文章目录
HTTP协议
虽然说,应用层协议是我们程序员自己定制的,但是实际上,已经有很多大佬定制了一些现成的,又很好用的应用层协议,可以让我们直接进行参考使用,HTTP(超文本传输协议)就是其中之一
HTTP协议支持cs模式(客户端服务器模式,也就是请求和响应模式)并且客户端需要以浏览器的方式访问服务器,
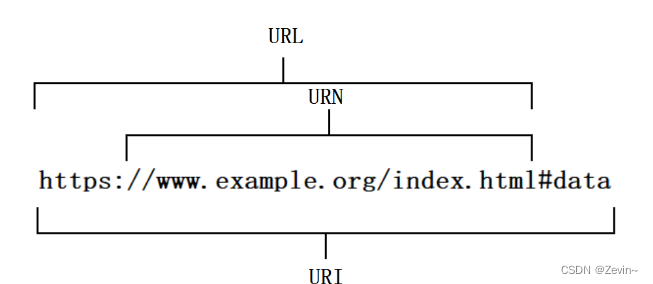
URL,URI,URN
Uniform Resource Locator
就是去确认哪一个资源在哪一个服务器上
- URN:统一资源名称:用民资标识资源
- URI:统一资源标识符,用来标识资源的唯一性
我们请求的图片,html,css,js,视频等这些都称为“资源”
服务器后台都是Linux做的
但是我们无法唯一的确认一个资源,公网IP地址是唯一确认一台主机的,而我们所谓的网络“资源”,都一定是存在于网络中的一台Linux机器上的,Linux或者传统的操作系统,保存资源的方式,都是以文件的方式来保存的,单Linux系统,标识一个唯一资源的方式,通过路径!所以IP+Linux路径,就可以唯一确认一个网络资源
ip通常都是以域名的方式来呈现的,路径可以通过目录+/来确认
https://www.nba.com/summer-league/2022/vegas/schedule
.com是ip后面跟的是linux服务器上的路径
http就是请求该资源的方法(使用的协议)
协议名和端口好是绑定在一起的,指明了协议名字就等于知道了端口号,如http端口号一定是80
URL:协议,ip 路径,?后面还可能有片段标识符

- #片段标识符,前面的内容不变,#后面发生改变,标识访问的页面的一个小分支
urlencode(转码),urdecode(解码)
有些特殊符号需要特殊处理?/+,中文字符和特殊字符会做编码,而数字字母连字符都不会做处理
C++===>C%2B%2B,不想让这些特殊字符出现在URL里面
转码规则
服务器接收的时候要进行转码
将需要转码的字符转为16进制(ascill值),然后从右向左,取4位(不足4位的直接处理),没2位做1位,前面加上%,编码成为%XY的格式
两位做一位,前面加一个%做一位就可以了
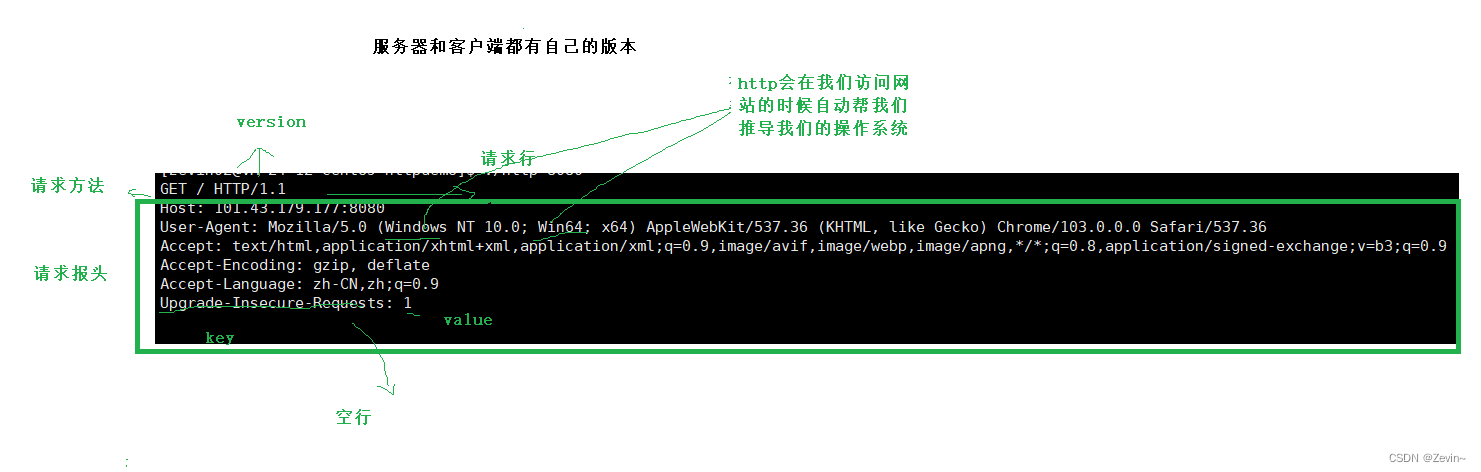
HTTP协议格式
- 无论是请求还是响应,基本上http都是按照行(\n)为单位来构建请求或者响应的!
无论是请求还是响应,几乎都是由3或者4部分组成
如何理解一个普通用户的上网行为---->主要是为了简单
- 从目标服务器拿到你要的资源(读取数据库)
- 向目标服务器上传你的数据(上传文件)
这就是IO的行为,

如果请求正文里面的请求方法是post的话,请求报头会有Content-Length属性字段来标识请求正文的长度
http操作(http的底层实际上是TCP协议 )
-
我想看看报头
-
我想发送一个响应
我们可以直接在浏览器上面输入公网ip+端口号
h t t p . c c http.cc http.cc
#include"Sock.hpp"
#include<pthread.h>
#define NUM 1024*10
void* handler(void* args)
{
int sockfd=*(int*)args;
delete args;
pthread_detach(pthread_self());
//服务器就从sockfd里面读取
//我们读取http请求
char buf[NUM];
memset(buf,0,sizeof(buf));
//http当中面向字节流读取的就是recv,专门用来网络读取的
ssize_t s=recv(sockfd,buf,sizeof(buf),0);//
if(s>0)
{
buf[s]=0;
//原封不动的把http打印出来,这个就是http的请求格式! 看看请求的样子
cout<<buf;
//读到了报头
//我们要返回响应
string response="http/1.0 200 OK\n";//响应行,版本http/1.0 状态码200 状态码解释 OK
response+="Content-Type: text/plain\n";//text/plain代表正文是普通文本,这个说明了后续的一些正文都是一些普通的文本文件
response+="\n";//这个是报头结束的标志,空行,区分报头有效载荷
response+="what are you doing \n";//这个就是正文的内容
//send也是针对TCP设计的接口
send(sockfd,response.c_str(),response.size(),0);//因为我们要写的是http响应,所以这里发送的完整的响应发送回去
}
close(sockfd);
return nullptr;
}
int main(int argc,char* argv[])
{
if(argc!=2)
{
cout<<"port"<<endl;
exit(1);
}
uint16_t port=atoi(argv[1]);
int sockfd=Sock::Socket();
Sock::Setoptsocket(sockfd);//设置端口复用
Sock::Bind(sockfd,port);
Sock::Listen(sockfd);
while(1)
{
int newsock=Sock::Accept(sockfd);
if(newsock<0)
{
continue;
}
pthread_t tid;
int* parm=new int(newsock);
pthread_create(&tid,nullptr,handler,(void*)parm);
}
return 0;
}
Content-Type(响应正文的类型)属于响应报头的属性之一
sendfile
我们可以使用sendfile接口来发送文本,该接口可以直接把一个文件的内容拷贝给另外一个文件,它是在内核里面完成的,效率都很高
sendfile
功能:把一个文件描述符里面的内容,拷贝给另外一个文件描述符,且都是在内核里面实现的,不会经过用户层,所以它的效率比read和write都要高
1. #include <sys/sendfile.h> 2. ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);参数:
- outfd:要写到哪个文件描述符里面
- infd:从哪个文件描述符里面写
- offset:偏移量,可以记录读取文件的位置,如果为nullptr,则数据要从当前文件的偏移量取读取
- count:要拷贝的文件的大小
返回值:
成功返回成功读取到的大小,失败返回-1
stat
获取文件的属性信息
功能:获取文件的属性
#include <sys/types.h> #include <sys/stat.h> #include <unistd.h> #include <unistd.h> int stat(const char *pathname, struct stat *buf);参数:
- pathname:文件的路径名
- buf:获取到的结构体
返回值:
成功返回0,失败返回-1
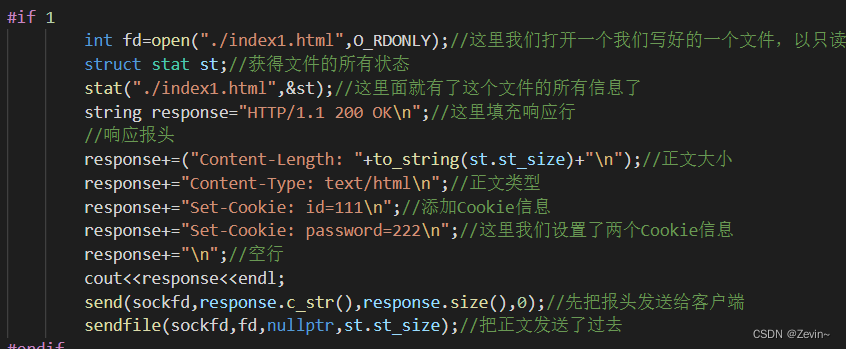
我们可以通过stat获取到文件的大小,填充Content-Length字段,然后使用sendfile接口来发送html格式的文件到套接字里面
回答几个问题
- 如何讲报头读取完毕
在读取报头时,将Content-Length属性字段读取下来(知道文件的大小),正文就读取Content-Length大小的内容,就代表将正文读取完毕
HTTP详解
我们上面的代码服务端直接recv,缓冲区设置的1024*10是不合理的
- 1.http它的请求可能不是一个一个发送的,可能是一次发送多个请求的
- 2.因为TCP是字节流的,我们上面缓冲区定义的10240,假如说发送过来的请求大小是1024,我们就可以读完,那么如果我们定义的缓冲区是1025,那么就会第一个请求读完之后,第二个请求还会读取1个字节
所以
1.保证每次读取都是一个完整的http request
2.保证每次读取都不要将下一个http request的一部分读到(残缺的报文)
- 我们如何判定我们将报头部分读完呢?
我们读取http响应都是按行读取的,读取到空行,说明报头读取完成
- 决定后面还有没有正文呢?
如果有正文,如何保证把正文全部读取完成呢?而且不要把下一个http的部分数据给读取到
我确实不知道要读取到,但是我们上面已近把报头读取完成了,这样我们就能够提取报头中的各种属性,请求的方法,URL,主机,以及Content-Length,正文长度,正文部分有多少个字节,这样就允许我们读取多少个len字节
Content-Length:自描述字段,没有正文的时候,就不存在
HTTP 的方法
1.首行:[方法]+[url]+[http版本]
2. Header:请求的属性,冒号分割的简直对,每组属性之间用\n进行分割,遇到空行说明Header部分结束
3. Body:为正文,可以是空字符串,如果body存在,header里面就有一个content-length来标识字符串的长度
现在我们讲http1.0 1.0和1.1的主要区别是:是否支持长链接
| 方法 | 说明 | 支持的HTTP协议版本 |
|---|---|---|
| Get | 获取资源内容 | 1.0/1.1 |
| POST | 创输实体主体 | 1.0/1.1 |
| PUT | 传输文件 | 1.0/1.1 |
| HEAD | 获得报文首部 | 1.0/1.1 |
| DELETE | 删除文件 | 1.0/1.1 |
| OPTION | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
说明:
HTTP/1.1在HTTP/1.0基础上增加了长连接和缓存处理等内容,
- HTTP/1.0是基于请求和响应的,每次发送请求都需要重新建立连接,获得响应之后再关闭连接,当然这样频繁的申请套接字释放套接字,对于效率来说,太低了,
短链接:一个请求,一个响应,close socket,
一个请求就是请求一个资源,链接就自动关闭
原因
- 网络不好,2.需求小 3.上网的人少,短链接就足够了
- 而HTTP/1.1是支持长连接的,客户端可以通过一个连接向服务器发起多个http请求,上层依次读取请求之后,还会继续保持连接,这样就不会因为建立连接而消耗时间了,在所有的数据全部发送完之后,在关闭连接
长连接多使用在操作频繁,点对点的通信,连接数不能太多的情况,
而像一些WEB网站一般都是使用短链接,因为长连接对于服务器来说会消费一定的资源,向WEB服务器由成千上万的客户端连接,每个用户不是频繁的操作,所以使用短链接就可以了
HEAD方法,可以获得响应的报头,只有报头,没有正文
GET就是除了获取报头,还有正文也会获得出来
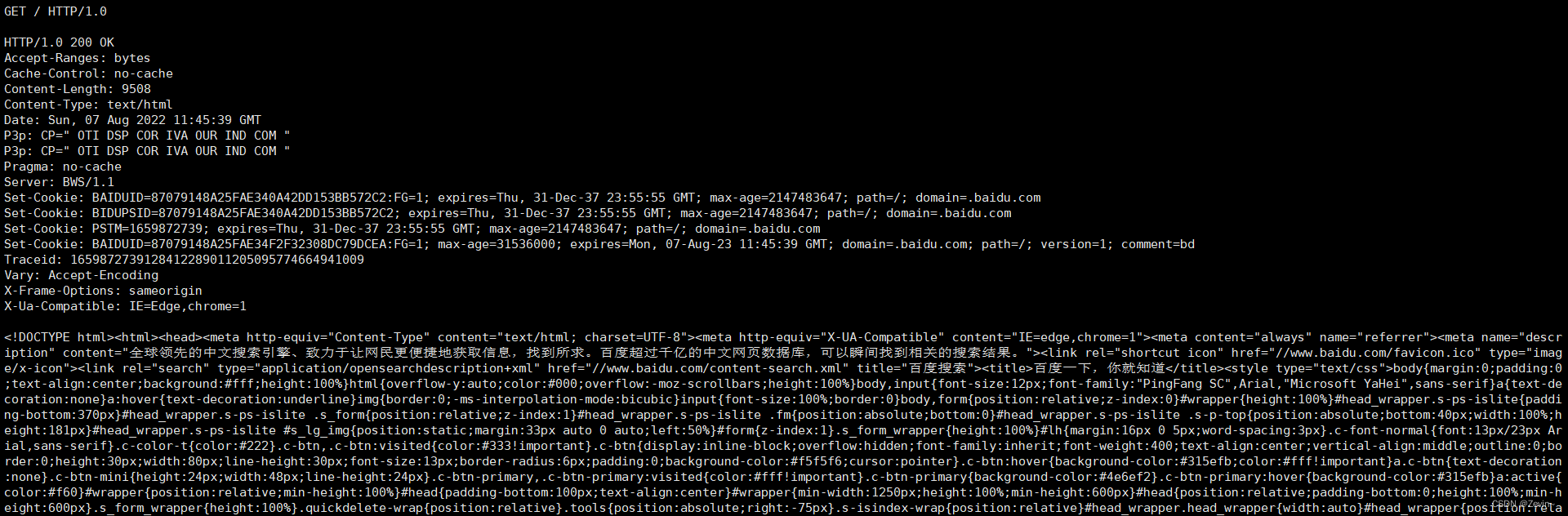
OPTIONS:询问支持的方法,有可能用协议的人把它给关掉了
GET和POST
我们要知道http请求的/并不是根目录,而是叫做web根目录
如果我们访问一个web,后面不带路劲,默认访问的就是web的根目录,而这里我们显示的带了我们要访问的路径,这里就是我们要访问的路径
/:我们一般要请求的一定是一个具体的资源
如下面我们使用的,但是如果是/,意味着,我们要请求该网站的首页
一般就是index.html or index.htm
所以我们所有的网站都要有首页信息

这里我们介绍两个方法:GET和POST
- GET可以直接获取资源,还可以上传数据,通过URL进行参数的传递(?a=10&b=20)
- POST上传数据,通过正文进行传参,包头中还会有携带Content-Length字段,说明正文内容大小,
用get的方法之后,路径后面就会夹带参数
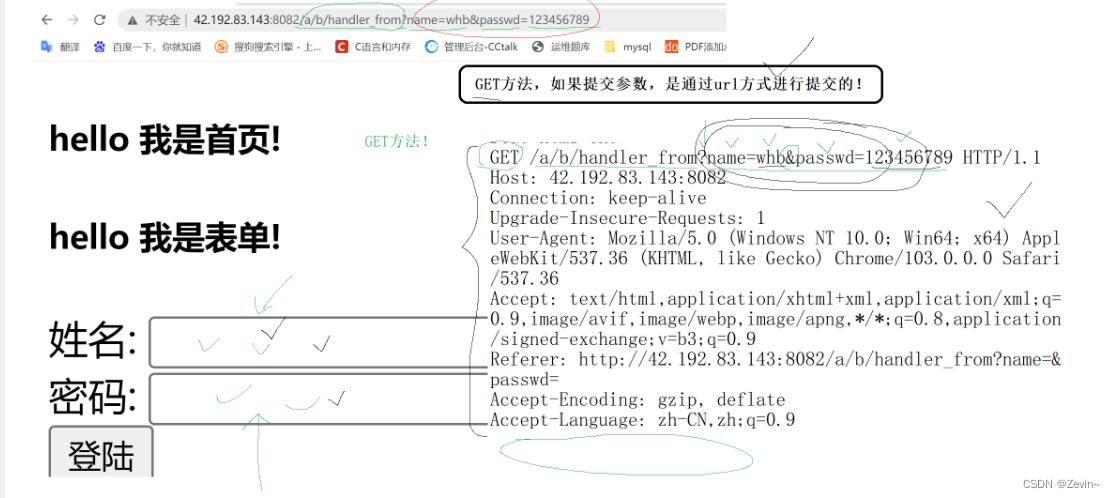
?后面就是参数
GET方法:如果提交参数就是通过url方式进行提交的,拼接到路径的后面,让http服务器拿到这样的数据,这样前面的数据就被后端的代码拿到了,这样就能通过字符串分割获取到姓名和密码
POST方法
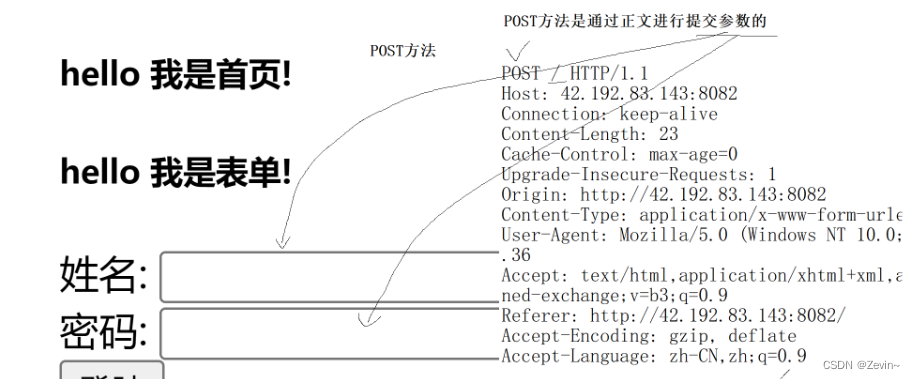
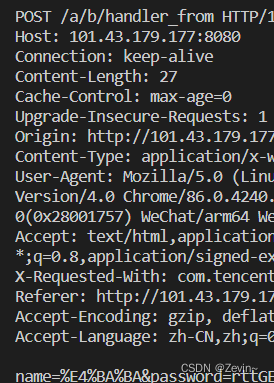
POST:参数会跟到正文后面,通过正文进行提交参数的,
GET和POST方法
- 第一批结论
GET
GET:方法叫做:获取,是最常用的方法,默认一般是获取所有的网页,都是GET方法,都是如果GET 要提交参数()是通过URL进行参数拼接从而提交给server端
POST
POST:是提交参数比较常用的方法,但是如果提交参数,一般是通过正文部分进行提交的,但是不要忘记,Content-Length,表示参数的长度
- 第二批结论:区别
安全就是要加密
参数提交的位置不同
- post方法比较私密(!=安全),因为不会回显到浏览器的url输入框里面,而get方法不私秘,会讲主要数据回显到url的输入框里面,增加了被盗取的风险
- get是通过url进行传参的,而url是有大小限制的,和具体的浏览器有关,post是通过正文传参的,没有大小限制
- 第三批结论:如何选择
- GET:如果提交的参数,不敏感,数量少,就可以使用GET
- POST: 否则就用POST
HTTP协议处理,本质就是文本分析
所谓的文本分析:
1.http协议本身的字段
2.第一行拿出来,请求方法,
里面 kv值,
3.提取参数,get,post就是前后端交互的重要方式
HTTP状态码
应用层是人参与的,人水平参差不齐,http的状态码很多的人根本就不清楚如何去使用,又因为浏览器种类太多了,有的浏览器也不会对这个状态码有处理,对浏览器没有正常的指导意义,就正常的显示你的网页(not found也是服务器给我们操作的),
| 1XX Informational(信息性状态码) 接收的请求正在处理,服务器担心客户端因为太久没有接收到回应而关闭掉,就发送这个状态码,表示没有出错,只是需要时间执行(少见) | |
| 2XX Success(成功状态码) 请求正常处理完毕 | |
| 3XX Redirection(重定向状态码) 需要进行附加操作完成请求 | |
| 4XX Client Error(客户端错误状态码) 服务器无法处理器,客户端发送的服务器没找到 | |
| 5XX Server Error(服务端错误状态码) 服务器处理请求出错,服务器出现问题了 |
常见的状态码
- 200(OK)
- 301(临时重定向)
- 302
- 307(永久重定向)
- 403(Forbiden):表示没有权限,如果不是vip登录一个需要回会员的视频,就会提示forbiden
- 404(Not Found):没有这份资源(如果是404,不能靠浏览器帮我们做什么,而是要我们自己对于404有所操作,构建一个响应告诉别人我这个资源不存在),这个属于客户端问题
- 504,500,503(Bad Gateway):服务器错误,如,创建线程错误,做字符串分析,程序崩溃,算法有问题,构建任务,与服务器逻辑出错了,就是服务器错误,等等
3xx:重定向必须需要浏览器给我们提供支持的,浏览器必须要识别301,302,307这些状态码,server要告诉浏览器,我应该要去哪里Location:就是我们的新的地址
这个状态码是有特殊含义的,主要是重定向,
- 永久重定向:301,通常用来网站域名的更换,域名的替换
- 临时重定向:302 or 307
重定向:当我们在访问一个网站的时候,可能会跳转到另一个网址,-----》永久重定向
当我访问某种资源的时候,提示我登录,跳转到了登录页面,输入完毕密码,登录的时候,会自动跳转回来(登录,下单)----》临时重定向
- 永久重定向----》例如:一个网站已近被废弃了,但是老用户不知道,还去访问,那么就会跳转到新网站,新用户登录新网站不受影响,这个网站就是被永久重定向(一个客户端,访问的时候,服务器不提供服务,告诉新网站,重新发起请求,如果有收藏的话,这个网站也会被更新,直接就访问新的网站,)-------------》通常用来网站域名的更换,域名的替换
- 临时重定向----》
HTTP常见的报头属性
- Content-Type:数据的类型(常见的有text/plain《普通的文本文件》,text/html《html文件》)
- Content-Length:正文的长度,大小,我们可以使用stat来获得
- Host:客户端请求的资源再哪一台主机上的哪一个端口号
- User-Agent:声明用户的操作系统和浏览器版本信息
- Referer:当前页面是从哪一个页面跳转来的,例如我们要从a页面跳转到b页面,那这个referer就是a页面
- Location:告诉客户端接下来要访问哪里,搭配3xx状态进行使用
- Cookie:用于在客户端存储少量信息,通常用于实现会话(session)的功能
- Connection:keepalive表示长连接,表示请求网页的时候不会关闭套接字,只到我们关闭浏览器才关闭套接字,如果没有这个字段,或者是close就是短链接
- Accept:字段表示客户端所能解析的文件格式
- Set-Cookie:服务器向浏览器设置一个cookie,把后面的内容写到cookie文件里面,此后,每次访问都把这个信息带上
长短连接
一个大型的网页,是由非常多个资源组成的,每个资源访问都要发起一个http请求,就需要多次http请求,这个就是短链接的一个策略,每个资源都要请求,所以http/1.0=短链接,http/1.1之后就是长连接,而http协议是基于tcp协议的,再得到一个资源后,里面又包含连接,还会自动取建立连接去获取资源
tcp通信(建立链接-传输数据-断开连接),每一次请求都要执行上述过程,很耗时,我们想要一个网页,网页里面有3个图片,就需要建立4次连接获得这个完整的网页,但是浏览器会帮我们自动执行,一个连接干一件事情
keep-alive,长连接。先建立一个请求和响应链接,这样每次访问的时候,都是复用原来的资源,通过减少频繁建立tcp连接,来达到提高效率的目的1一个连接干全部事情
Cookie与Session
我们介绍一下Cookie,我们知道,http的几个特性
- 无连接:http发送的请求和响应是不用关心连接的,因为底层的TCP已近做好了连接
- 无状态:http不会记录对方的状态的,每次发起的http请求,不关心之前的请求和之后的请求,只关心当前的请求不记录上下文信息
经验中:
再网站,网站是认识我的,再各种页面跳转的时候,本质上都是建立各种http请求,网站照样认识我,
其实这个不是http本身要解决的问题,主要是用来解决网络资源获取的问题
http可以提供一些技术支持,来保证网站具有“会话保持”的功能
我们在浏览器登录一些网站的时候,要输入账号密码进行登录,由于HTTP是无状态,所以每次我们再访问这些网站的时候,我们还要重新再进行登录
但是如果每次都这样的话,就显得很麻烦,所以浏览器一般都会有一种Cookie和Session机制,它可以记录上一次请求的一些消息,这个机制是独立于HTTP的,用来保存用户的状态信息
Cookie:主要做会话管理
登录一个网站,就叫做建立会话的过程
- cookie其实是一个文件,在浏览器中,文件里面保存的是用户的私密信息
- http协议:一旦该网站对应有cookie,后续再发起任何请求的时候,在报头属性里面都会自动携带cookie信息(浏览器),这样服务器就认识了你
-
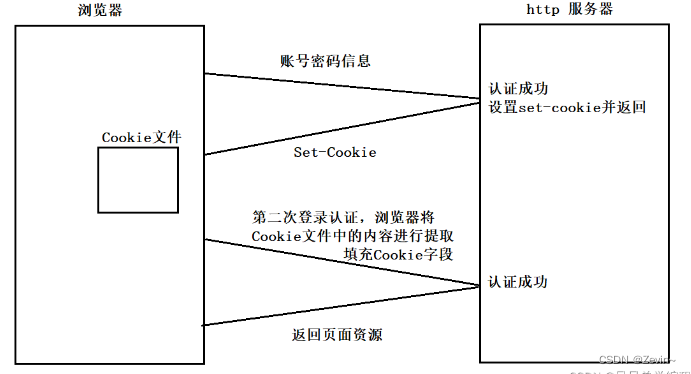
在登录一个网站的时候,用户第一次在浏览器输入账号密码并且提交到服务器发起认证请求,服务器就会核实数据库,认证成功之后,会设置Set-Cookie,然后将Set-Cookie响应给浏览器,浏览器会将Set-Cookie的值进行提取,然后保存在一个cookie文件(在登录成功之后生成的Cookie文件)里面,这样浏览器就可以保存了用户的登录认证信息
-
下一次再访问这个网站的时候,浏览器会自动将cookie文件里的内容进行提取,并填充到请求报头的cookie字段里面,这样服务器也就自动完成了认证,也就实现了免账号密码登录的功能.
-
Cookie文件分为内存级别和文件级别,前者是浏览器关闭,cookie就没了,浏览器就不认识我了,后者是保存在本地磁盘,可以永久保存
Set-Cookie
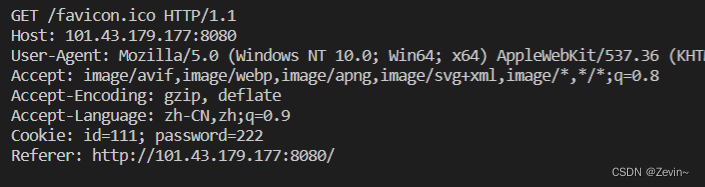
后续的请求都把cookie信息加进去了,服务端每次都要对身份进行认证的
Cookie带来的问题
如果别人盗取了我的cookie文件,这样,1. 别人就能以我们的身份访问特定的资源,2. 如果保存的是用户名密码,就很糟糕了
cookie文件容易被任意恶意软件盗取,或者一些非法钓鱼网站获取,这样非法用户就可以拿着我们的Cookie文件登录我们登录过的网站了,这样就会造成信息泄露
有安全隐患
cookie和session共同解决
为了解决cookie文件泄露的问题,所以才又引进了一种机制Session,将cookie和session结合起来使用就可以减少信息泄露的可能性
核心:将用户的私密信息保存在服务端
我们在上面cookie机制的基础上,增加了一个session机制,浏览器第一次想服务端发起的请求,
- 服务器会创建一个Session将用户的信息进行保存,形成Session文件(比如叫123,每个人都要有唯一的文件),保存在服务端的磁盘中,用来确认用户的身份,
- 后构建响应,设置Set-cookie: session_id=123(文件名),服务器会将这个Session ID进行返回,给浏览器,
- 浏览器会将Session ID保存在Cookie文件里面,
- 以后每次认证都是使用Session ID来进行的,之后每一次请求都携带这个session_id,之后的认证就是服务端通过session_id找到对饮的文件,就能找到信息进行认证,后续Server依旧能够认识client
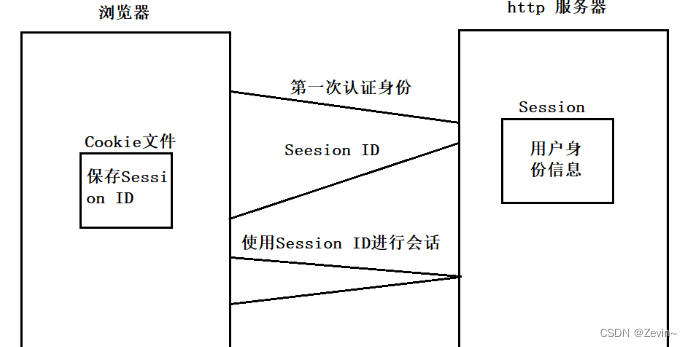
重新登录,旧的session_id 也就失效了
把session_id删除掉,也就下线了
这样,Session通过服务器端记录的信息确认用户的身份,Cookie通过在客户端记录信息确认用户身份,当然Session也是有时间限制的,Cookie的文件大小也限制在4K,这样就可以比单纯的使用Cookie更安全
HTTPS
基本概念
现在浏览器默认都是https,安全性强
HTTPS是http的安全版本:也叫超文本传输协议,HTTPS会对要传输的数据进行加密,由SSL软件层来提供加密基础,这样HTTPS就比HTTP更加安全了,可以理解为
HTTPS=http+SSL/TSL《数据的加密解密层》,SSL和TSL选择一个,SSL(Secure Socket Layer )安全套接层协议,TLS(Transport Layer Security)安全传输层协议
在网络中走的时候,http的有效载荷全部都被加密了
原本的情况是http后直接经过系统调用就到了下面,现在是又加上了数据加密层,后才经过下面

加密方式
- 对称加密:密钥(只有一个)X,使用同一把密钥进行解密
用一个X进行加密,也要用一个X进行解密
发送端,我们都有一个密钥
int data=10;//这是我们实际的数据
int result=data^x;//这个是我们加密之后的数据
send (result);
接收端
recv(result)
int data=result^x
//这里的data就是解密后的数据
- 非对称加密:有一对密钥:公钥和私钥,(RSA)
可以用公钥加密,用私钥解密
用私钥加密,用公钥解密
一般而言,公钥是全世界公开的,而私钥是必须自己进行私有保存的
- . 形成数字签名(一个文本唯一的标识符)
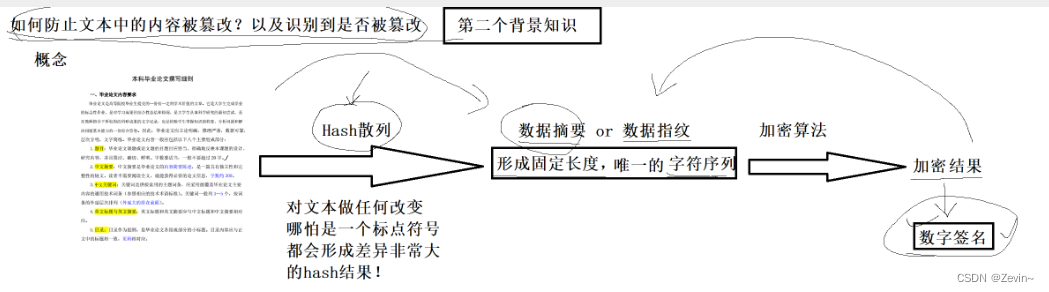
- . 发送,将文本和数字签名作为一个整体进行发送

- 校验
客户端检验:
分别将文本和数字签名拎出来
对文本采用相同的hash散列,形成一个数字摘要
对得到的数字签名进行解密,得到数字摘要
如果两者相同,则没有问题

HTTPS 的通信方式
对称加密的弊端
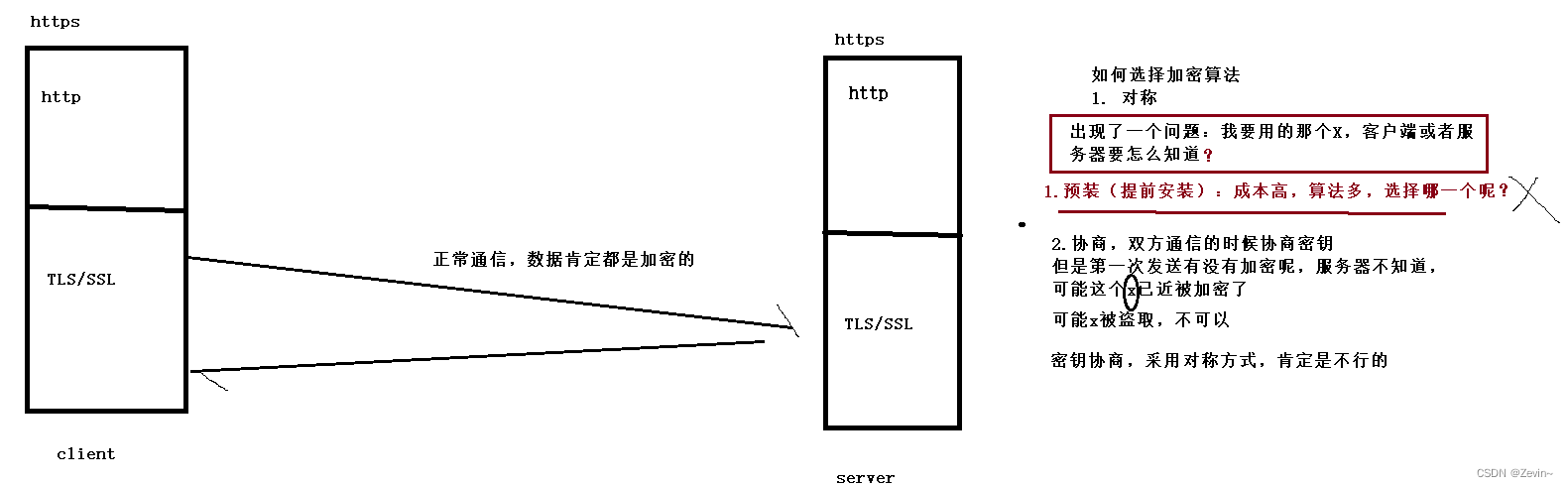
非对称加密的用处

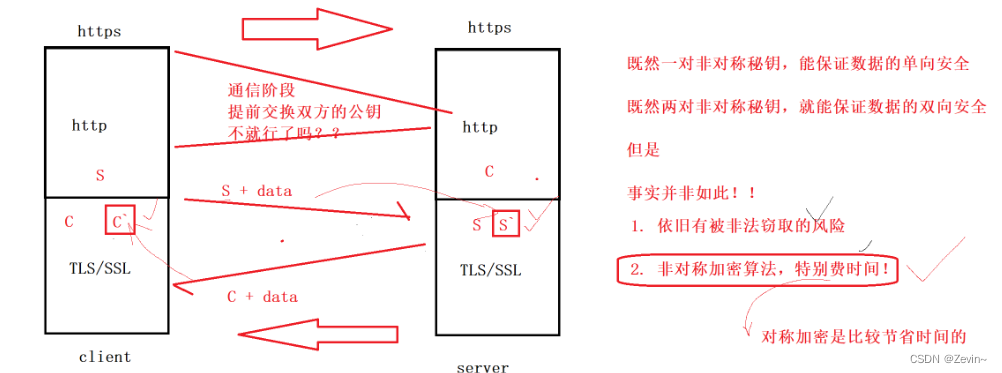

但是这样在密钥协商阶段也是有安全隐患的

本质问题:client不知道发来的密钥报文是不是合法的服务方发来的,这里就有一个证书机构
CA证书机构:只要一个服务商,经过权威机构认证,该机构就是合法的

什么叫做安全:
不是让别人拿不到就叫做安全,而是拿到了也无法处理
HTTP和HTTPS的区别
- HTTP使用明文传输数据,HTTPS使用密文传输数据,中间有一层SSL或TLS进行加密更安全
- HTTP使用的端口号是80,HTTPS使用的端口号是443
- HTTPS需要申请证书