@[TOC])
新手上路,如果理解有问题,欢迎指出
大小端问题
此处,先了解大小端的概念
大端:高地址存放低字节,低地址存放高字节
小端:低地址存放低字节,高地址存放高字节
假设变量x的类型为int,位于地址0x01234567。地址范围0x100~0x103的字节顺序依赖于机器的类型。
大端法:

小端法:

大多数INTEL兼容机都只用小端模式
了解大小端概念之后,我们看一下17年的第17题
struct node
{
char s;
short b;
int c;
};
int main(int argc,char *argc[])
{
struct node s;
memset(&s,0,sizeof(s));//将一块内存中的内容全部设置为指定的值,这个函数通常为新申请的内存做初始化工作,对较大的结构体或数组进行清零操作的一种最快方式,头文件<string.h>或<memory.h>,此处是将变量s所占内存的值全部置为零。
s.a=3;
s.b=5;
s.c=7;
struct node *pt=&s;//定义结构体指针,使其指向s
printf("%d\n",*(int *)pt);//将指针pt转换为int类型指针,并解引用
printf("%lld\n",*(long long *)pt);//同理
return 0;
}
低地址 高地址
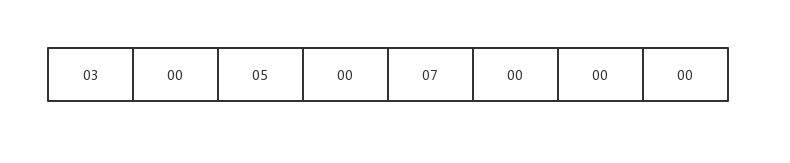 此处,我是以十六进制存储进去的,因为int占 四个字节,所以,第一次读出的十六进制的005003,将它转换成十进制,那么 ,long long也就很简单了,long long 占 8个字节 ,所读的应该是十六进制的0000007000500030,再将它转换为十进制就行了
此处,我是以十六进制存储进去的,因为int占 四个字节,所以,第一次读出的十六进制的005003,将它转换成十进制,那么 ,long long也就很简单了,long long 占 8个字节 ,所读的应该是十六进制的0000007000500030,再将它转换为十进制就行了
宏定义问题
可用#define定义一个标识符来表示一个常量,定义的标识符不占内存,预编译后这个符号就不存在了,(用双引号括起来的宏在预处理的时候是不会被宏替换的,在c中,用双引号括起来来的是字符)

宏参数展开规则:在展开宏参数时,如果当前宏含有有##或#,则不进行宏参数的展开,否则先展开宏参数,再展开当前宏
然后,我们看一下15年的第八题
#define f(a,b) a##b
#define g(a) #a
#deine h(a) g(a)
int main(int argc,char *argv[])
{
printf("%s\n",h(f(1,2)));
printf("%s\n",g(f(1,2)));
}
我们先看第一个printf,h()为当前宏,f()为宏参数,含有宏参数时,先展开宏参数,再展开当前宏,因为当前宏h()里不含有#或##,所以先展开f(1,2),##将1和2连接起来,组成12,然后再展开当前宏h(),将12转换为字符,所以输出12;第二个printf ,g()为当前宏,f()为宏参数,因为当前宏g()里含有#,所以不进行宏参数的展开,输出f(1,2);
数组问题
先看一个题
int main(int argc,char *argv[])
{
int a[3][4];
printf("%p%p%p%p%p%p",&a[0][0],a[0],a,a[0]+1,a+1,a[1]);
return 0;
}
若a[0][0]的地址是0x00000000,求程序输出的结果
这是一个二维数组,但严格来说没有什么二维数组,三维数组,我们可以把它看做是数组的数组或是数组的数组的数组,此时的二维数组就是一个数组的数组(可以看为一个大数组里包含了一个小数组),即对于a来说,它有3个元素,每个元素都是一个具有4个整型元素的一维数组,我们可以把a[0]看做第一个元素的数组名,其他类推
a=&a[0],所以有a+1=&a[0]+1,就是跨过第一行,(&a[0]跨越了整个第一个大数组)那么a[0]+1呢,此刻的a[0]是第一个大数组的数组名,所以a[0]+1就为第一个大数组中第二个元素的地址,即a[0][1]的地址,
此处,区别一下,a+1是第二行第一个元素的地址,&a+1跨越的是整个数组了
所以,这个题的答案为:
0x00000000
0x00000000
0x00000000
0x00000004
0x00000010
0x00000010
const关键字
定义const常变量,具有不可变性
它的作用有:

写题的时候,关键看const修饰谁,由于没有const的运算,所以若出现const的形式,则const实际上是修饰前面的
然后看一下17年的第七题
const char *p;
char const *p;
char *const p;
const char *const p;
前边已经说过,没有const这种形式,所以const修饰的是char,则char const p,const保护p,所以就是p不可以改,p可以改;那么 char const p,const修饰的是p,就和前者一样,*p不可以改,p可以改,然后就是char const p,此时const修饰指针为常量(有了常量的特性),即p可以改,p不能改 ,最后一种情况,const char const p,第一个const后面紧跟的是char,所以char类型的字符p不可改
然后再看一个题,
int main(int argc,char *argv[])
{
const int b=10;
//自行添加语句,改变变量的值
return 0;
}
前边说过,const修饰的变量具有不可变性,那么此时如何修改b的值呢?
我们可以通过指针来修改变量b的值,相信你一定写的出来
一个c语言程序从源代码到形成可执行文件的过程
 1.预编译:主要处理源代码文件中的以"#"开头的预编译指令,生成.i 文件
1.预编译:主要处理源代码文件中的以"#"开头的预编译指令,生成.i 文件
2.编译:将预编译之后生成的xxx.i文件,转换为汇编代码,生成.s文件
3.汇编:将汇编代码转换成机器可执行的机器代码,生成.o文件
4.链接:将有关的目标文件彼此相连接
关键字static
当自动变量被定义时,系统不会对其初始化,必须自行对其初始化,而定义static变量时,系统会自动对其初始化(数值型赋0,字符型赋‘、0’)
static全局变量与全局变量的区别
静态全局变量:全局变量的说明之前加上static就构成了静态的全局变量
我们先看一下非静态全局变量和静态全局变量的区别:
两者在存储方式上并无不同,都是静态存储方式
但作用域有区别,非静态全局变量的作用域是整个源程序,当一个源程序是多个源文件组成时,非静态全局变量在各个源文件中都是有效的,而静态全局变量只在当前文件中起作用
static全局变量只初始化一次,下一次被调用时保存的是上次调用结束的值
static局部变量与局部变量的区别
首先,两者的存储方式就不相同,static局部变量 static全局变量 和普通全局变量都为静态存储,而普通局部变量为动态存储

static函数与普通函数的区别
 然后我们看一个题
然后我们看一个题
static int a=2018;
static void func(void)
{
static int b;
printf("a=%d,b=%d\n",a++,++b);
}
int main()
{
func();
func();
func();
return 0;
}
猜一下它的输出结果(应该是a=2018,b=1,a=2019,b=2,a=2020,b=3)
标准输出与标准错误
先看一个题
int main()
{
while(1)
{
fprintf(stdout,"group");
fprintf(stderr,"xiyoulinux");
getchar();
}
return 0;
}
对比上面程序在linux和windows上面的输出结果,并思考原因
linux上应该是:xiyouLinuxgroup
windows上应该是:groupxiyoulinux
这是因为在linux下** 将group放在了缓冲区内,直到程序结束,才将缓冲区中的数据导出**
而windows下没有
在默认情况下,stdout是行缓冲的,它的输出会放在一个buffer内,只有到换行的时候才会输出到屏幕,而stderr是无缓冲的,会直接输出
stdout:标准输出,输出方式是行缓冲,输出的字符放在缓冲区内,等按下回车键才进行实际的操作,stdout输出的第二种情况是** 即遇到换行符时输出,执行清理缓存**
stderr:标准错误,是不带缓冲的,错误信息可以直接显示出结果
可以在了解一下其他的内容:(图画的很丑~假装没看到

指针问题
再看一个题
void get(char *ptr)
{
ptr=(char *)malloc(17);
strcpy(ptr,"xiyou linux group");
}
int main()
{
char *str=NULL;
get(str);
printf("%s\n",str);
}
这个程序在电脑上运行会出错
main函数里的指针str指向空,get函数中的malloc函数为指针pt分配空间,将str指针传进get函数,但要搞清楚,str指针依旧指向空,所以在strcpy函数中,字符串根本写不进去,这就解释了为什么电脑会报错
我们可以将ptr的地址返回回来
代码修改如下:
char* get(char *ptr)
{
ptr=(char *)malloc(17);
strcpy(ptr,"xiyou linux group");
return ptr;
}
int main()
{
char *str;
str=get(str);
printf("%s\n",str);
}
或者可以使用二级指针
char* get(char **ptr)
{
*ptr=(char **)malloc(17);
strcpy(*ptr,"xiyou linux group");
}
int main()
{
char *str;
get(&str);
printf("%s\n",str);
}
这两种方法都可以使源代码正确,但是,这个程序中有一个很隐秘的问题,xiyou linux group加上后面的结束符‘0’,一共18个字符,但是仅仅为它分配了17个字节的空间,程序不会报错,但不安全,因为你占用了后面的内存,可能会引发一些未知的问题
隐式转换问题
先看代码
int main()
{
unsigned int a=10;
int b=-20;
if(a+b>0)
{
printf("a+b=%d\n",a+b);
}
else
{
printf("a=%d,b=%d\n",a,b);
}
return 0;
}
数字在计算机内部是以二进制补码进行运算的,所以先将-20转为为二进制,在求它的补码而无符号数的补码最高位不表示符号,所以一个负数表示为无符号数的时候他就会变成一个很大的正数,所以上题中的a在和b相加的时候b会变成一个很大的正数所以a+b就大于0了
sizeof问题
int main()
{
int t=4;
printf("%lu",sizeof(t--));
printf("%liiigviiilu",sizeof("ab c\nt\012\xa1*2"));
return 0;
}
sizeof()的值是在编译时确定的,它的作用是获得保证能容纳实现所建立的最大对象的字节大小
第一个pirntf语句里面即使t–,t也是个int型变量,输出的肯定是int类型所占的字节数;
第二个printf语句里面a b c 空格 \n t \012 \xa1 * 2 '\0’一共11个字符,所占字节为11个,此处,需要注意的就是\012是一个八进制数,\xa1是一个十六进制数, ddd表示八进制数所代表的字符,可以不用0开头,也可以用0开头,\xhh表示十六进制数所代表的字符
字节截断问题
我们看这个题
intmain()
{
char str[512];
int i;
for(i=0;i<512;i++)
{
str[i]=-1-i;
}
printf("%lu\n",strlrn(str));
}
将str[i]=-1,char类型占一个字节,int类型占四个字节,所以会存在字节截断的问题,如下图所示
 然后根据代码,
然后根据代码,
 所以当srt[255]=-256时,转换为十进制为0,那么根ASCII表,0所对应的为null,所以strlen读到null时就停止了,所以这个题的答案为255
所以当srt[255]=-256时,转换为十进制为0,那么根ASCII表,0所对应的为null,所以strlen读到null时就停止了,所以这个题的答案为255
关键字extern
#void func()
{
printf("a=%d\n",a);\\此时此刻func函数里找不到a变量
}
int a=10;
int main()
{
func();
return 0;
}
要求不改变以下代码的运行顺序,修改程序使其能通过编译器运行
此时,就可以用extern关键字了,要注意,*** 当一个变量是全局变量时,才可以引用extern关键字 ***,在func函数里添加一句extern int a,告诉编译器a这个变量是存在的,但不是在这声明的,你到别的地方去找找
extern其他的作用是:
引用不在同一个文件下的变量
字节对齐问题
字节对齐有助于加快cpu的读取速度
struct icd
{
int a;
char b;
double c;
};
struct cdi
{
char a;
double b;
int c;
};
sizeof(icd)=16;
sizeof(cdi)=24;
此处就涉及到了字节对齐问题,

