文章目录
Redis集群是什么以及它的优势
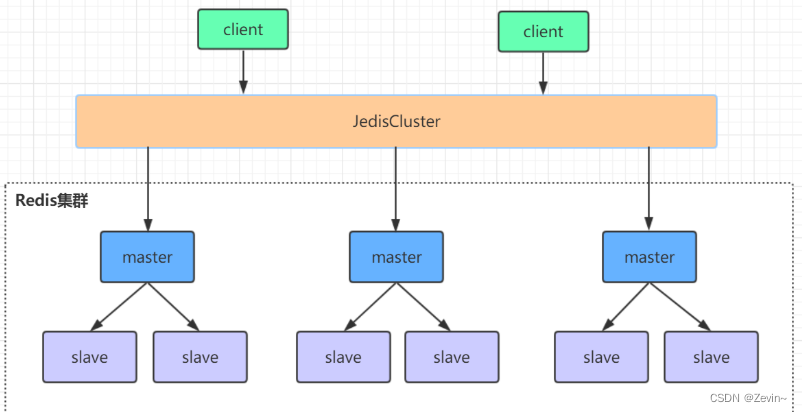
redis集群是有多个节点构成,每个节点都是一个redis实例,通过数据路由和主从节点实现数据的负载均衡,和高可用
Redis集群可以支持多个master
如果客户端写了一个数据给其中一个
master,
- 那么他的的
slave同步都有这些数据,后台进行异步完成,在几毫秒或者几微秒之内,主节点不需要等待从节点响应就能继续处理其他操作,从节点的数据同步时间取决于(从节点的配置,负载,网络延迟等)- 其他
master并不会同步该数据,master之间并不是数据共享,他会向负责该数据分片的主机发起请求访问,并且从该主节点的从节点中获得最新的数据如果其中一个master挂了,那么其他master还能够继续工作,不受影响
- 在redis集群中,每个节点都可以充当
哨兵的功能,监控其他节点的状态,执行故障转移的功能- 在redis集群中,每个节点都会
周期性的给其他节点发送ping命令,检测节点的状态,- 当某个节点被多个节点标记为
主观下线后,该节点就会被标记为客观下线,- 之后,该主节点的其中一个从节点检测到主节点挂机值后,就会向其他主节点发送一个信号,同时寻求主节点的支持竞选为新的主节点,执行主从切换
能干嘛
- redis集群支持多个master,每个master可以挂载多个slave节点
读写分离(master和slave分别执行不同的任务),slave节点主要是用来实现数据的备份,以及扩展redis集群的读取能力,可以将读请求分发到不同的slave上支持数据的高可用(一个master挂掉了,其他master/slave还可以顶上)支持海量数据的读写存储操作
- cluster自带哨兵的故障转移功能,内置了高可用的支持,无需再去额外添加哨兵节点
- 客户端和redis的节点连接,不需要再连接集群中的所有节点,只需要任意连接集群中的一个可用节点即可(master所有主节点间可以支持
数据路由) - 槽位slot负责分配到各个物理服务器节点,由对应的集群来负责维护节点,插槽和数据之间的关系
- 数据发送到对应的主节点,主节点会从
本地内存或从节点中读取数据,并得到结果返回给客户端
Redis集群中的数据分片和哈希槽
槽位
slot最多是16384(最好不超过1000个,会导致信息失真,在网络上的耗时也越长)
redis集群没有使用一致性hash,而是引入了哈希槽的概念
redis集群中一共有16384个槽位,每个key通过CRC16检验之后对16383取模来决定放置再哪个槽位,集群的每个节点负责一部分的hash槽,例如下面集群中由3个master节点
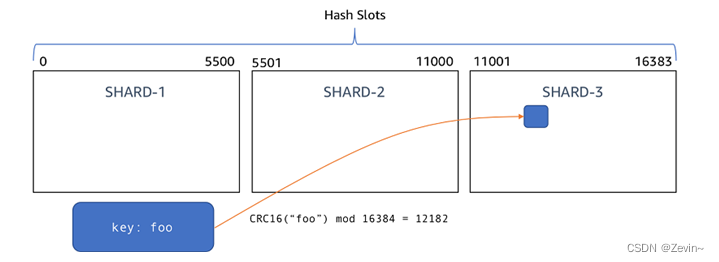
对key=foo进行CRC16计算出对应的值后%16383,得到12182,在第三个redis节点管理的位置,所以这个key就由第三个master来管理
分片
使用redis集群时,我们会将存储的数据分散到多个redis机器上,这就叫做分片
简言之,集群中的每个redis实例都是整个数据集的一个分片,因为一个redis机器对应的槽位足够大,所以对于机器增加或减少的影响较小,还是有大概率映射到之前对应的机器上
如何找到给定key的分片
为了找到给定key的分片,我们对key进行
CRC16(key)算法处理(这个算法是有服务端来执行的),并对总分片数量取模,然后使用确定性的hash函数,着意味着给定的key将多次始终映射到同一个分片,我们可以推断将来读取特定key的位置
- 当客户端向集群中的某个节点写入数据的时候,该节点会更根据CRC16算法计算特定的槽位值,如果该槽位在该节点的负载范围内,就执行相应的写入操作
- 如果不在该节点的范围内,就将
数据路由给负责的节点进行处理,并等待该节点写入完成- 数据写入过程中客户端都是异步执行的,不会影响客户端的性能
redis 分片和槽位的优势
最大的优势可以进行扩容和缩容,不会造成集群不可用的状态
slot槽位映射
哈希取余分区
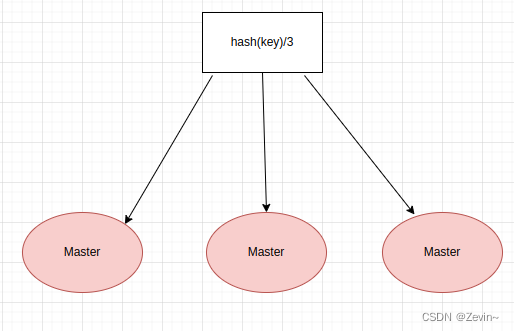
这里有3台机器,所以就直接使用使用hash函数后对3取余得到最后的结果即可
优点
简单粗暴,直接有效,只需要预估好节点,例如3台,8台,10态,就能保证一段时间的数据支撑,起到负载均衡+分而治之的作用
缺点
原来规划好的节点在扩容和缩容就比较麻烦了,映射关系就会发生变化,就需要进行重新计算,
取模公式就会发生变化:hash(key)/3->hash(key)/?
此时如果某个redis机器宕机了,由于台数变化,hash取余需要重新洗牌,新增加的节点没有哪些数据,就会发生缓存雪崩
总结:这种方法简单,但是会导致机器容易变动
一致性hash算法分区
Redis集群中的slot槽位映射和优劣
是什么
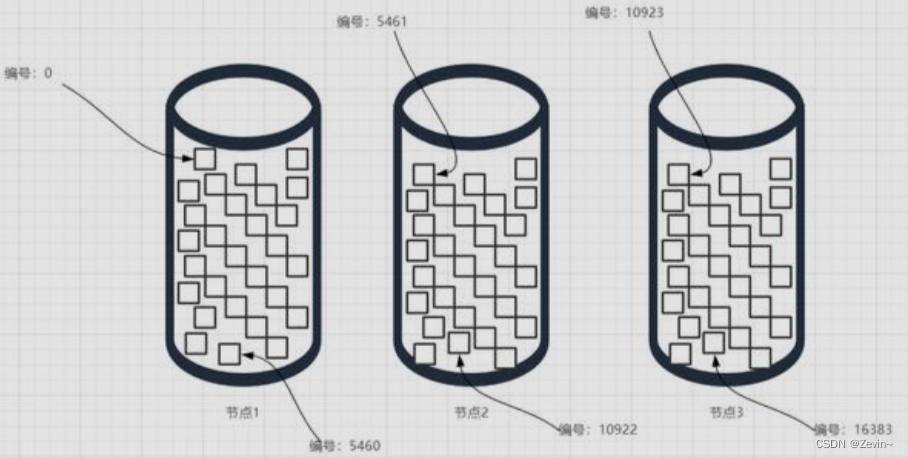
哈希槽实际上就是一个数组,数组[0,2^14-1]形成hash slot空间
能干什么
解决的实际上就是均匀分配的问题,在数据和节点之间增加了一层哈希槽,用于管理管理数据和节点之间的关系,现在相当于节点上放的是槽,槽上放的是数据
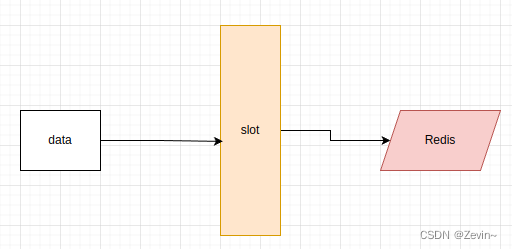
槽解决的是粒度问题,相当于把粒度变大了,这样便于数据的移动,哈希解决的是映射问题,使用key的哈希值来计算所在的槽位,便于数据的分配
多少个槽位
一个集群只能有16384个槽,编号为0-16383(0-2^14-1),这些槽会分配给集群中的所有主节点,分配策略没有要求
集群会记录节点和槽的对应关系,解决了节点和槽的关系值后,接下来就需要对key球hash值,然后对16384取模,余数是几,key就落入对应的槽中,HASH——SLOT=CRC16(key)mode16384,以槽为单位移动数据,因为槽是固定的,处理起来比较容易,数据移动问题就解决了
为什么实际16384
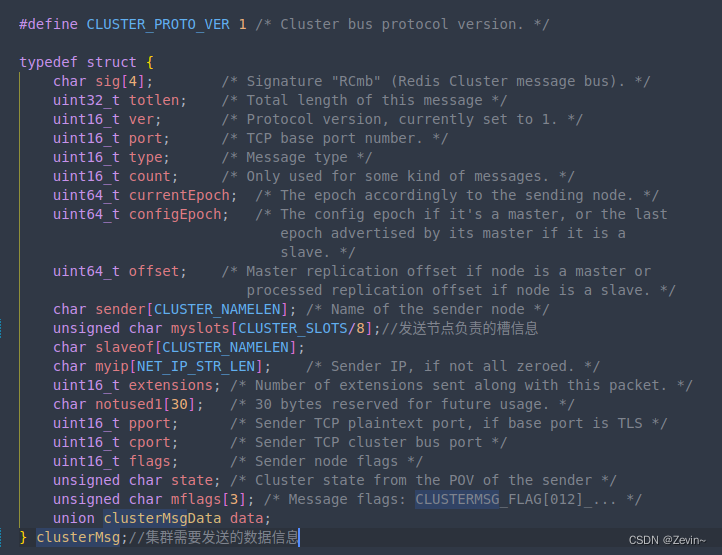
- 为什么槽位是65536,发送心跳包的信息头达8k,发送的心跳包过于庞大
- 在消息头中最占空间的myslot[cluster_slot/8],当槽位为65536时,这块的大小是:65536/8/1024=8kb,光是和slot相关的数据,就很大了,更不用说除此之外的整个心跳包
- 当槽位是16384时,这块的大小是:16384/8/1024=2kb
- 因为每一秒,redis需要发送一定数量的
ping消息作为心跳包,如果槽位是65536,这个ping的消息头就太大了,浪费带宽
- 为什么这里[CLUSTER_SLOT/8],这里要除以8
因为每个槽位只占据一个bit
- redis的集群主节点数量基本不可能超过1000个
集群节点越多,心跳包的消息体内携带的数据越多,如果超过了1000个节点,会网络拥堵,因此不建议超过1000个节点,而对于1000个节点以内的redis集群,16384个槽位置绝对够用了,没必要超过65536
- 槽位越小,节点越少的情况下,压缩比高,任意传输
redis主节点配置信息中他所负责的
哈希槽是通过一张bitmap来保存的,在传输过程中,会对bitmap进行压缩,的是如果bitmap的填充率(slot/N(N个节点))很高的话,bitmap的压缩率就很低,而节点很少,哈希槽数量很多的话,bitmap压缩率就很低(推荐)
Redis不保证强一致性
Redis编辑群不保证强一致性,这意味着在特定条件下,redis集群会丢失一些被系统收到的写入请求
redis在节点之间是使用异步的一个复制,而不是马上收到,马上就复制了