Lab7 Multithreading
Uthread: switching between threads (moderate)
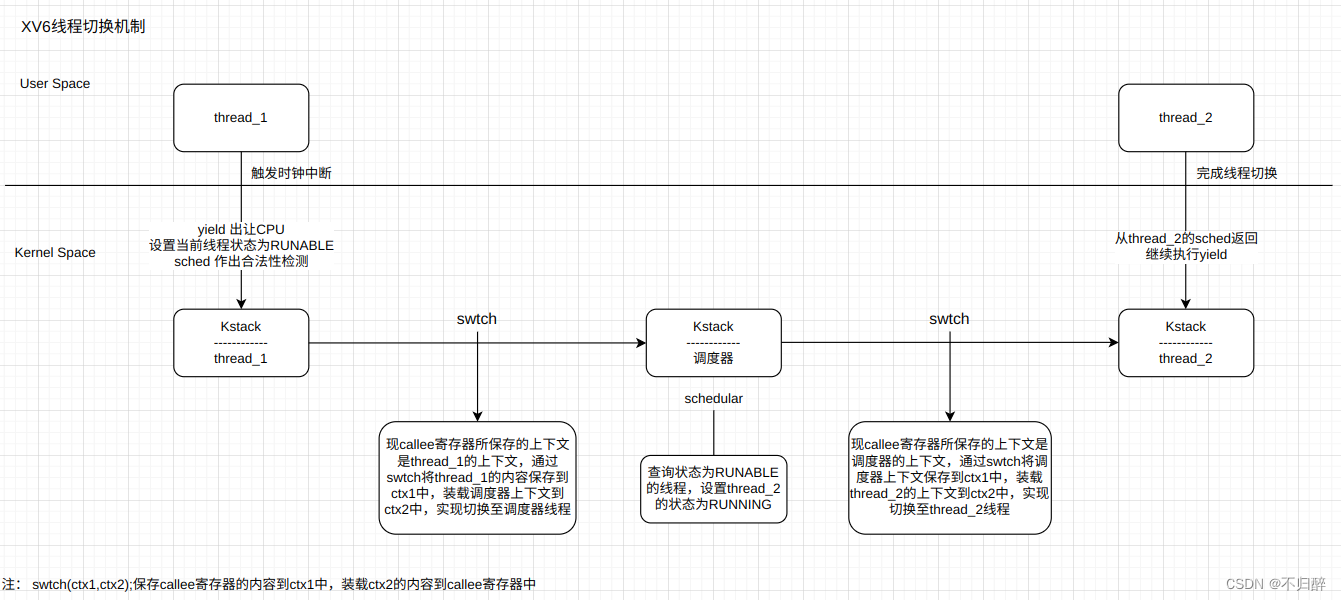
上图就是在XV6中线程的切换机制。
引申:内核调度器无论是通过时钟中断进入(usertrap),还是线程自己主动放弃 CPU(sleep、exit),最终都会调用到 yield 进一步调用 swtch。 由于上下文切换永远都发生在函数调用的边界(swtch 调用的边界),恢复执行相当于是 swtch 的返回过程,会从堆栈中恢复 caller-saved 的寄存器, 所以用于保存上下文的 context 结构体只需保存 callee-saved 寄存器,以及 返回地址 ra、栈指针 sp 即可。恢复后执行到哪里是通过 ra 寄存器来决定的(swtch 末尾的 ret 转跳到 ra)
而 trapframe 则不同,一个中断可能在任何地方发生,不仅仅是函数调用边界,也有可能在函数执行中途,所以恢复的时候需要靠 pc 寄存器来定位。 并且由于切换位置不一定是函数调用边界,所以几乎所有的寄存器都要保存(无论 caller-saved 还是 callee-saved),才能保证正确的恢复执行。 这也是内核代码中
struct trapframe中保存的寄存器比struct context多得多的原因。另外一个,无论是程序主动 sleep,还是时钟中断,都是通过 trampoline 跳转到内核态 usertrap(保存 trapframe),然后再到达 swtch 保存上下文的。 恢复上下文都是恢复到 swtch 返回前(依然是内核态),然后返回跳转回 usertrap,再继续运行直到 usertrapret 跳转到 trampoline 读取 trapframe,并返回用户态。 也就是上下文恢复并不是直接恢复到用户态,而是恢复到内核态 swtch 刚执行完的状态。负责恢复用户态执行流的其实是 trampoline 以及 trapframe。
本实验就是相当于在用户态重新实现一遍XV6内核中的schedule和swtch的功能,所以说对照内核中的线程调度机制很有必要,这里的线程感觉更像协程,原因是这里的线程是完全用户态实现的,多个线程也只能运行在一个 CPU 上,并且没有时钟中断来强制执行调度,需要线程函数本身在合适的时候主动 yield 释放 CPU。这样实现起来的线程并不对线程函数透明,所以比起传统意义上的多线程调度更接近与协程。
// 用于保存上下文的寄存器
struct context
{
uint64 ra;
uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
struct thread
{
char stack[STACK_SIZE]; /* the thread's stack */
int state; /* FREE, RUNNING, RUNNABLE */
struct context context;
};
void thread_schedule(void)
{
struct thread *t, *next_thread;
/* Find another runnable thread. */
next_thread = 0;
t = current_thread + 1;
for (int i = 0; i < MAX_THREAD; i++)
{
if (t >= all_thread + MAX_THREAD)
t = all_thread;
if (t->state == RUNNABLE)
{
next_thread = t;
break;
} // 查询 RUNABLE 线程
t = t + 1;
}
if (next_thread == 0)
{
printf("thread_schedule: no runnable threads\n");
exit(-1);
}
if (current_thread != next_thread)
{ /* switch threads? */
next_thread->state = RUNNING;
t = current_thread;
current_thread = next_thread;
thread_switch((uint64)&t->context, (uint64)&next_thread->context); // 切换线程
}
else
next_thread = 0;
}
void thread_create(void (*func)())
{
struct thread *t;
for (t = all_thread; t < all_thread + MAX_THREAD; t++)
{
if (t->state == FREE)
break;
}
t->state = RUNNABLE;
t->context.ra = (uint64)func; // 返回地址
// thread_switch 的结尾会返回到 ra,从而运行线程代码
t->context.sp = (uint64)&t->stack + STACK_SIZE - 1; // 栈指针
// 将线程的栈指针指向其独立的栈,注意到栈的生长是从高地址到低地址,所以
// 要将 sp 设置为指向 stack 的最高地址
}
借鉴内核中的swtch。
.text
/*
* save the old thread's registers,
* restore the new thread's registers.
*/
.globl thread_switch
thread_switch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret /* return to ra */
Using threads (moderate)
实验很简单,分析并解决一个hash表操作的例子中,由于竞态条件导致数据丢失的问题。上锁!
上锁的粒度会影响程序的效率,所以我将锁的粒度降低到每一个桶一个锁。
// ph.c
pthread_mutex_t lock[NBUCKET];
int
main(int argc, char *argv[])
{
pthread_t *tha;
void *value;
double t1, t0;
for(int i=0;i<NBUCKET;i++) {
pthread_mutex_init(&locks[i], NULL);
}
// ......
}
static
void put(int key, int value)
{
int i = key % NBUCKET;
pthread_mutex_lock(&locks[i]);
// ......
pthread_mutex_unlock(&locks[i]);
}
static struct entry*
get(int key)
{
int i = key % NBUCKET;
pthread_mutex_lock(&locks[i]);
// ......
pthread_mutex_unlock(&locks[i]);
return e;
}
Barrier (moderate)
使用条件变量+锁来实现屏障同步机制。
static void
barrier()
{
pthread_mutex_lock(&bstate.barrier_mutex);
if (++bstate.nthread < nthread)
{
pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex);
}
else
{
bstate.nthread = 0;
bstate.round++;
pthread_cond_broadcast(&bstate.barrier_cond);
}
pthread_mutex_unlock(&bstate.barrier_mutex);
}