GEO
主要用于存储地理位置,并对存储的信息进行操作
- 添加地理位置坐标
- 获取地理位置的坐标
- 计算两个位置之间的距离
- 更具给定的经纬度坐标来获取指定范围内的地理位置的集合
- 最直观的就是滴滴打车,实时记录更新每个车的位置
如果我们这里使用的是一个sql的话
- 查询性能,如果并发很高,数据量很大的这种查询是要搞垮数据库的
- 这个查询是一个矩形访问,而不是以我为中心,r为半径的一个圆形访问
- 精准度问题,地球是一个圆的,在矩形计算的时候会出现很大的误差
操作
- GEOADD 添加经纬度,第一个是经度,第二个是纬度
127.0.0.1:6379> GEOADD city 116.388226 39.937714 "天安门"
(integer) 1
因为这个是一个city类型,所以可能会出现中文乱码,我们在登陆的时候需要添加一个–raw
redis-cli --raw
zrange city 0 -1
- GEOPOS
查看经纬度坐标
127.0.0.1:6379> GEOPOS city "天安门"
1) 1) "116.38822406530380249"
2) "39.9377142078007239"
- geohash
生成对应地点的hash值
127.0.0.1:6379> GEOHASH city "天安门"
1) "wx4g0qrq410"
- geodist
查看两个坐标之间的距离
HyperLogLog
只计算有多少个基数,不存储数据
UV(不重复的数据)基数统计(统计今天有多少人访问天猫的首页)
在输入元素的数量或者体积非常大的时候,计算基数所需要的空间总是很大的
- 统计该网站总计被多少个不同人访问(例如一个人登陆一个网站10次,那么基数还是1)
- 需要进行一个去重考虑(去重脱水后的真实数据)
- 只会进行基数统计
{2,4,6,8,77,4,2}
去重脱水后的真实数据={2,4 ,8,77,6}=5
操作
- pfadd 和pfcount
127.0.0.1:6379> PFADD hll1 1 3 4 2 1 3 4
(integer) 1
127.0.0.1:6379> PFCOUNT hll1
(integer) 4
- pfmerge
把两个进行一个整合
127.0.0.1:6379> PFADD hll2 12 3 2 2 1 4 3 4 2 1 3 4
(integer) 1
127.0.0.1:6379> PFMERGE result hll1 hll2
OK
//统计整合之后的数据
127.0.0.1:6379> PFCOUNT result
(integer) 5
BitMap
位图,最多可以存储2^32位,它可以极大的节约存储空间
0和1状态表现的二进制位的数组
例如:
- 每日签到,今天来了打了1,没来打了0,只需要记录01数组
- 用户是否登陆过
- 电影是否被播放过
操作
偏移量是从比特位从0开始
- setbit
//本质上还是一个string
127.0.0.1:6379> setbit k1 2 1
(integer) 0
127.0.0.1:6379> setbit k1 3 1
(integer) 0
- getbit
查看某一个bit位是否有值
127.0.0.1:6379> getbit k1 1
(integer) 1
127.0.0.1:6379> getbit k1 2
(integer) 1
127.0.0.1:6379> getbit k1 3
(integer) 1
127.0.0.1:6379> getbit k1 4
(integer) 0
127.0.0.1:6379> getbit k1 5
(integer) 0
- strlen
统计该位图占用了几个字节
//查看k1占用了1个字节
127.0.0.1:6379> STRLEN k1
(integer) 1
127.0.0.1:6379> setbit k1 256 1
(integer) 0
127.0.0.1:6379> STRLEN k1
(integer) 33
- bitcount
统计有多少个比特位被设置了
127.0.0.1:6379> BITCOUNT k1
(integer) 5
- bitop
比特位的运算
and or xor
例子:连续两天都出现的用户(某一个bit位为某一个用户)
把两个位图进行and一下,看他的值是多少
//这个1代表的是操作成功
127.0.0.1:6379> BITOP and k1 20230101 20230102
(integer) 1
//因为他这个结果都在k1这个表里面
127.0.0.1:6379> BITCOUNT k1
(integer) 1
bitfield
一次性的操作多个比特位域(指的是连续的多个比特位),由二进制的数组
(用的少),对位域中任何位置进行一个修改,更快
将一个很小的整数存储到
每一个英文单词都可以对照有ascill码,再将其转化成为01序列,每8位一组
- 位域修改(把某一个bit位直接进行修改,这样更快)
u8就是8位的无符号数
i8就是8位的有符号数
fk1=“hello”
//这里就是以有符号的方式读取8位(8位为一组)的第0位
127.0.0.1:6379> BITFIELD fk1 get i8 0
1) (integer) 104//这个读取出来就是o的ascill值
对位域进行设置
127.0.0.1:6379> BITFIELD fk1 set i8 #0 120//这里我们把第0个字节的偏移量设置成了220
1) (integer) 101
位域增加
127.0.0.1:6379> BITFIELD fk1 incrby u4 2 1
1) (integer) 15
127.0.0.1:6379> BITFIELD fk1 incrby u4 2 1
1) (integer) 0
//发生了一个循环溢出
这里我们把把偏移量为#59 设置成为23,设置#719为25
127.0.0.1:6379> BITFIELD -ts set u8 #59 23 set u8 #719 25
1) (integer) 0
2) (integer) 0
Stream
主要用于消息队列(MQ message queue),redis有一个发布订阅功能实现消息队列,但是无法持久化
redis发布订阅缺点:消息无法实现持久化,如果出现网络断开,Redis宕机,消息就会被丢弃,也没有ack机制来保证消息的可靠性,加入消费者都没有了,消息就直接丢弃
redis使用的消息队列
- 使用lpush进来,使用rpop出去,就实现了一进一出,使用异步队列来处理,但是只能进行点对点(这个只能实现单生产者,单消费者模型)
- 对于稍微复杂的单生产者多消费者模型使用订阅发布
Stream:也是为了实现消息中间件=消息中间件+阻塞队列
能干嘛
实现了消息队列,支持消息的持久化,支持自动生成全局唯一的ID,支持ack确认消息的模式,支持消费组模式,让消息队列更加稳定和可靠
底层结构
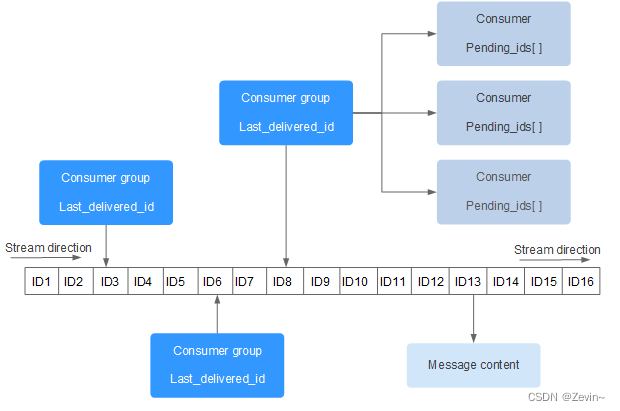
操作
生产者
- 往队列里面添加数据
xadd :添加消息到队列的末尾(生产者)
- 消息ID要比上一个ID大
- 默认使用* 表示自动生成(让系统自动增加==auto increment)
- 返回消息ID
127.0.0.1:6379> xadd mystream * id 11 cname z3//* 表示让系统自动生成,id 11表示我们让消息的id为11 cname就是里面的field,z3就是value
"1678765458848-0"//生成的消息ID,-前面就是这个一个毫秒级的时间戳,-后面就是该毫秒下的第几条消息
127.0.0.1:6379> xadd mystream * id 12 cname z311
"1678765472917-0"
127.0.0.1:6379> xadd mystream * id 13 cname z311
"1678765475346-0"
127.0.0.1:6379> xadd mystream * k1 v1 k2 v2
"1678765503067-0"
- xrange
- 用于获取消息列表,忽略删除的消息
- -表示最小,+表示最大
- count表示最多获取多少个值
127.0.0.1:6379> XRANGE mystream - + //从小到打进行遍历
1) 1) "1678765458848-0"
2) 1) "id"
2) "11"
3) "cname"
4) "z3"
2) 1) "1678765472917-0"
2) 1) "id"
2) "12"
3) "cname"
4) "z311"
3) 1) "1678765475346-0"
2) 1) "id"
2) "13"
3) "cname"
4) "z311"
4) 1) "1678765503067-0"
2) 1) "k1"
2) "v1"
3) "k2"
4) "v2"
127.0.0.1:6379> XRANGE mystream - + count 1//只显示一条
1) 1) "1678765458848-0"
2) 1) "id"
2) "11"
3) "cname"
4) "z3"
127.0.0.1:6379> XRANGE mystream - + count 1//反过来进行输出
1) 1) "1678765458848-0"
2) 1) "id"
2) "11"
3) "cname"
4) "z3"
- xlen
计算消息队列中的长度
127.0.0.1:6379> xlen mystream
(integer) 4
- xtrim
对流进行截取
127.0.0.1:6379> xtrim mystream maxlen 2//只保留消息队列里面id最大的两个元素
(integer) 3
127.0.0.1:6379> XRANGE mystream - +
1) 1) "1678765503067-0"
2) 1) "k1"
2) "v1"
3) "k2"
4) "v2"
2) 1) "1678766883798-0"
2) 1) "kk"
2) "vv"
//minid就是把比该id还要小的数据全部都抛弃
127.0.0.1:6379> xtrim mystream minid 1678766883798-0
(integer) 1
127.0.0.1:6379> XRANGE mystream - +
1) 1) "1678766883798-0"
2) 1) "kk"
2) "vv"
- xread(消费者),默认都是非阻塞的
用于获取消息,只会返回大于某个id的消息
- $代表特殊ID,表示当前stream已经存储的最大ID的作为最后一个id,当前stream中不存在大于当前最大ID 的消息,因此返回nil
- 0-0 代表从最小的ID开始获取stream中的消息,当不指定count时,会返回stream中的所有消息,
//指定读取两条,
127.0.0.1:6379> xread count 2 streams mystream 0-0
1) 1) "mystream"
2) 1) 1) "1678766883798-0"
2) 1) "kk"
2) "vv"
2) 1) "1678767340388-0"
2) 1) "a1"
2) "v1"
3) "a2"
4) "v2"
5) "a4"
6) "v4"
127.0.0.1:6379> xread count 13 streams mystream 0-0//非阻塞读取,不需要在那边阻塞等待消息
1) 1) "mystream"
2) 1) 1) "1678766883798-0"
2) 1) "kk"
2) "vv"
2) 1) "1678767340388-0"
2) 1) "a1"
2) "v1"
3) "a2"
4) "v2"
5) "a4"
6) "v4"
3) 1) "1678767394538-0"
2) 1) "aa"
2) "aa"
//使用阻塞方式来调用,同时会输出等待了多少的时间
127.0.0.1:6379> xread count 1 block 0 streams mystream $
1) 1) "mystream"
2) 1) 1) "1678769042246-0"
2) 1) "zzz"
2) "aa"
(248.37s)
消费者
- xgroup
创建一个消费者组
//给mystream创建了一个消费组gx,从尾巴开始读取
127.0.0.1:6379> XGROUP CREATE mystream gx $
OK
//创建了一个ga进行从头开始读取
127.0.0.1:6379> XGROUP CREATE mystream ga 0
OK
- xreadgroup group
//同一个组里面的数据,被一个消费者读取之后,其他消费者就不能进行读取了
127.0.0.1:6379> XREADGROUP group ga consumer1 streams mystream >
1) 1) "mystream"
2) 1) 1) "1678766883798-0"
2) 1) "kk"
2) "vv"
2) 1) "1678767340388-0"
2) 1) "a1"
2) "v1"
3) "a2"
4) "v2"
5) "a4"
6) "v4"
3) 1) "1678767394538-0"
2) 1) "aa"
2) "aa"
4) 1) "1678769042246-0"
2) 1) "zzz"
2) "aa"
127.0.0.1:6379> XREADGROUP group ga consumer2 streams mystream >
(nil)
//但是其他组的消费者还能够继续读取
消费者,我们让每个消费者负载均衡式的进行读取,每个人读取一点count 1(使用count进行对每个消费者读取条数进行分配)