TCP和UDP协议发生在传输层
传输层主要处理:端到端的连接
TCP和UDP
UDP 是一个人面向无连接的,可类比成写信,UDP发送写信到邮箱之后,对方不能够立即就可以收到,先后发送的信件也不一定是按照顺序接收,甚至里面信的内容有可能也不会完整
而TCP可以类比成电话,我们拨打电话到对方接通,互相通话,结束后挂断,这些都能够完成,并且能够确认对方是否能够接收到数据,
为什么要有TCP/IP 协议
数据的IO操作,硬件的数据到另外一个硬件上面也是需要有协议的,在冯诺依曼体系中,也是设计一个硬件和一个硬件之间都是相互独立的,硬件之间的通信也都是需要协议(因为有“线”)
总线就是用来解决通信的问题
一个单处理器系统中的总线有三种
- CPU 内部连接各个寄存器及其运算部件之间的总线,称为内部总线
- CPU 同计算机系统的其他高速功能部件(存储器,通道等互相连接的总线),称为系统总线
- 中,低速度IO设备之间互相连通的总线位,IO 总线
结论
- 在网络中的各个设备,各个电脑之间也是直接或者间接使用“线”来进行连接的
- 只不过网络中,“线”变的更长了,可以通信的距离变遥远了
- 因此一旦传输距离变长的话,就需要一些协议来保证数据可以可靠的到达
TCP(传输控制协议)
TCP在两个端点(应用程序之间提供了可靠的,面向连接的,双向字节流通信信道)
TCP端点:表示TCP连接一端的内核所维护的信息(通常会进一步对这个术语进行缩写),“一个TCP端点”或者“客户端TCP”来表示“客户端应用程序所维护的TCP端点”
TCP 实现有效的载荷和首部分离是通过4位首部实现的
TCP实现交付给上层工作是由16位目的端口号**
假设首部长度为6,说明选项有4字节,这样就可以完整的读取报头数据,然后数据的读取可以根据数据的协议做处理,
TCP 报文格式
1行就是4个字节
TCP 标准长度20个字节
4位首部长度[0000,1111]
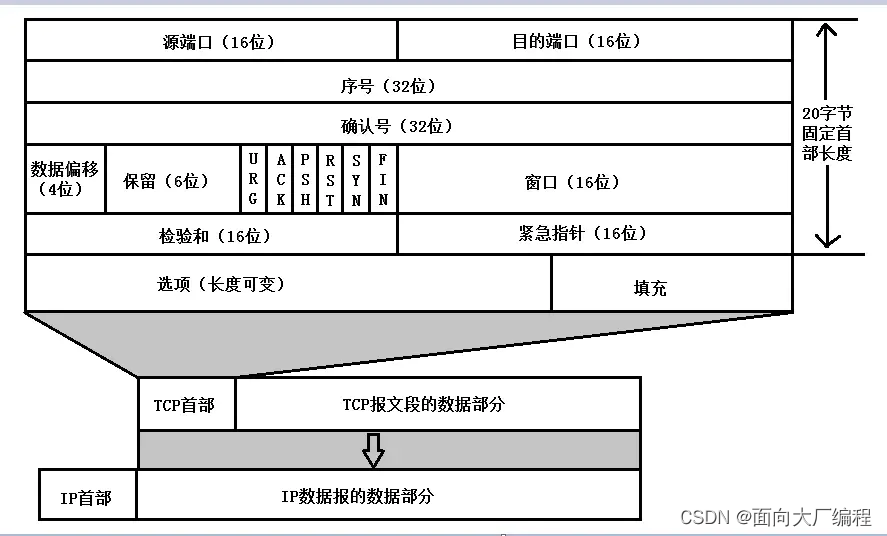
序列号 : 序列号: 序列号:
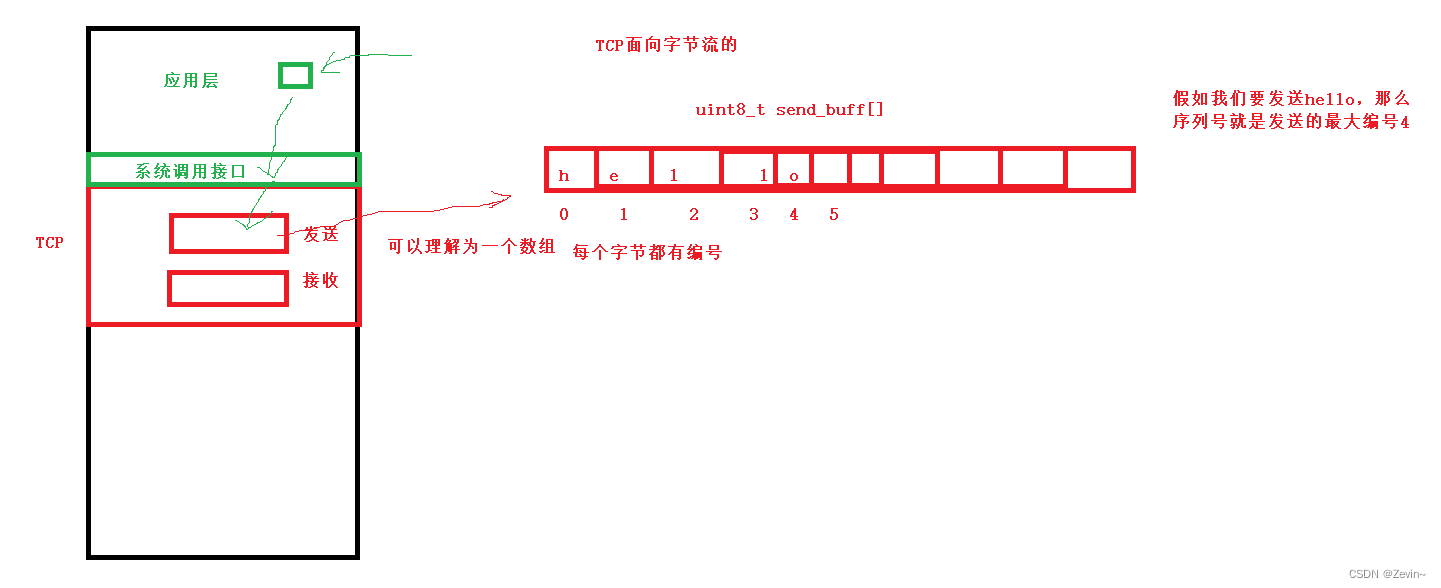
TCP 连接中发送的每一个字节都是按照顺序编号
在建立连接的时候,设置整个要传送的字节流的其实序号为计算机生成的随机数
序列号则是本报文段发送的第一个字节的序号,
确认号 确认号 确认号
是对历史确认报文的序号+1,是期望收到对方下一个报文段的序列号,而且确认号为N,表示前N-1为止的数据 都已经正确收到了
首部长度 首部长度 首部长度
里面记录的是报头长度
基本单位是4字节,如果首部长度是1,那么实际长度就是1 * 4=4,表示TCP 头部有多少个32为bit(有多少个4字节),因为是4位所以TCP头部最大长度是(1111)15*4=60
最小是固定20个字节,我们一般都是长度都是20,所以20/4=5,填充的是0101
所以当我们读取到一个完成的TCP报文,提取到前20个字节(标准长度),从里面分析到报文长度,确认报文是20个字节,剩余的就是有效载荷,提取,
窗口大小 窗口大小 窗口大小
表示自己接收缓冲区剩余的空间大小,要求对方发送数据的时候要考虑到这一点,这个值通常是变化的(16位)
校验和 校验和 校验和
校验的范围包括首部和数据
发送端填充CRC 校验,接收端校验不通过,则认为数据有问题
紧急指针 紧急指针 紧急指针
指出了紧急数据的末尾在报文段中的位置,和URG搭配使用,
因为TCP都是按序到达的,每一个报文,什么时候被上层读到都是确定的,
如果想让一个数据尽快的被上层读取,可以设置URG:表明该报文携带了紧急数据,需要优先读取
16位紧急指针就会指向对应的地址
tcp的紧急指针只能传输1个字节
六位标志位 六位标志位 六位标志位
server首先要面对的是,有大量的TCP报文,如何区分报文的类别
例如送外卖,普通外卖,美团,饿了吗怎么区分,不同的人有不同的策略
这些标志位可以用来区分不同种类的TCP报文
每个标志位都是一个bit,要么是0,要么是1
URG(urgent):为1代表了紧急指针有效,和16位紧急指针搭配使用
ACK:为1代表有效,连接建立后所有的报文ACK都是1,确认报文,几乎所有的TCP报文都会设置ACK
PSH(push):告知对方尽快的将数据向上交付,避免缓冲区被打满了,发送方无法发送
RST(reset):表明出现了严重差错,必须释放连接重新建立,重置异常连接
SYN:为1代表了这是一个连接请求,链接请求报文
FIN:通知对方,本端要关闭了,我们称携带FIN 表示的为结束报文段,断开连接报文
选项 选项 选项
选项的首部-标长
60-20=40,选项的最大长度
确认应答机制
tcp并不是百分之百可靠的!因为总会遇到一条消息没有被应答,但是只要一条消息有应答,我们就能确认该消息被对方100%收到了,世界上不存在100%可靠的,因为不能确认它丢了还是被应答了
TCP可靠性的核心机制:确认应答机制,按序到达
- 发送的数据对方收到并发送确认就保证了数据是发送成功的
- 为了避免发送的数据出现混乱,使用序列号
- 确认序号保证之前发送的数据发送成功,按序到达,确认是哪一个报文发送成功
- 无论是数据还是应答,本质上都是:一个完整的tcp报文,可以不携带数据,但是一定是一个完整的tcp报文,源端口目的端口,这些都要有
- 一个报文为什么既有序号又有确认号
因为tcp是一个全双工的通信协议(我给你发消息的同时,你也可以给我发送消息),你在给我确认的时候,我也可以给你确认
有可能是既有自己要发送的报文的序号,也同时有对对方报文的确认
通过确认应答机制能够保证我的历史数据被收到了
缓冲区
TCP协议,是自带发送和接收缓冲区的!
(TCP malloc2段内存空间)
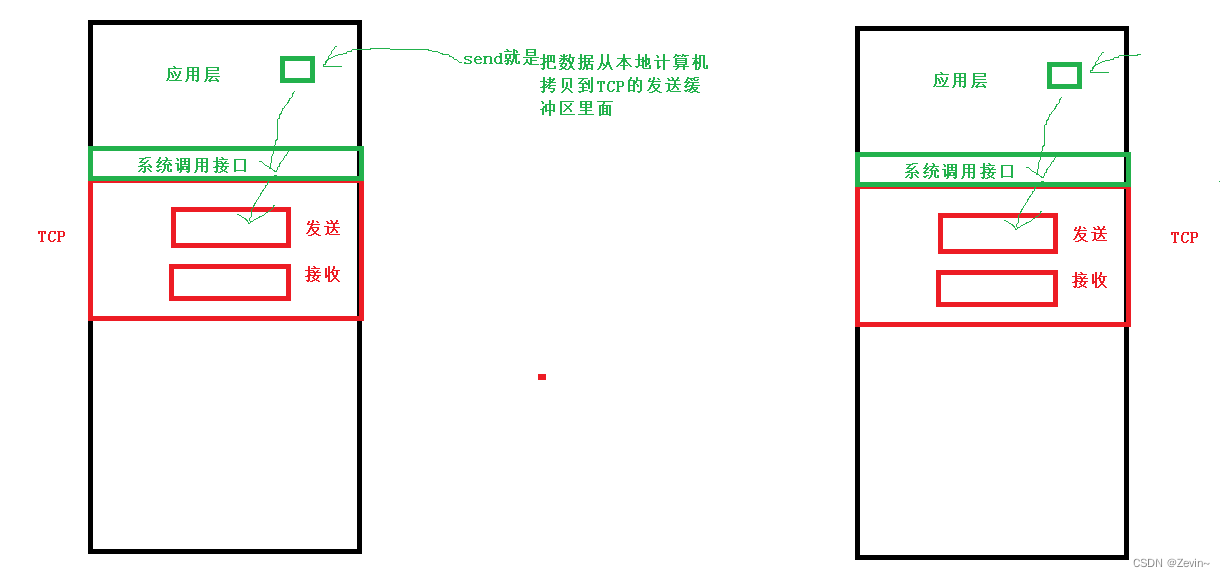
- write/send:与其叫做发送接口,不如理解成拷贝函数,send是把数据拷贝到TCP的发送缓冲区里面,接下来TCP 就把发送缓冲区里面的数据,直接发送给对方的接收缓冲区里面
- read/recv:与其叫做接收窗口,不如叫做拷贝函数,recv是把数据从TCP 的接收缓冲区里面拷贝到本地,有的时候会阻塞住,是因为缓冲区里面没数据,不是网络里面没数据
为什么要有缓冲区?
- 提高应用层效率:应用层把数据拷贝到缓冲区里面,就可以直接返回了,至于什么时候发送,怎么发送,我不关心
- 只有操作系统的TCP 协议可以知道网络及对方的状态信息,所以也就只有TCP协议,知道如何发,什么时候发,发多少,出错了怎么办?(传输控fa制协议)发送的细节应用层就不用管了
- 缓冲区的存在可以做到应用层和TCP进行解耦,各自做好各自的事即可
在第一次发送SYN 的时候{SYN,1000-》(标号)(0-》数据的大小) <mass 1460 (传输文件的大小上限)>}
- 确认号+1 是因为在原来的序列号还要加上SYN这个标志位的大小
- 三次握手完成在代码层面上的体现就是:accept()和connect()成功执行返回,所以accept()执行发出错误信号出来,或者connect都是没有建立成功
- 普通报文不携带数据,不消耗序列号,所以后面再在传输的时候不会加上标志位,该多大就多大
- 假如说客户端先发起关闭,第一次挥手断开连接(半关闭,有一端关了,另一端没有关闭第一次挥手),客户端如果还有数据就不能再发送了,相当于socket内部的写缓冲区关闭了,但是读缓冲区还留着
- 后面服务器也要发起关闭,也要有两次挥手(半关闭是导致4次挥手的原因)
- 半关闭并非是关套接字,而是关里面的写缓冲区,读缓冲区还没有关闭,
- 数据会被分成段,如果一个段在到达时是存在错误的,这个段就会被丢弃,确认信息也不会发送,发送者在发送每一个段的时候,都会开启一个定时器,如果定时器超时之前没有收到确认,就会重传这个段,