文章目录
引言
使得公有云中架构不得不改变的关键因素有三个,disaggregation,multi-tenancy,serverless。
disaggregation由存储与计算资源需要分别扩容的需求驱动。
multi-tenancy则是源自于为每个租户提供专用硬件根本不符合成本效益,在租户之间共享资源能够使云供应商能够大幅降低提供服务的成本。
而serverless是为了在负载多变的情况下降低成本,租户不再需要提前为高峰期的使用提供资源,由云供应商根据数据库工作负载的需求来获取和释放资源,租户只需为其工作负载实际使用的资源付费。
从多租户的角度讲,安全性/性能与成本其实是互相矛盾的,[7]中提到:
• Degree of consolidation: The higher up in the stack virtualization is supported, the greater the degree of consolidation
achievable, leading to lower cost for the service provider.
• Degree of isolation: The lower down in the stack the virtualization logic is supported, the greater is the security and
performance isolation achievable across tenants.
所以为了成本的卖点,除了KV以外的其他模态时常会放弃提供吞吐量和延时的SLO,而是在实现上保证用户可以使用的资源最低限制,转而提供可用性的的SLO。因为为了保证性能的SLO需要预留资源,不但是POD内部的资源预留(高利用率导致性能下降),也还有POD的级别资源的预留。所以公有云服务提供商往往倾向于SLO要求高的用户独占资源,价格提高,而SLO需求不强的用户则降低价格,出售本来不会被使用到的资源。
从下面列举的各种公有云时序数据库提供方定价来看基本分为三类:
| 类别 | 公有云服务提供方 |
|---|---|
| 存储量+RU | CosmosDB |
| 存储量+扫描数据量+写入数据量 | Influxdb Cloud,Amazon Timestream |
| 存储量+实例+其他 | 腾讯云CTSDB,阿里云Lindom,阿里云TSDB,华为云GaussDB(for Influx) |
站在公有云服务提供商的角度:
- 存储量+RU:设计原则上看成本最低,因为RU本身代表了CPU/存储IO/网络IO/Memory四个维度的归一化抽象单位,本身可以最真实的反映用户所使用的资源数量。用户体验最好,但是有理解成本。
- 存储量+扫描数据量+写入数据量 :更加单一,因为时序场景计算需求也非常强烈,跨越一天的时间查询往往存在千万级别的时间序列,这导致在存储量之前可能有其他资源首先到达瓶颈,这对于提供商来讲意味着亏损,但是因为不提供预配吞吐量和自动缩放吞吐量,看起来就是一个阉割版的serverless。用户体验也不差,且容易理解。
- 存储量+实例+其他:对于用户和运营商来说都是成本较高的选择,因为资源本身大概率是闲置的,用户为了流量突发只能购买更大规格的实例,提供商为了保证流量突发也不能过度超卖这部分资源。
serverless
从定价上看前两种就是Serverless的一种体现,但是难点在于多租户的隔离。因为CPU的使用只会转移而不会消失,计算与存储分离可以使得存储层面租户间共享且隔离,但是计算节点此时仍旧独占,这对于公有云提供商来说仍旧是成本,因为我卖的是RU/扫描数据量,但是我还是有单独的机器分配给了某个租户。
如果计算节点共享,此时需要面对的就是CPU隔离的问题,DBaas对于此类问题的讨论已经持续十几年[9][10][11][12],已经拥有了成熟的解决方案,但是均需要从引擎上下手,投入开发的人力成本也不可小觑。
所以以目前的发展现状来看,计算与存储分离,计算层隔离需要引擎的定制化改造,存储层因为吐的是原始数据,基于RU的隔离完全够用,计算层和存储层都做多租户隔离,用户不关心规格,这样Serverless的定价就会非常利好服务提供商和用户。因为对于用户来说,我买了两台机器的RU/写入读取数据量(vcore转RU[13]),可能我的查询实际可能跑在几十台机器上,而且池子够大,业务的高峰流量完全可以hou住;对于提供商来说,因为用户业务属性的不同,我在超卖率极高的情况下仍旧满足用户的需求,且池子随时可以扩缩容。
实例售卖
不利好服务提供商和用户,运营商不敢超卖太多,用户不敢买规格太小。
结论
从上述结论来看,serverless的计费方式显然是大势所趋,但是因为时序场景的特殊,用单纯的扫描数据量无法衡量实际的资源使用情况,数据类型才是影响实际资源消耗的关键,比如iot,监控,trace,会议,直播等场景。维度数,Field稀疏程度,tag大小,短生命周期时间序列等等都对整体资源使用冲击极大,而且冲击是全方位的,存储成本(压缩率),CPU利用率,内存利用率,接入机和存储机器之间的数据传输量都受实际查询类型和数据类型的影响。
所以拥有一个精确衡量资源使用的RU计量方法,且基于此执行serverless收费+存储量是最优的方案。
这个方案有一个问题客观存在,即Dynamodb和CosmosDB对于RU框架有一个重要的约束是:为了方便管理和规划容量,确保针对给定数据集执行的给定数据库操作的 RU 数是确定性的以及用户的可理解性,Dynamodb和CosmosDB均使用扫描的数据量作为RU的计费单位。
时序场景因为查询的特殊性不存在像是KV模态一样稳定的基准线,即扫描的数据量无法代表实际集群的资源消耗(当其他维度先到达瓶颈是就会亏钱),所以不能精确衡量集群资源调度和分配租户,这就是矛盾痛处。
Azure CosmosDB
虽然没有标准的时序模态,但是cosmosdb的计费标准实在是太经典。计费方式分为预配吞吐量,自动缩放吞吐量和Serverless,显然的从RU成本上看,预配吞吐量>自动缩放吞吐量>Serverless。其实从实现的角度讲这么做很好理解,因为云服务是无限扩展的,但是给一个租户总是要预留预期的固定资源,当然这部分资源在实际的存储和计算几点上都是多租户共享的,那自然用户指定上限越高,收费就越贵了。
另外存储量,定期备份(大于两个),流水备份,multi region,专用gateway都是额外收费的选项。通过预留容量,包年的价格还可以优惠14%到44%。
这里很有意思的一点在于这里关于可用性只提到了region级别而没有提及到副本级别,理论上上我们最好给用户足够的自由性,用户不但可以指定副本数,region数,甚至可以指定副本的角色和一致性级别,以达到用户降本的需求。
预配吞吐量

自动缩放吞吐量

Serverless

预留容量

存储量

目前汇率算到话1人民币等于0.14美元,所以这里成本转化人民币分别为¥1.785和¥0.214,可以说是非常实惠了,至于行列导向价钱差别大的的原因也很好理解,列式的压缩比可以做到非常夸张,而行式就没那么容易了,而且还会因为比如集群容量预估不准确导致LSM树形不标准,额外元信息较多等原因造成容量上涨。这里计费采用的是压缩前的容量。
还有这里的容量规划器工具[1]还是很有意思的,以后我们这边也有一个这玩意就好了。
Amazon Timestream
Amazon Timestream按照下面四个维度收费,
- 写入次数:从应用程序写入表格的数据量(四舍五入到最接近的 KB)。
- 查询次数:Amazon Timestream 的无服务器分布式查询引擎在计算查询结果时扫描的数据量(四舍四入到最近的 MB,最小值为 10MB)。
- 内存存储:每个表的内存存储中存储的数据量
- 磁性存储:每个表的磁性存储中存储的数据量。
对于这样的定价策略其实可以看出aws还是对自己相当自信。
aws给出了一些优化成本的方法,参考[3]。我觉得其中很多方法我们可以用到,比如:
- 用通用属性减少用户的写入量
- 给用户一些减少查询使用量的建议,这同时也是保护我们自己,因为公有云中一些架构下多租户隔离还是比较难做的
写入计费

查询计费

存储

阿里云TSDB
TSDB的定价可以参考[5],一看就是典型的上一代云产品,基于Hbase的KV引擎,这种计费模式下其实做多租户很麻烦,因为单个集群盘子太小,超卖的风险太高,无法像云原生数据库那样做到优雅的隔离。
阿里云Lindom时序引擎
Lindom在公有云上的架构构成如下:
- Lindom实例固定费用
- 存储空间费用
- 节点费用(不同规格,不同引擎不同)
- 云盘
- LTS数据导入服务
- 备份
- 计算引擎下的弹性计算资源
仅仅看时序引擎,也是传统的按量付费和按照节点规格包月付费。目前Lindom 的架构在官方图中可以看到是LindomStore分布式文件系统之上构建多个协议的引擎,时序引擎则是由TSCore/TSCompute/TSProxy构成,可以想来给用户卖TSProxy,实际数据存储在TSCore,TSCompute做实时数据聚合和降采样(减少TSCore的资源使用)。
但是Lindom基于TSM/TSI的做法也会有不同场景导致性能/资源使用差异极大的情况,这种计费也很难满足一些极端客户的场景,可能会导致为了满足用户的场景,实例需要买非常大,价格收费非常高;而且因为不支持Serverless,虽然时序场景写入稳定,但是用户的查询却是不太稳定的,显然晚上BI分析,视图展示等需求就是会降低很多,这也是一大劣势点。本质其实在于用户可能无法很好的预估自己的使用规格,对用户来说可能造成很大的资源浪费,那用户可能会天天有扩缩容的需求,运营也很麻烦,但倘若支持serverless,不同的用户的就会有更适合的选择余地。


实例固定费用

存储费用

节点费用

华为云GaussDB(for Influx)
华为云的定价可以参考[6],定价策略更加简洁易懂,即就卖节点和存储,这也是存算分离下很经典的计费模式,但是华为的价格真是不便宜啊,比阿里快贵了一倍了。
值得一提的是华为规定了每台实例的可以的时间线上限和没次查询的field和时间线,我的想法就是无法支持基数爆炸的场景,基数爆炸对性能影响太大,只能紧止掉。


这架构图实在是不太走心,画的有点抽象,不过可以看出来和lindom是一个路数。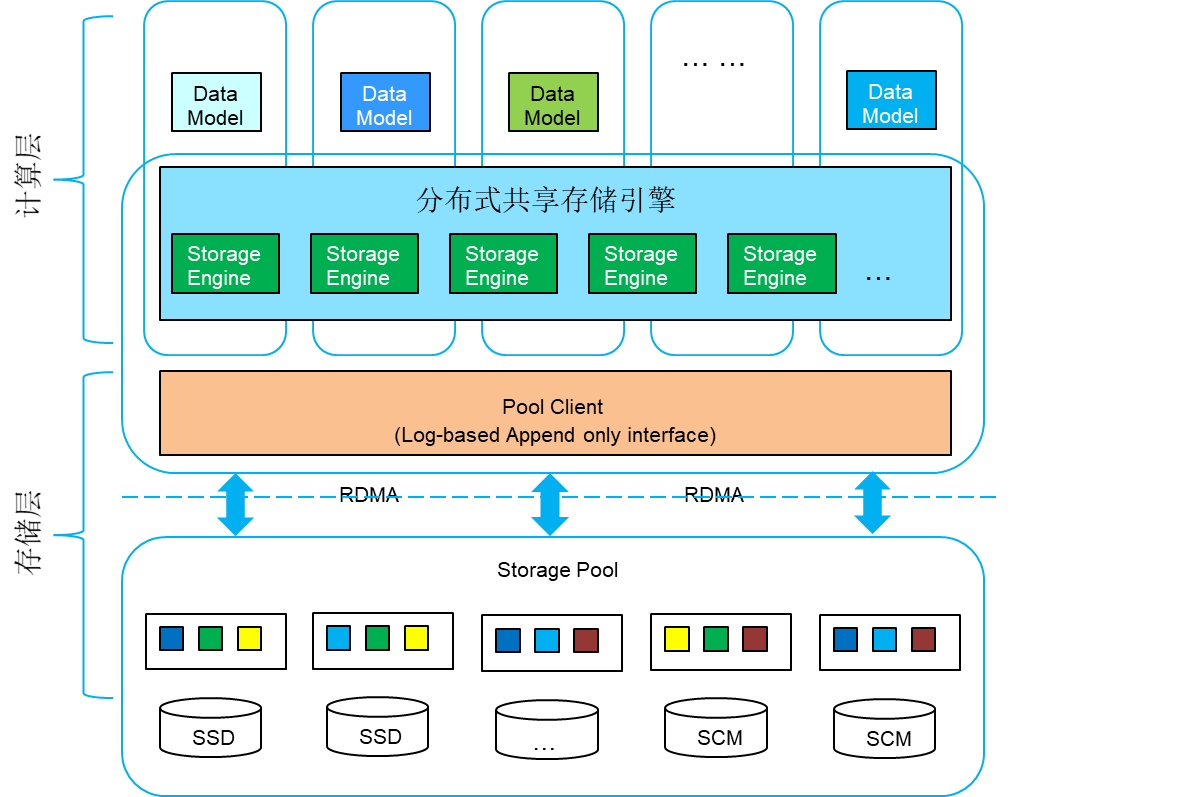
腾讯云CTSDB
说是内存规格+存储空间,本质还是按照不同的节点规格收费,分为包年包月和按时间消费,不过这个阶梯式收费就很迷。

TDengine
需要联系销售,正在联系中。
InfluxDB Cloud
可以看到在各大公有云上的产品计费策略是使用存储量+实际查询数+查询数据量+写入数据量,不愧是垂直领域龙头,
AWS

Google Cloud
价格和AWS一致
Microsoft Azure

虽然各大公有云厂商没有规定基数限制,但是infludb cloud中是有限制的,但是需要联系销售,正在联系中。

参考:
- https://cosmos.azure.com/capacitycalculator/
- https://azure.microsoft.com/zh-cn/pricing/details/cosmos-db/
- https://docs.aws.amazon.com/timestream/latest/developerguide/metering-and-pricing.html
- https://help.aliyun.com/document_detail/387477.html?spm=a2c4g.610211.0.0.2e8a7c30QCWmwn
- https://www.alibabacloud.com/zh/product/hitsdb
- https://support.huaweicloud.com/influxug-nosql/nosql_05_0045.html
- Multi-Tenant Cloud Data Services: State-of-the-Art, Challenges and Opportunities
- Tenant Placement in Oversubscribed Database-as-a-Service Clusters
- SQLVM: Performance Isolation in Multi-Tenant Relational Database-as-a-Service
- Retro: Targeted Resource Management in Multi-tenant Distributed Systems
- 2DFQ: Two-Dimensional Fair Queueing for Multi-Tenant Cloud Services
- CPU Sharing Techniques for Performance Isolation in Multi-tenant Relational Database-as-a-Service
- https://learn.microsoft.com/zh-cn/azure/cosmos-db/convert-vcore-to-request-unit