项目背景

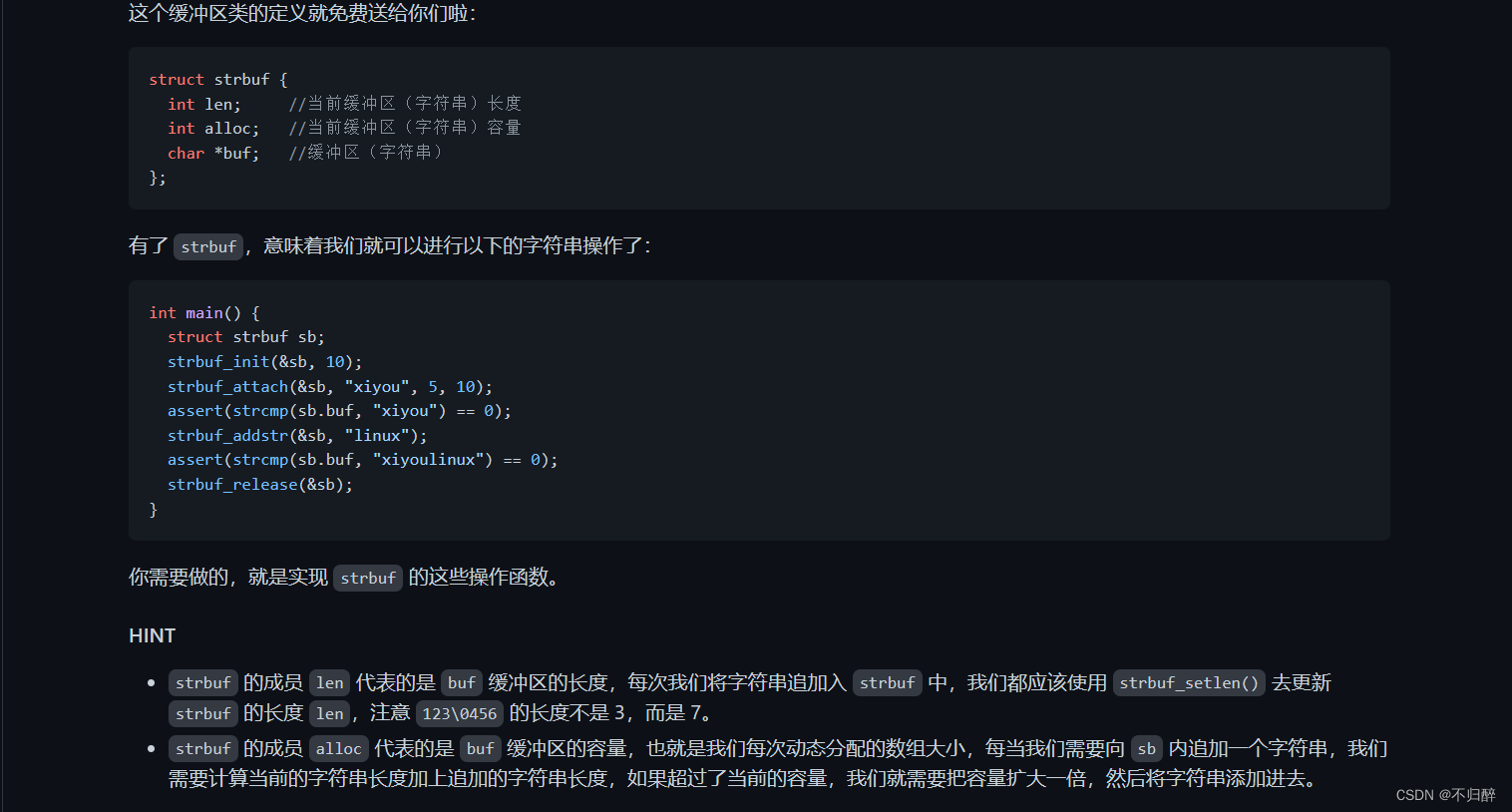
项目要求
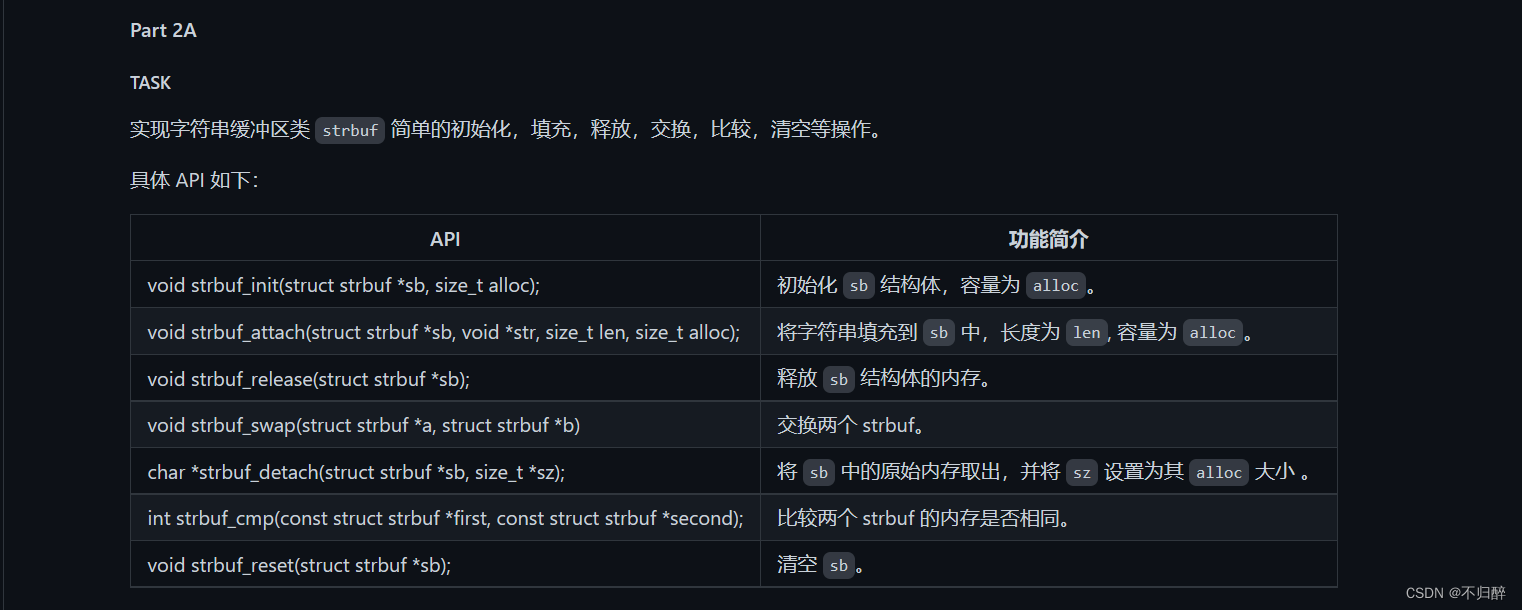

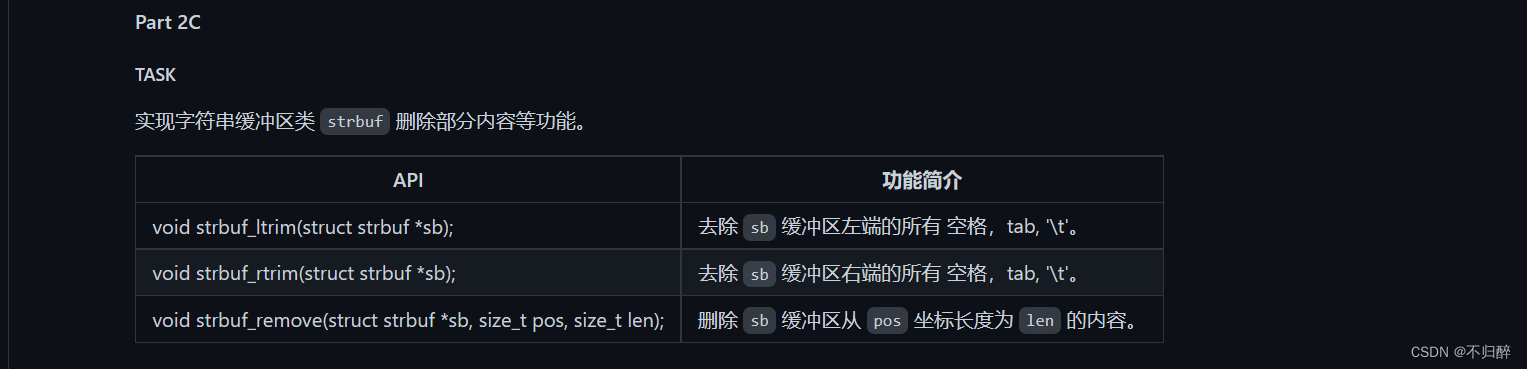
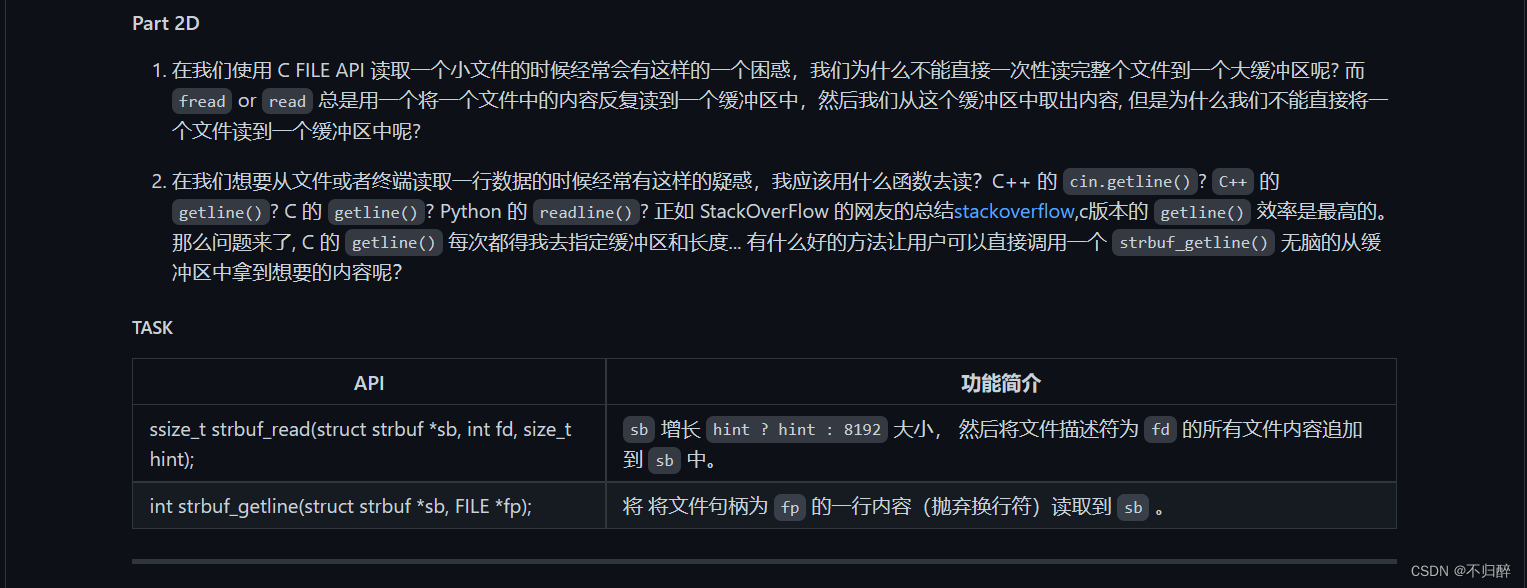
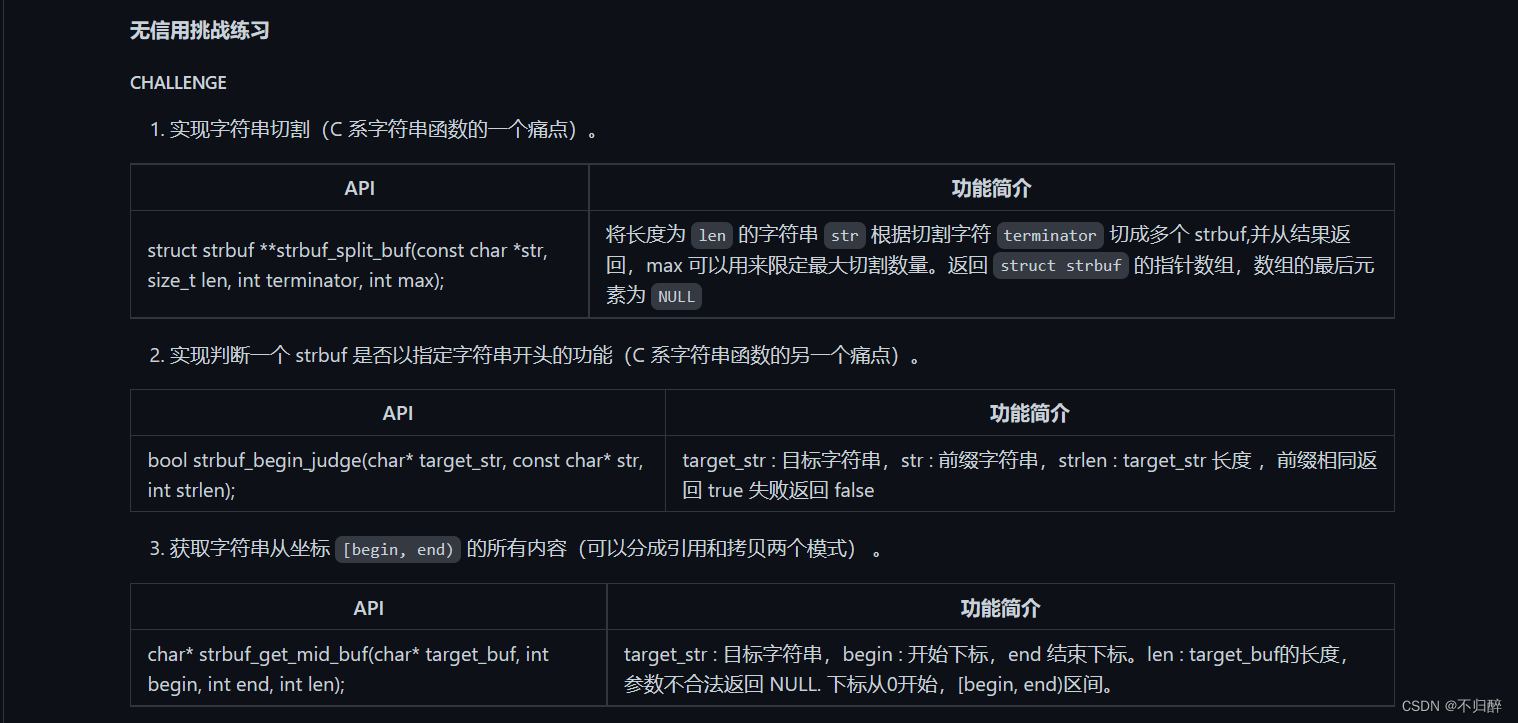
代码实现
代码注释中有详细笔记
#include "strbuf.h" /*struct strbuf { int len; // 当前缓冲区(字符串)长度 int alloc; // 当前缓冲区(字符串)容量 char *buf; // 缓冲区(字符串) } ;*/ //PLAN_A // 初始化 sb 结构体,容量为 alloc void strbuf_init(struct strbuf *sb, size_t alloc) { sb->len = 0; sb->alloc = alloc; sb->buf = (char *)malloc(sizeof(char) * alloc); strcpy(sb->buf, ""); } // 将字符串填充到 sb 中,长度为 len, 容量为 alloc。 void strbuf_attach(struct strbuf *sb, void *str, size_t len, size_t alloc) { sb->len = len; sb->alloc = alloc; sb->buf = (char*)str; } // 释放 sb 结构体的内存。 void strbuf_release(struct strbuf *sb) { free(sb->buf); } // 交换两个 strbuf。 void strbuf_swap(struct strbuf *a, struct strbuf *b) { // 引入中间变量c struct strbuf c; /*c.len=a->len; c.alloc=a->alloc; c.buf=a->buf; a->len=b->len; a->alloc=b->alloc; a->buf=b->buf; b->len=c.len; b->alloc=c.alloc; b->buf=c.buf;*/ c=*a; *a=*b; *b=c; } // 将 sb 中的原始内存取出,并将 sz 设置为其 alloc 大小 。 char *strbuf_detach(struct strbuf *sb, size_t *sz) { *sz = sb->alloc; return sb->buf; } // 比较两个 strbuf 的内存是否相同。 int strbuf_cmp(const struct strbuf *first, const struct strbuf *second) { /*比较内存是否相同,其实是比较内存块中相同字节数下所指代的内容是否相同 这边使用<string.h>中的memcmp函数*/ /*C 库函数 int memcmp(const void *str1, const void *str2, size_t n)) 把存储区 str1 和存储区 str2 的前 n 个字节进行比较。 下面是 memcmp() 函数的声明。 int memcmp(const void *str1, const void *str2, size_t n) 返回值 如果返回值 < 0,则表示 str1 小于 str2。 如果返回值 > 0,则表示 str1 大于 str2。 如果返回值 = 0,则表示 str1 等于 str2*/ if (first->len==second->len) { return memcmp(first->buf,second->buf,first->len); } else { return 1; } /*返回0,证明相同 返回1,证明不相同*/ } // 清空sb。 void strbuf_reset(struct strbuf *sb) { for(int a = 0; a<sb->len;a++) sb->buf[a]='\0'; sb->len=0; } //PLAN_B //确保在 len 之后 strbuf 中至少有 extra 个字节的空闲空间可用。 void strbuf_grow(struct strbuf *sb, size_t extra) { //内存要扩大 sb->buf=(char*)realloc(sb->buf,sb->alloc+extra); //内存扩大,那必然容量扩大 sb->alloc+=(int)extra; } //向 sb 追加长度为 len 的数据 data。 void strbuf_add(struct strbuf *sb, const void *data, size_t len) { if(len==0) { //长度是0,不就是没有嘛,那追加个锤子 return; } //判断是否需要扩容 if(sb->len+len>=sb->alloc) { sb->alloc=sb->len+len+1; sb->buf=(char*)realloc(sb->buf,sb->len+len+1); } //批量复制?memcpy!你值的拥有 memcpy(sb->buf+sb->len,data,len); sb->len+=len; sb->buf[sb->len]='\0'; } //向 sb 追加一个字符 c。 void strbuf_addch(struct strbuf *sb, int c) { //追加的是 字符c和'\0'哦,所以是+2喽 if(sb->len+2>=sb->alloc) { sb->alloc=sb->alloc*2; sb->buf=(char*)realloc(sb->buf,(sb->alloc)*(sizeof(char))*2); } //追加字符?<string,h>下的memcpy函数,你值得拥有哦 /*C 库函数 void *memcpy(void *str1, const void *str2, size_t n) 从存储区 str2 复制 n 个字节到存储区 str1。 下面是 memcpy() 函数的声明。 void *memcpy(void *str1, const void *str2, size_t n) 返回值 该函数返回一个指向目标存储区 str1 的指针。*/ memcpy(sb->buf+sb->len,&c,2); sb->len++; } //向 sb 追加一个字符串 s。 void strbuf_addstr(struct strbuf *sb, const char *s) { strbuf_add(sb,s,strlen(s)); } //向一个 sb 追加另一个 strbuf的数据。 void strbuf_addbuf(struct strbuf *sb, const struct strbuf *sb2) { strbuf_addstr(sb,sb2->buf); } //设置 sb 的长度 len。 void strbuf_setlen(struct strbuf *sb, size_t len) { sb->len=len; sb->buf[sb->len]='\0'; } //计算 sb 目前仍可以向后追加的字符串长度。 size_t strbuf_avail(const struct strbuf *sb) { //容量是0,那不就是没有嘛 if (sb->alloc==0) { return 0; } //容量-长度-'\0' int ans=sb->alloc-sb->len-1; return ans; } //向 sb 内存坐标为 pos 位置插入长度为 len 的数据 data。 void strbuf_insert(struct strbuf *sb, size_t pos, const void *data, size_t len) { //pos位置之后还有多长 int len_temp=sb->len+len; if(len_temp>sb->alloc) { strbuf_grow(sb,len); } //pos位置前,不改变->分段改变 //剩余部分 for (int i=sb->len;i>=pos;i--) { sb->buf[i+len]=sb->buf[i]; } // 插入部分 for (int i=0,j=pos;i<len;i++,j++) { sb->buf[j]=((char*)data)[i]; } sb->len=len_temp; } //PLAN_C //去除 sb 缓冲区左端的所有 空格,tab, '\t'。 void strbuf_ltrim(struct strbuf *sb) { char *temp=sb->buf; while(*temp==' '||*temp=='\t') { temp++; sb->len--; } memmove(sb->buf,temp,sb->len); } //去除 sb 缓冲区右端的所有 空格,tab, '\t'。 void strbuf_rtrim(struct strbuf *sb) { while (sb->buf[sb->len-1]==' '||sb->buf[sb->len-1]=='\t') { sb->buf[sb->len-1]='\0'; if(sb->len<=0) { break; } sb->len--; } } //删除 sb 缓冲区从 pos 坐标长度为 len 的内容。 void strbuf_remove(struct strbuf *sb, size_t pos, size_t len) { /*删去?拿一些随机值覆盖掉就好了 这边使用的是<string.h>中的memmove函数 C 库函数 void *memmove(void *str1, const void *str2, size_t n) 从 str2 复制 n 个字符到 str1, 但是在重叠内存块这方面,memmove() 是比 memcpy() 更安全的方法。 如果目标区域和源区域有重叠的话,memmove() 能够保证源串在被覆盖之前将重叠区域的字节拷贝到目标区域中, 复制后源区域的内容会被更改。如果目标区域与源区域没有重叠,则和 memcpy() 函数功能相同。 返回值 该函数返回一个指向目标存储区 str1 的指针。*/ memmove(sb->buf+pos,sb->buf+pos+len,sb->len-pos-len); //既然都删除了,那长度一定会变的 sb->len-=len; } //PLAN_D //sb 增长 hint ? hint : 8192 大小, 然后将文件描述符为 fd 的所有文件内容追加到 sb 中。 // |_fdopen()? // |_ FILE *fdopen(int fd, const char *mode); ssize_t strbuf_read(struct strbuf *sb, int fd, size_t hint) { FILE *file=fdopen(fd,"r"); char end_flag; if((end_flag=fgetc(file))==EOF) { return sb->len; } else { sb->alloc+=8192; sb->buf=(char*)realloc(sb->buf,sizeof(char)*(sb->alloc)); sb->buf[sb->len++]=end_flag; while((end_flag=fgetc(file))!=EOF) { sb->buf[sb->len]=end_flag; sb->len++; } sb->buf[sb->len]='\0'; return sb->len; } } //将 将文件句柄为 fp 的一行内容(抛弃换行符)读取到 sb 。 int strbuf_getline(struct strbuf *sb, FILE *fp) { //单字符读取,while循环 int temp; int length_new=0; while(1) { if((temp=fgetc(fp))=='\n'||temp==EOF) { //读到换行和EOF退出 break; } //判断是否需要扩容 if(sb->alloc-sb->len>=2)//不需要 { strbuf_addch(sb,temp); length_new++; } else//需要 { sb->buf=(char*)realloc(sb->buf,sizeof(char)*(sb->alloc+1)); strbuf_addch(sb,temp); length_new++; } } sb->len=length_new; return 1; } //无信用挑战 //1.实现字符串切割(C 系字符串函数的一个痛点) //将长度为 len 的字符串 str 根据切割字符 terminator 切成多个 strbuf,并从结果返回, //max 可以用来限定最大切割数量。返回 struct strbuf 的指针数组,数组的最后元素为 NULL struct strbuf **strbuf_split_buf(const char *str, size_t len, int terminator, int max) { //分配内存 struct strbuf **buflist=(struct strbuf**)malloc(sizeof(struct strbuf*)*(max+1)); //保存被切割字符串的首地址的末尾地址 const char *start = str; const char *end=str+len; //数量 int num=0; const char *temp; int length; //首元素就是被切割字符,那切个锤子,直接跳过 while(*start==terminator) { start++; } //从第一个非切割字符开始,遍历至最后 for (temp=start;temp<=end;temp++) { //定位切割字符 if (*temp==terminator||temp==end) { length=temp-start; //确定长度,容量,分配内存 buflist[num]=(struct strbuf*)malloc(sizeof(struct strbuf)); buflist[num]->len=length; buflist[num]->alloc=length+1; buflist[num]->buf=(char*)malloc(sizeof(char)*(length+1)); //复制内容和结束符号\0 memcpy(buflist[num]->buf,start,length); *(buflist[num]->buf+length)='\0'; num++; //遍历头的移动 while(*temp==terminator&&temp<=end) temp++; //确定新的遍历头 start=temp; } //max个非NULL字符串 if(num==max) break; } buflist[num]=NULL; return buflist; } //2.实现判断一个 strbuf 是否以指定字符串开头的功能(C 系字符串函数的另一个痛点) //target_str : 目标字符串,str : 前缀字符串,strnlen : target_str 长度 , //前缀相同返回 true 失败返回 false bool strbuf_begin_judge(char* target_str, const char* str, int strnlen) { if(strnlen == 0) return true; if(strlen(str) > strnlen) return false; if(memcmp(target_str,str,strlen(str)) == 0) return true; else return false; } //3.获取字符串从坐标 [begin, end) 的所有内容(可以分成引用和拷贝两个模式)。 //target_str : 目标字符串,begin : 开始下标,end 结束下标。len : target_buf的长度, //参数不合法返回 NULL. 下标从0开始,[begin, end)区间。 char* strbuf_get_mid_buf(char* target_buf, int begin, int end, int len) { if(target_buf==NULL||begin>len) { return NULL; } int temp=0; char *ans_str=(char*)malloc(sizeof(char)*(end-begin+2)); for(int i=begin;i<=end;i++) { ans_str[temp++]=target_buf[i]; } ans_str[end-begin]='\0'; return ans_str; }