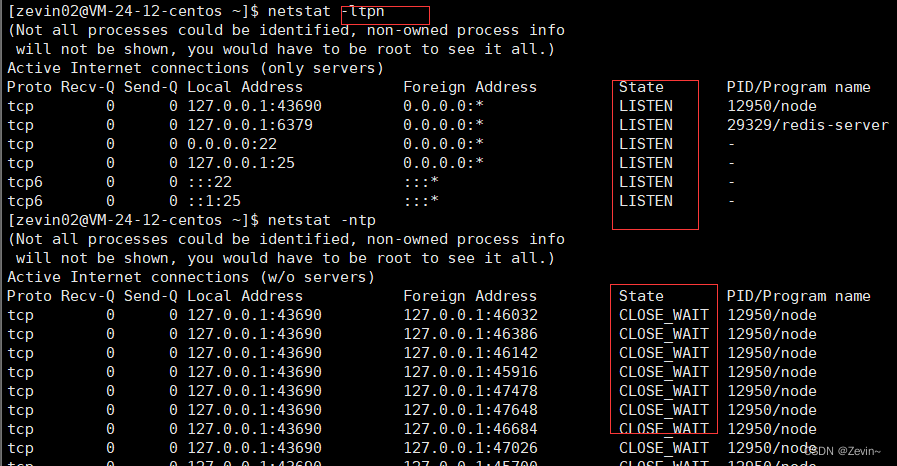
t:代表的就是查看TCP的协议 ,同理u代表的就是UDP
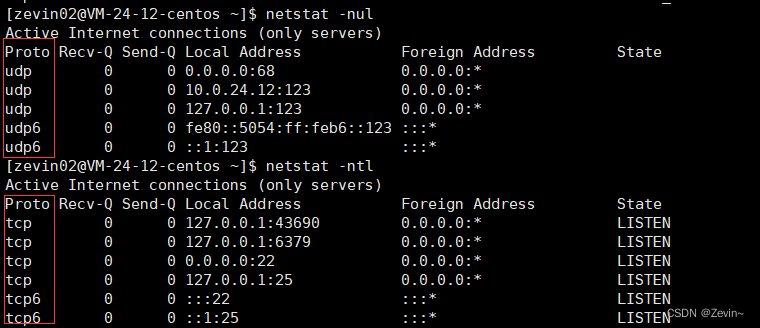
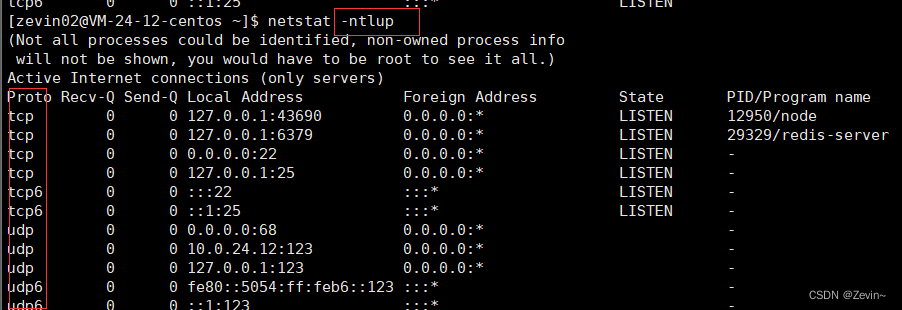
p:就是process进程,显示建立相关链接的程序名
UDP
用户资料包协议
UDP概述
UDP 作为传输层的协议,他规定了数据什么时候发送,发送多少的问题,交付给上层,是由目的端口号来完成的,有效载荷和数据进行分离的工作是由固定报文首部长度来实现的
UDP过程分析
当对端UDP 层获取到这个报文的时候,先识别8字节,然后就可以拿到这个报文的长度是多少,测试报文有没有出错,然后通过16为目的端口号,得知要标识交付给上一层的哪一个协议
一些特点:
- 报文通过目的端口号进行报文的分用,通过定长找到对应的报文长度,字段进行获取有效载荷
- UDP没有任何一个填充字段或者选项,说明他的内容很简单
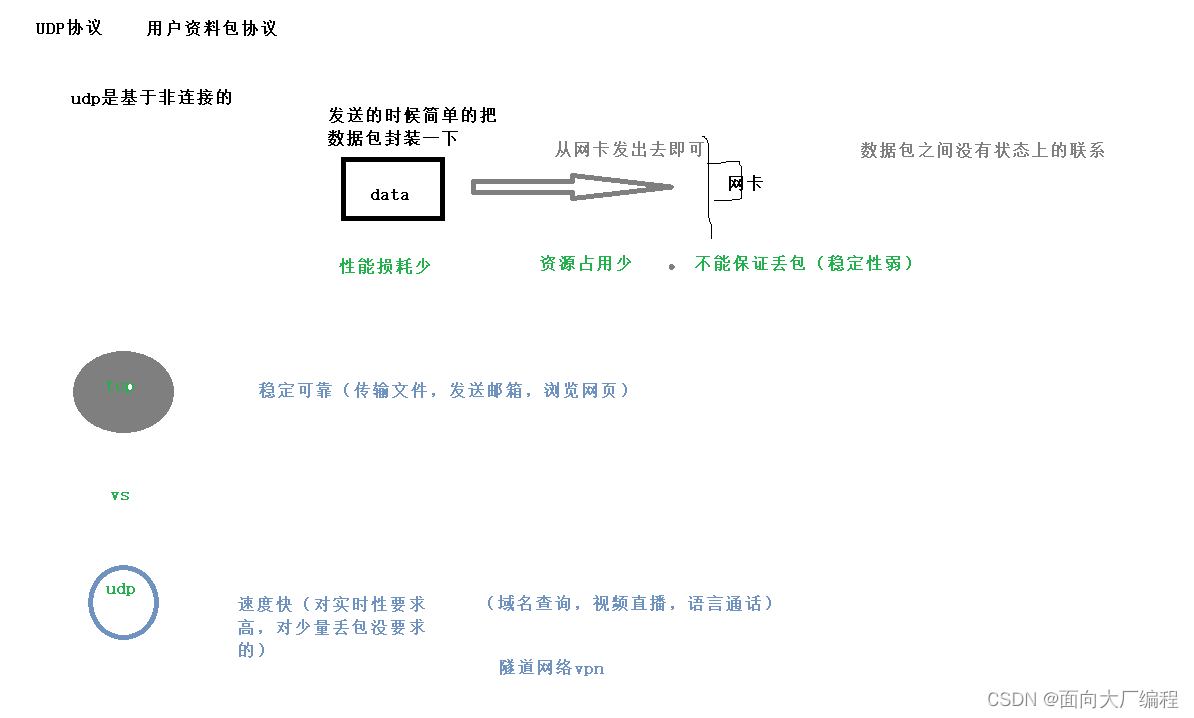
- UDP 支持一对一,一对多,多对一,和多对多的交互通信,UDP 可以提供全多工的服务,只不过不可靠
主要特点
- 无连接,知道对端的IP和端口号就直接进行了传输,不需要建立连续
- 不可靠,没有确认机制,没有重传机制,如果网络故障没有发送给对方,UDP协议层也不会发送给应用层错误信息
- 面向数据包,应用层交给UDP多长的报文,UDP就会发送多少的报文,不会拆分也不会合并(不会出现粘包问题),要么不收,要么全收
UDP 的缓冲区
- UDP没有真正意义上的缓冲区,调用sendto之后,直接将数据交给内核,由内核将数据传给网络层协议进行后续的传输动作
像read,recv,write,send这些,与其说是收发函数,不如说是拷贝函数
像这些,拷贝之后到缓冲区里面,具体该数据,什么时候发送,发多少,完全由OS(传输层)控制,[提供传输数据的策略]
- UDP具有接收缓冲区:
接收缓冲区不能保证收到的UDP 数据报顺序和发送顺序一致,如果缓冲区满了,再达到的UDP数据报就会被丢弃
UDP全双工
(两个人在吵架的时候,你吵你的,它吵它的)
与之相比半双工(两个人聊天,你说完我说,这种交叉式的方式)
- sendto,recvfrom可以同时被调用
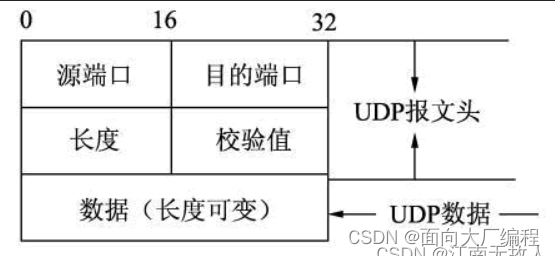
UDP报文格式
-
报头:是8个字节,是一个定长
数据在自下而上的传输过程,首先一开始通常是我们的客户端主动连接服务器的 -
既然如此,那么客户端肯定是知道服务器的端口号的,我们访问的服务器端口号肯定是众所周知的
-
长度:整个报文的长度,数据报的长度,最小为8字节(只要报头),最大为64K,如果传输的数据超过64K,需要在应用层手动的分包,多次发送,并在接收端手动拼接,最大是(2^16)
-
校验值:检测UDP数据报是否有错误,有错就丢弃,在这里计算报文,还需要加上12字节的一个伪头部进行计算,这里的校验更多是为了验证发给我的这个协议,IP的校验偏重是否有错
-
Linux Kernel是用C语言写的,请问如何看待UDP报头
struct udp_udr
{
uint32_t src_port:16;//使用的就是位段
uint32_t dst_port:16;
uint32_t total:16;
uint32_t check:16;
}
封装和解包
- 如何做到封装和解包
- 封装: 就是添加上定长报头(8字节)
- 解包 :就是把报头(8字节)和有效载荷进行分离,读取定长的报头,剩下的就是它的有效载荷
- 如何做到向上交付
- a. 报头和有效载荷分离
- b. 根据报头里面有16位目的端口号,获取之后就可以把有效载荷向上传递给对应的应用层协议
所以我们在写代码的时候,需要绑定端口号,这样底层会转发给对应的进程
- 端口号为什么是16位?:因为协议规定的
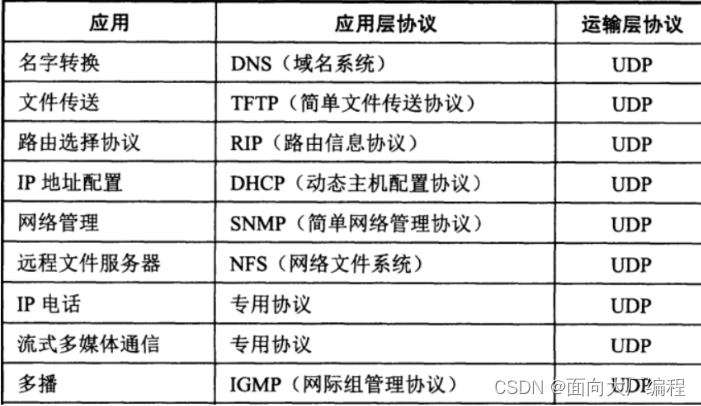
使用UDP 的应用层协议