GCC早期的版本使用Lex/Flex工具进行C语言的词法分析,较新的版本则使用专门开发的词法分析代码,主要位于gcc/c-lex.c, libcpp/lex.c中。
为了说明词法分析的过程,可以在源代码中增加一些调试代码,将GCC进行词法分析的过程导出,从而进行详细地分析。添加的代码主要包括:
(1) 在gcc/c-parser.c中增加如下词法符号的导出代码。
dump_a_token(c_token *ct){
FILE *fp;
static int i = 1;
expanded_location xloc;
xloc = expand_location(ct->location);
fp=fopen("dump-token", "a");
fprintf(fp, "[%d] %-16s %-10s %-12s %-12s %8s:%d,%d\n", i++, cpp_ttype_str[ct->type], c_id_kind_str[ct->id_kind], rid_str[ct->keyword], pragma_kind_str[ct->pragma_kind], xloc.file, xloc.line, xloc.column); /* 打印符号值的基本信息 */
if(ct->value) dump_node(ct->value, 0xffff, fp); /* 打印符号值:树节点 */
fclose(fp);
}(2) 在libcpp/include/cpplib.h中增加词法符号类型名称的数组cpp_ttype_str[]。
static char *cpp_ttype_str[]={
"CPP_EQ", "CPP_NOT", "CPP_GREATER", "CPP_LESS", "CPP_PLUS", "CPP_MINUS", "CPP_MULT", "CPP_DIV", "CPP_MOD",
"CPP_AND", "CPP_OR", "CPP_XOR", "CPP_RSHIFT", "CPP_LSHIFT", "CPP_COMPL", "CPP_AND_AND", "CPP_OR_OR",
"CPP_QUERY", "CPP_COLON", "CPP_COMMA", "CPP_OPEN_PAREN", "CPP_CLOSE_PAREN", "CPP_EOF", "CPP_EQ_EQ",
"CPP_NOT_EQ", "CPP_GREATER_EQ", "CPP_LESS_EQ", "CPP_PLUS_EQ", "CPP_MINUS_EQ", "CPP_MULT_EQ",
"CPP_DIV_EQ","CPP_MOD_EQ", "CPP_AND_EQ", "CPP_OR_EQ", "CPP_XOR_EQ", "CPP_RSHIFT_EQ", "CPP_LSHIFT_EQ",
"CPP_HASH","CPP_PASTE", "CPP_OPEN_SQUARE", "CPP_CLOSE_SQUARE", "CPP_OPEN_BRACE", "CPP_CLOSE_BRACE",
"CPP_SEMICOLON","CPP_ELLIPSIS", "CPP_PLUS_PLUS", "CPP_MINUS_MINUS", "CPP_DEREF", "CPP_DOT", "CPP_SCOPE",
"CPP_DEREF_STAR", "CPP_DOT_STAR", "CPP_ATSIGN", "CPP_NAME", "CPP_AT_NAME", "CPP_NUMBER", "CPP_CHAR",
"CPP_WCHAR", "CPP_CHAR16", "CPP_CHAR32", "CPP_OTHER", "CPP_STRING", "CPP_WSTRING", "CPP_STRING16",
"CPP_STRING32", "CPP_OBJC_STRING", "CPP_HEADER_NAME", "CPP_COMMENT", "CPP_MACRO_ARG", "CPP_PRAGMA",
"CPP_PRAGMA_EOL", "CPP_PADDING", "CPP_MAX_TYPE", "CPP_KEYWORD"
};(3) 在gcc/c-parser.c中增加标识符类型名称的字符串数组c_id_kind_str[]。
static char * c_id_kind_str[] = {
"C_ID_ID",
"C_ID_TYPENAME",
"C_ID_CLASSNAME",
"C_ID_NONE"
};(4) 在gcc/c-common.h中增加关键字名称数组rid_str[]。
static char *rid_str[] ={
"RID_STATIC",
"RID_UNSIGNED", "RID_LONG", "RID_CONST", "RID_EXTERN", "RID_REGISTER", "RID_TYPEDEF", "RID_SHORT", "RID_INLINE",
"RID_VOLATILE", "RID_SIGNED", "RID_AUTO", "RID_RESTRICT", "RID_COMPLEX", "RID_THREAD", "RID_SAT",
"RID_FRIEND", "RID_VIRTUAL", "RID_EXPLICIT", "RID_EXPORT", "RID_MUTABLE",
"RID_IN", "RID_OUT", "RID_INOUT", "RID_BYCOPY", "RID_BYREF", "RID_ONEWAY",
"RID_INT", "RID_CHAR", "RID_FLOAT", "RID_DOUBLE", "RID_VOID",
"RID_ENUM", "RID_STRUCT", "RID_UNION", "RID_IF", "RID_ELSE",
"RID_WHILE", "RID_DO", "RID_FOR", "RID_SWITCH", "RID_CASE",
"RID_DEFAULT", "RID_BREAK", "RID_CONTINUE", "RID_RETURN", "RID_GOTO", "RID_SIZEOF",
"RID_ASM", "RID_TYPEOF", "RID_ALIGNOF", "RID_ATTRIBUTE", "RID_VA_ARG",
"RID_EXTENSION", "RID_IMAGPART", "RID_REALPART", "RID_LABEL", "RID_CHOOSE_EXPR",
"RID_TYPES_COMPATIBLE_P", "RID_DFLOAT32", "RID_DFLOAT64", "RID_DFLOAT128", "RID_FRACT", "RID_ACCUM",
"RID_CXX_COMPAT_WARN", "RID_FUNCTION_NAME", "RID_PRETTY_FUNCTION_NAME", "RID_C99_FUNCTION_NAME",
"RID_BOOL", "RID_WCHAR", "RID_CLASS", "RID_PUBLIC", "RID_PRIVATE", "RID_PROTECTED",
"RID_TEMPLATE", "RID_NULL", "RID_CATCH", "RID_DELETE", "RID_FALSE", "RID_NAMESPACE",
"RID_NEW", "RID_OFFSETOF", "RID_OPERATOR", "RID_THIS", "RID_THROW", "RID_TRUE",
"RID_TRY", "RID_TYPENAME", "RID_TYPEID", "RID_USING", "RID_CHAR16", "RID_CHAR32",
"RID_CONSTCAST", "RID_DYNCAST", "RID_REINTCAST", "RID_STATCAST",
"RID_HAS_NOTHROW_ASSIGN", "RID_HAS_NOTHROW_CONSTRUCTOR", "RID_HAS_NOTHROW_COPY", "RID_HAS_TRIVIAL_ASSIGN",
"RID_HAS_TRIVIAL_CONSTRUCTOR", "RID_HAS_TRIVIAL_COPY", "RID_HAS_TRIVIAL_DESTRUCTOR", "RID_HAS_VIRTUAL_DESTRUCTOR",
"RID_IS_ABSTRACT", "RID_IS_BASE_OF", "RID_IS_CONVERTIBLE_TO", "RID_IS_CLASS", "RID_IS_EMPTY", "RID_IS_ENUM",
"RID_IS_POD", "RID_IS_POLYMORPHIC", "RID_IS_UNION", "RID_STATIC_ASSERT", "RID_DECLTYPE",
"RID_AT_ENCODE", "RID_AT_END", "RID_AT_CLASS", "RID_AT_ALIAS", "RID_AT_DEFS",
"RID_AT_PRIVATE", "RID_AT_PROTECTED", "RID_AT_PUBLIC", "RID_AT_PROTOCOL", "RID_AT_SELECTOR",
"RID_AT_THROW", "RID_AT_TRY", "RID_AT_CATCH", "RID_AT_FINALLY", "RID_AT_SYNCHRONIZED",
"RID_AT_INTERFACE", "RID_AT_IMPLEMENTATION", "RID_MAX"
};(5) 在gcc/c-pragma.h中增加编译制导名称数组pragma_kind_str[]。
static char *pragma_kind_str[]={
"PRAGMA_NONE", "PRAGMA_OMP_ATOMIC", "PRAGMA_OMP_BARRIER", "PRAGMA_OMP_CRITICAL", "PRAGMA_OMP_FLUSH", "PRAGMA_OMP_FOR", "PRAGMA_OMP_MASTER", "PRAGMA_OMP_ORDERED", "PRAGMA_OMP_PARALLEL", "PRAGMA_OMP_PARALLEL_FOR",
"PRAGMA_OMP_PARALLEL_SECTIONS", "PRAGMA_OMP_SECTION", "PRAGMA_OMP_SECTION", "PRAGMA_OMP_SINGLE",
"PRAGMA_OMP_TASK", "PRAGMA_OMP_TASKWAIT", "PRAGMA_OMP_THREADPRIVATE", "PRAGMA_GCC_PCH_PREPROCESS",
"PRAGMA_FIRST_EXTERNAL"
};修改完成后,对GCC代码进行重新编译,使用修改后的编译器程序cc1编译源代码,就可以将编译过程中的词法分析过程输出到dump-token文件中。通过对源文件和dump-token文件进行对比阅读,可以较为详细地看出GCC进行词法分析的详细过程,下面通过一个例子来说明。
例4-20 GCC词法分析实例
假设有如下的源代码:
[GCC@localhost test]$ cat test.c
int main(int argc, char *argv[]){
int i=0;
int sum=0;
for(i=0; i<10; i++){
sum = sum + i;
}
return sum;
}使用修改后的cc1进行编译:
[GCC@localhost test]$ ~/paag-gcc/host-i686-pc-linux-gnu/gcc/cc1 test.c查看词法分析过程文件dump-token:
[GCC@localhost lexer]$ cat dump-token
[LEXER: 1 ] CPP_KEYWORD C_ID_NONE RID_INT PRAGMA_NONE test.c:1,1
@1 identifier_node strg: int lngt: 3 addr: b7cfd348
[LEXER: 2 ] CPP_NAME C_ID_ID RID_MAX PRAGMA_NONE test.c:1,5
@1 identifier_node strg: main lngt: 4 addr: b7d66930
[LEXER: 3 ] CPP_OPEN_PAREN C_ID_NONE RID_MAX PRAGMA_NONE test.c:1,9
[LEXER: 4 ] CPP_KEYWORD C_ID_NONE RID_INT PRAGMA_NONE test.c:1,10
@1 identifier_node strg: int lngt: 3 addr: b7cfd348
[LEXER: 5 ] CPP_NAME C_ID_ID RID_MAX PRAGMA_NONE test.c:1,14
@1 identifier_node strg: argc lngt: 4 addr: b7d82c08
[LEXER: 6 ] CPP_COMMA C_ID_NONE RID_MAX PRAGMA_NONE test.c:1,18
[LEXER: 7 ] CPP_KEYWORD C_ID_NONE RID_CHAR PRAGMA_NONE test.c:1,20
@1 identifier_node strg: char lngt: 4 addr: b7cfd0a8
[LEXER: 8 ] CPP_MULT C_ID_NONE RID_MAX PRAGMA_NONE test.c:1,25
[LEXER: 9 ] CPP_NAME C_ID_ID RID_MAX PRAGMA_NONE test.c:1,26
@1 identifier_node strg: argv lngt: 4 addr: b7d82c40
[LEXER: 10 ] CPP_OPEN_SQUARE C_ID_NONE RID_MAX PRAGMA_NONE test.c:1,30
[LEXER: 11 ] CPP_CLOSE_SQUARE C_ID_NONE RID_MAX PRAGMA_NONE test.c:1,31
[LEXER: 12 ] CPP_CLOSE_PAREN C_ID_NONE RID_MAX PRAGMA_NONE test.c:1,32
[LEXER: 13 ] CPP_OPEN_BRACE C_ID_NONE RID_MAX PRAGMA_NONE test.c:1,33
[LEXER: 14 ] CPP_KEYWORD C_ID_NONE RID_INT PRAGMA_NONE test.c:2,2
@1 identifier_node strg: int lngt: 3 addr: b7cfd348
[LEXER: 15 ] CPP_NAME C_ID_ID RID_MAX PRAGMA_NONE test.c:2,6
@1 identifier_node strg: i lngt: 1 addr: b7d82cb0
[LEXER: 16 ] CPP_EQ C_ID_NONE RID_MAX PRAGMA_NONE test.c:2,7
[LEXER: 17 ] CPP_NUMBER C_ID_NONE RID_MAX PRAGMA_NONE test.c:2,8
@1 integer_cst type: @2 low : 0 addr: b7cefccc
@2 integer_type name: @3 size: @4 algn: 32
prec: 32 sign: signed min : @5
max : @6 addr: b7cfe2d8
@3 type_decl name: @7 type: @2 srcp: <built-in>:0
addr: b7cfe680
@4 integer_cst type: @8 low : 32 addr: b7cef690
@5 integer_cst type: @2 high: -1 low : -2147483648
addr: b7cef63c
@6 integer_cst type: @2 low : 2147483647 addr: b7cef658
@7 identifier_node strg: int lngt: 3 addr: b7cfd348
@8 integer_type name: @9 size: @10 algn: 64
prec: 36 sign: unsigned min : @11
max : @12 addr: b7cfe068
@9 identifier_node strg: bit_size_type lngt: 13
addr: b7cfd9a0
@10 integer_cst type: @8 low : 64 addr: b7cef78c
@11 integer_cst type: @8 low : 0 addr: b7cefc08
@12 integer_cst type: @8 high: 15 low : -1
addr: b7cefbd0
[LEXER: 18 ] CPP_SEMICOLON C_ID_NONE RID_MAX PRAGMA_NONE test.c:2,9
[LEXER: 19 ] CPP_KEYWORD C_ID_NONE RID_INT PRAGMA_NONE test.c:3,2
@1 identifier_node strg: int lngt: 3 addr: b7cfd348
[LEXER: 20 ] CPP_NAME C_ID_ID RID_MAX PRAGMA_NONE test.c:3,6
@1 identifier_node strg: sum lngt: 3 addr: b7d82ce8
[LEXER: 21 ] CPP_EQ C_ID_NONE RID_MAX PRAGMA_NONE test.c:3,9
[LEXER: 22 ] CPP_NUMBER C_ID_NONE RID_MAX PRAGMA_NONE test.c:3,10
@1 integer_cst type: @2 low : 0 addr: b7cefccc
@2 integer_type name: @3 size: @4 algn: 32
prec: 32 sign: signed min : @5
max : @6 addr: b7cfe2d8
@3 type_decl name: @7 type: @2 srcp: <built-in>:0
addr: b7cfe680
@4 integer_cst type: @8 low : 32 addr: b7cef690
@5 integer_cst type: @2 high: -1 low : -2147483648
addr: b7cef63c
@6 integer_cst type: @2 low : 2147483647 addr: b7cef658
@7 identifier_node strg: int lngt: 3 addr: b7cfd348
@8 integer_type name: @9 size: @10 algn: 64
prec: 36 sign: unsigned min : @11
max : @12 addr: b7cfe068
@9 identifier_node strg: bit_size_type lngt: 13
addr: b7cfd9a0
@10 integer_cst type: @8 low : 64 addr: b7cef78c
@11 integer_cst type: @8 low : 0 addr: b7cefc08
@12 integer_cst type: @8 high: 15 low : -1
addr: b7cefbd0
[LEXER: 23 ] CPP_SEMICOLON C_ID_NONE RID_MAX PRAGMA_NONE test.c:3,11
[LEXER: 24 ] CPP_KEYWORD C_ID_NONE RID_FOR PRAGMA_NONE test.c:4,2
@1 identifier_node strg: for lngt: 3 addr: b7cfd2a0
[LEXER: 25 ] CPP_OPEN_PAREN C_ID_NONE RID_MAX PRAGMA_NONE test.c:4,5
[LEXER: 26 ] CPP_NAME C_ID_ID RID_MAX PRAGMA_NONE test.c:4,6
@1 identifier_node strg: i lngt: 1 addr: b7d82cb0
[LEXER: 27 ] CPP_EQ C_ID_NONE RID_MAX PRAGMA_NONE test.c:4,7
[LEXER: 28 ] CPP_NUMBER C_ID_NONE RID_MAX PRAGMA_NONE test.c:4,8
@1 integer_cst type: @2 low : 0 addr: b7cefccc
@2 integer_type name: @3 size: @4 algn: 32
prec: 32 sign: signed min : @5
max : @6 addr: b7cfe2d8
@3 type_decl name: @7 type: @2 srcp: <built-in>:0
addr: b7cfe680
@4 integer_cst type: @8 low : 32 addr: b7cef690
@5 integer_cst type: @2 high: -1 low : -2147483648
addr: b7cef63c
@6 integer_cst type: @2 low : 2147483647 addr: b7cef658
@7 identifier_node strg: int lngt: 3 addr: b7cfd348
@8 integer_type name: @9 size: @10 algn: 64
prec: 36 sign: unsigned min : @11
max : @12 addr: b7cfe068
@9 identifier_node strg: bit_size_type lngt: 13
addr: b7cfd9a0
@10 integer_cst type: @8 low : 64 addr: b7cef78c
@11 integer_cst type: @8 low : 0 addr: b7cefc08
@12 integer_cst type: @8 high: 15 low : -1
addr: b7cefbd0
[LEXER: 29 ] CPP_SEMICOLON C_ID_NONE RID_MAX PRAGMA_NONE test.c:4,9
[LEXER: 30 ] CPP_NAME C_ID_ID RID_MAX PRAGMA_NONE test.c:4,11
@1 identifier_node strg: i lngt: 1 addr: b7d82cb0
[LEXER: 31 ] CPP_LESS C_ID_NONE RID_MAX PRAGMA_NONE test.c:4,12
[LEXER: 32 ] CPP_NUMBER C_ID_NONE RID_MAX PRAGMA_NONE test.c:4,13
@1 integer_cst type: @2 low : 10 addr: b7d889a0
@2 integer_type name: @3 size: @4 algn: 32
prec: 32 sign: signed min : @5
max : @6 addr: b7cfe2d8
@3 type_decl name: @7 type: @2 srcp: <built-in>:0
addr: b7cfe680
@4 integer_cst type: @8 low : 32 addr: b7cef690
@5 integer_cst type: @2 high: -1 low : -2147483648
addr: b7cef63c
@6 integer_cst type: @2 low : 2147483647 addr: b7cef658
@7 identifier_node strg: int lngt: 3 addr: b7cfd348
@8 integer_type name: @9 size: @10 algn: 64
prec: 36 sign: unsigned min : @11
max : @12 addr: b7cfe068
@9 identifier_node strg: bit_size_type lngt: 13
addr: b7cfd9a0
@10 integer_cst type: @8 low : 64 addr: b7cef78c
@11 integer_cst type: @8 low : 0 addr: b7cefc08
@12 integer_cst type: @8 high: 15 low : -1
addr: b7cefbd0
[LEXER: 33 ] CPP_SEMICOLON C_ID_NONE RID_MAX PRAGMA_NONE test.c:4,15
[LEXER: 34 ] CPP_NAME C_ID_ID RID_MAX PRAGMA_NONE test.c:4,17
@1 identifier_node strg: i lngt: 1 addr: b7d82cb0
[LEXER: 35 ] CPP_PLUS_PLUS C_ID_NONE RID_MAX PRAGMA_NONE test.c:4,18
[LEXER: 36 ] CPP_CLOSE_PAREN C_ID_NONE RID_MAX PRAGMA_NONE test.c:4,20
[LEXER: 37 ] CPP_OPEN_BRACE C_ID_NONE RID_MAX PRAGMA_NONE test.c:4,21
[LEXER: 38 ] CPP_NAME C_ID_ID RID_MAX PRAGMA_NONE test.c:5,4
@1 identifier_node strg: sum lngt: 3 addr: b7d82ce8
[LEXER: 39 ] CPP_EQ C_ID_NONE RID_MAX PRAGMA_NONE test.c:5,8
[LEXER: 40 ] CPP_NAME C_ID_ID RID_MAX PRAGMA_NONE test.c:5,10
@1 identifier_node strg: sum lngt: 3 addr: b7d82ce8
[LEXER: 41 ] CPP_PLUS C_ID_NONE RID_MAX PRAGMA_NONE test.c:5,14
[LEXER: 42 ] CPP_NAME C_ID_ID RID_MAX PRAGMA_NONE test.c:5,16
@1 identifier_node strg: i lngt: 1 addr: b7d82cb0
[LEXER: 43 ] CPP_SEMICOLON C_ID_NONE RID_MAX PRAGMA_NONE test.c:5,17
[LEXER: 44 ] CPP_CLOSE_BRACE C_ID_NONE RID_MAX PRAGMA_NONE test.c:6,2
[LEXER: 45 ] CPP_KEYWORD C_ID_NONE RID_RETURN PRAGMA_NONE test.c:7,2
@1 identifier_node strg: return lngt: 6 addr: b7cfd3f0
[LEXER: 46 ] CPP_NAME C_ID_ID RID_MAX PRAGMA_NONE test.c:7,9
@1 identifier_node strg: sum lngt: 3 addr: b7d82ce8
[LEXER: 47 ] CPP_SEMICOLON C_ID_NONE RID_MAX PRAGMA_NONE test.c:7,12
[LEXER: 48 ] CPP_CLOSE_BRACE C_ID_NONE RID_MAX PRAGMA_NONE test.c:8,1
[LEXER: 49 ] CPP_EOF C_ID_NONE RID_MAX PRAGMA_NONE test.c:9,0说明:
上述的词法分析过程是通过在c_lex_one_token (c_parser *parser, c_token *token)函数的末尾增加了dump_a_token(token)函数调用得到的输出结果。该结果描述了词法分析时,对源文件中的代码进行逐一分析,形成词法符号的过程。
上述输出结果包含两类内容,第一类是以'\[LEXER: [0-9]*\]'起始的行,描述了词法分析过程所解析出来的当前符号信息,包括该词法符号的类型、标识符类型、关键字值、编译制导类型以及该词法符号在源文件中的位置等基本信息。
而第二类信息则是以^@开头的行,描述了词法分析的过程中,在解析出了当前词法符号的信息后,是否需要创建相应的AST树节点,如果需要创建,则创建相应的树节点信息,如果不需要创建,则没有该部分的输出信息。
下面对上述dump-token文件的内容做一些简单的解释。
1. 先来看第一个词法解析的符号,如上述结果中的开始部分,包括两行信息:
[LEXER: 1 ] CPP_KEYWORD C_ID_NONE RID_INT PRAGMA_NONE test.c:1,1
@1 identifier_node strg: int lngt: 3 addr: b7cfd348第一行给出了词法分析得到的第1个词法符号的基本信息,从该词法符号的位置信息“test.c:1,1” 可以看出(当然,从第二行中strg的值“int”也可以看出),第一个成功解析的词法符号应该就是源代码中开始的“int”这个字符串,词法分析的结果表明,源代码中的第一个“int”字符串被解析为一个CPP_KEYWORD,其类型为C语言的关键字,标识符类型为C_ID_NONE,其其应的关键字的索引值是RID_INT,编译制导标志为PRAGMA_NONE,即该词法符号不是编译制导的标志,该词法符号在源代码中出现的位置是在文件test.c的第1行第1列。
由于词法分析的过程已经确定了该词法元素不但是一个标识符,而且是一个语言保留的标识符(即关键字),因此词法分析的过程中就为该标识符创建一个标识符节点,该标识符的名称为“int”,如上面第2行所示,其内存地址在0x b7cfd348。
通过gdb调试也可以验证该结果:
(gdb) b dump_a_token
Breakpoint 1 at 0x80a8663: file ../.././gcc/c-parser.c, line 214.
(gdb) r test.c
Breakpoint 1, dump_a_token (flag=0, ct=0xbffff1e4) at ../.././gcc/c-parser.c:214
//输出当前符号
(gdb) print *ct
$2 = {type = 73, id_kind = C_ID_NONE, keyword = RID_INT, pragma_kind = PRAGMA_NONE, value = 0xb7cfd348, location = 74}
//输出该词法符号的值节点信息
(gdb) print *(struct tree_identifier *) (ct->value)
$3 = {common = {base = {code = IDENTIFIER_NODE, side_effects_flag = 0,
constant_flag = 0, addressable_flag = 0, volatile_flag = 0,
readonly_flag = 0, unsigned_flag = 0, asm_written_flag = 0,
nowarning_flag = 0, used_flag = 0, nothrow_flag = 0, static_flag = 0,
public_flag = 0, private_flag = 0, protected_flag = 0,
deprecated_flag = 0, saturating_flag = 0, default_def_flag = 0,
lang_flag_0 = 1, lang_flag_1 = 0, lang_flag_2 = 0, lang_flag_3 = 0,
lang_flag_4 = 0, lang_flag_5 = 0, lang_flag_6 = 0, visited = 0,
spare = 0, ann = 0x0}, chain = 0x0, type = 0x0}, id = {
str = 0xb7cf3878 "int", len = 3, hash_value = 4294931189}
}可以看出,该词法符号所创建的树节点为一个标识符节点(其TREE_CODE为IDENTIFIER_NODE),其描述的字符串为"int"。
2. 下面再来分析源代码中第2行代码的词法分析过程。第2行源代码为:int i=0; 对应的词法分析过程如下:
[LEXER: 14 ] CPP_KEYWORD C_ID_NONE RID_INT PRAGMA_NONE test.c:2,2
@1 identifier_node strg: int lngt: 3 addr: b7cfd348
[LEXER: 15 ] CPP_NAME C_ID_ID RID_MAX PRAGMA_NONE test.c:2,6
@1 identifier_node strg: i lngt: 1 addr: b7d82cb0
[LEXER: 16 ] CPP_EQ C_ID_NONE RID_MAX PRAGMA_NONE test.c:2,7
[LEXER: 17 ] CPP_NUMBER C_ID_NONE RID_MAX PRAGMA_NONE test.c:2,8
@1 integer_cst type: @2 low : 0 addr: b7cefccc
@2 integer_type name: @3 size: @4 algn: 32
prec: 32 sign: signed min : @5
max : @6 addr: b7cfe2d8
@3 type_decl name: @7 type: @2 srcp: <built-in>:0 addr: b7cfe680
@4 integer_cst type: @8 low : 32 addr: b7cef690
@5 integer_cst type: @2 high: -1 low : -2147483648 addr: b7cef63c
@6 integer_cst type: @2 low : 2147483647 addr: b7cef658
@7 identifier_node strg: int lngt: 3 addr: b7cfd348
@8 integer_type name: @9 size: @10 algn: 64
prec: 36 sign: unsigned min : @11
max : @12 addr: b7cfe068
@9 identifier_node strg: bit_size_type lngt: 13 addr: b7cfd9a0
@10 integer_cst type: @8 low : 64 addr: b7cef78c
@11 integer_cst type: @8 low : 0 addr: b7cefc08
@12 integer_cst type: @8 high: 15 low : -1 addr: b7cefbd0
[LEXER: 18 ] CPP_SEMICOLON C_ID_NONE RID_MAX PRAGMA_NONE test.c:2,9第1个词法符号:关键字(int),并为之创建树节点identifier_node,节点地址为0xb7cfd348,从该地址值可以看出,该标识符节点与第1行创建的标识符节点为同一个节点。
[LEXER: 14 ] CPP_KEYWORD C_ID_NONE RID_INT PRAGMA_NONE test.c:2,2
@1 identifier_node strg: int lngt: 3 addr: b7cfd348第2个词法符号:标识符(i),并为之创建树节点identifier_node,节点地址为0xb7d82cb0。
[LEXER: 15 ] CPP_NAME C_ID_ID RID_MAX PRAGMA_NONE test.c:2,6
@1 identifier_node strg: i lngt: 1 addr: b7d82cb0第3个词法符号:等于符号(=),未创建树节点。
[LEXER: 16 ] CPP_EQ C_ID_NONE RID_MAX PRAGMA_NONE test.c:2,7第4个词法符号:数值(0),并为之创建树节点integer_cst,该整数常量节点的地址为0xb7cefccc。
[LEXER: 17 ] CPP_NUMBER C_ID_NONE RID_MAX PRAGMA_NONE test.c:2,8
@1 integer_cst type: @2 low : 0 addr: b7cefccc
……//省略部分AST节点
@12 integer_cst type: @8 high: 15 low : -1 addr: b7cefbd0需要说明的是,为了创建一个整数常量节点,还需要创建其它相关的节点来描述该整数常量节点的一些属性,因此,此处共创建了12个树节点,图4-24给出了围绕该词法符号(整数常量0)的分析而创建的多个AST节点及其相互关系。(图示方法可以参见AST图示)
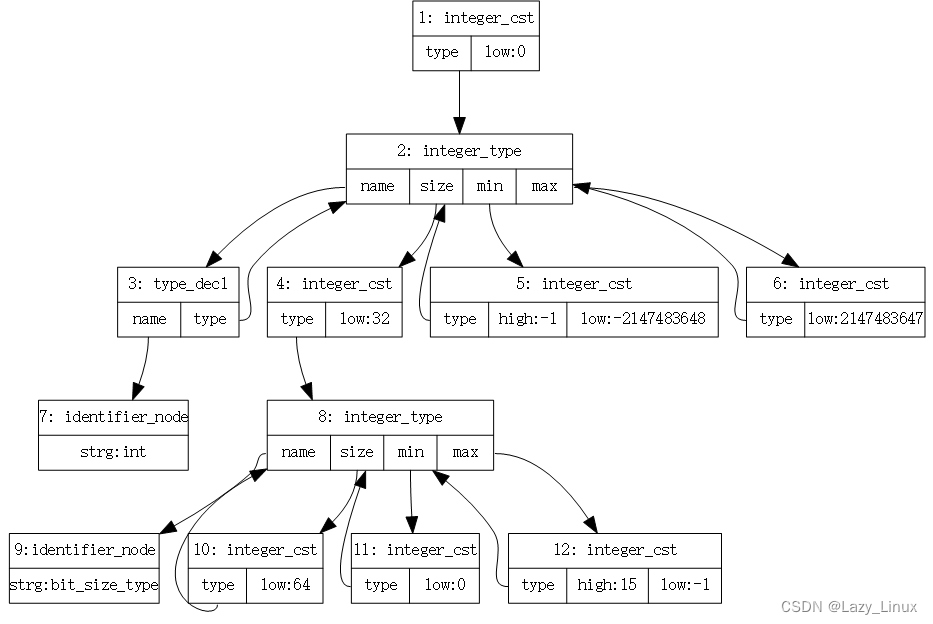
图4-24 词法分析中整数常量0对应的AST
第5个词法符号:分号(;)
[LEXER: 18 ] CPP_SEMICOLON C_ID_NONE RID_MAX PRAGMA_NONE test.c:2,9到此为止,源代码中第2行分析完毕,其它词法分析过程不再赘述。
从上述分析可以看出,词法分析的过程就是将源代码识别成一个一个的词法符号,并在词法分析的过程中,创建一些树节点,用来保存某些词法符号的值(value)。这些需要创建树节点的词法符号主要包括标识符(CPP_NAME)、关键字(CPP_KEYWORD)、数值(CPP_NUMBER)常量等。在后续的语法分析过程中,会将这些AST节点(或者AST子树)根据语法规则链接起来,形成某个函数完整的AST结构。