 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
引言
有幸作为设计者之一深度参与了腾讯云新一代时序数据库CTSDBi从零到上云的全过程,时常感叹底层架构团队确保交付稳定产品是一件多么具有挑战的事情。如何在复杂,异常场景中提前发现,解决问题是我们一直在探索的事情。
SOSP 2021 Best Paper之一[2]向我们展示了S3 ShardStore 是如何将轻量级形式化验证方案纳入日常工作,并在形式化验证的初始框架由专业人员建立完成后由系统开发人员维护此框架,虽然细节复杂,但是思路通用,基本分为以下三步:
- 使用定义了系统预期行为的
reference models来定义系统的预期语义。reference models定义了系统中各个组件允许的执行顺序与crash-free behaviors,并大量复用。从论文和我们的实践经验看,嵌入代码库的优势是巨大的,这样可以允许开发人员可以在本地验证,大规模节省人力成本(测试资源协调);目前我们的方案是1. minikube+本地验证框架 2. 实际部署集群+远程验证框架 - 通过检查是否完善了
reference models,来验证现有的实现是否满足预期的correctness properties;为了充分使用现有的生态,对需要验证的属性进行分解:- functional correctness:基于
property-based testing验证reference models与实现在随机序列下结果是否一致 - crash consistency:扩展
reference models,以允许在宕机期间丢失部分没有完全写入成功的数据保持元数据一致性;并在此基础上基于property-based testing验证出现宕机时是否满足新的reference models - concurrency:使用
stateless model checking,证明操作是可线性化,且正确的
- functional correctness:基于
- 推动工程师团队负责
reference models与相关检查,保证在初始框架完成后的存活时间,并采用覆盖率检查保证新功能不会被遗漏,旧功能始终可运行。
虽然行业内将完整形式化验证应用在大规模分布式系统已经有了非常多的先例,如Amazon,Intel,Microsoft 等[3],但是在有限的人力下在软件迭代,测试,运营,客户对齐中抽身来引入形式化验证仍旧是一件奢侈的事。原因是并不是所有的团队都有形式化验证相关人才,且复杂的验证带来的收益在软件不同时期收益是不一样的。
其次使用TLA+描述全部模块的算法,以及使用类似loom等全量检查的stateless model checking来做完善的形式化验证人力/时间投入过大,对于大规模复杂系统实施完全的形式化验证基本不太现实,所以S3给我们提供了一种非常值得工程实践的一条路,用轻量级形式化验证替代完整的形式化验证,在项目起步阶段这是一个ROI极高的事情。
聊完一个稳定交付的方法,我们再来看看如何在软件工程中应用的现实复杂性,PingCAP唐刘大佬在评估和增强软件质量时的现实经验[1][4][5][6]值得学习。
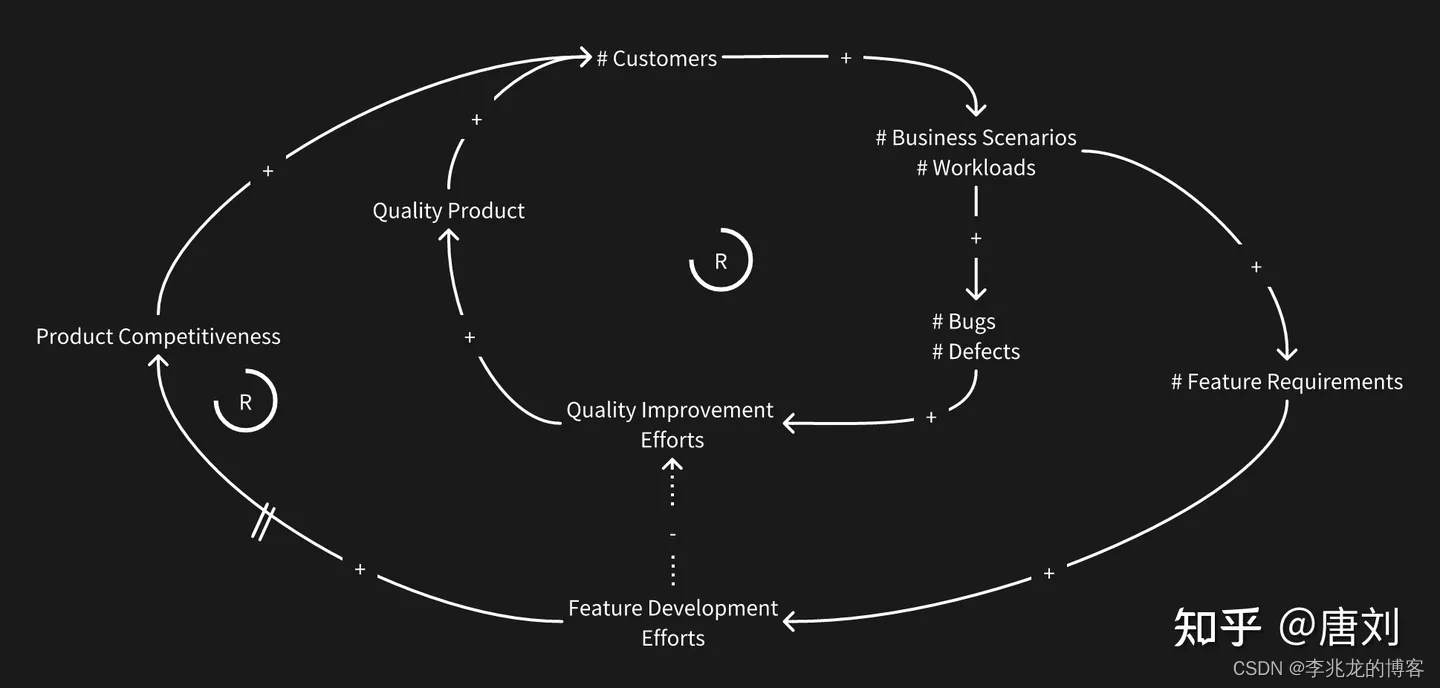
- 更多的功能意味着更多的bug,研发的带宽是一个物理约束,公司不可能无限制的增加研发资源。当我们投入更多的研发带宽去研发新的功能时候,不但会带来更多的bug,占用研发带宽,还会挤占质量改进的带宽,造成更多的bug。控制新功能的数量的同时,需要谋求功能开发和质量的一个平衡点。PingCAP的做法是研发 leader 跟 PM 达成共识,评估好这一段时间 team 的带宽投入,譬如投入整个 team 40% 的人力带宽开发新的 feature,40% 的人力带宽去做质量改进和架构重构,剩下的带宽就做 oncall,客户 support,或者个人成长相关的事情等。
- 软件模块化应对复杂性,保证UT的本地验证高效性,和ST的稳定性,节省开发人力。
- 使用Bug 收敛率来评估产品的质量,而不是bug数量,有竞争力的功能总会带来bug,bug 多不一定意味着质量不好。
- 2-8原则,20% 的客户几乎贡献了 80% 的问题,只要我们能深入的理解我们 20% 的重要的客户的当前的业务场景,基于这些场景去开发测试用例,我们至少能保证当前阶段大部分场景不会掉链子。
- 复杂的代码几乎一定存在bug,简洁设计绝大多数场景优于复杂设计。

复杂系统的质量并非一蹴而就,而是遵循客观事实逐步演进的,稳定产品的测试最佳实践唯有 Early、Continuous。
ShardStore架构概述
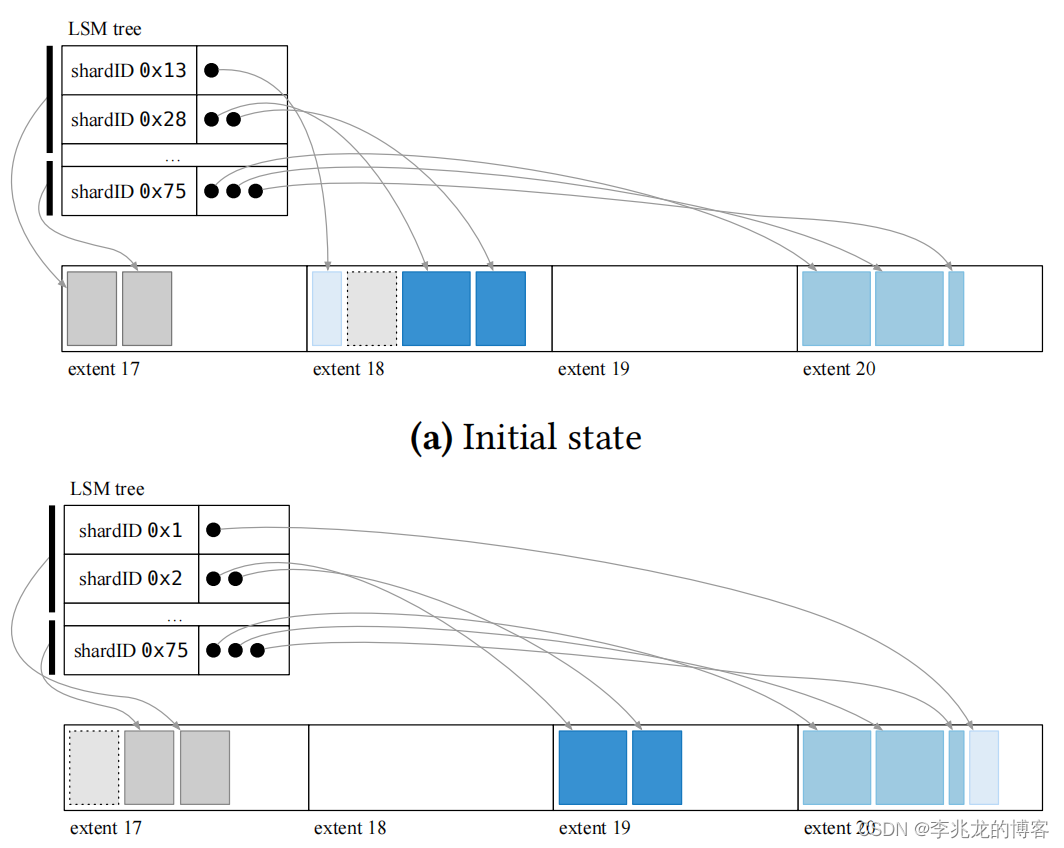
ShardStore为S3系统的其他部分提供了一个键值存储接口,对外接口 key是shard identifiers,value是shards of customer object data。
ShardStore 的键值存储包括一颗LSM 树,但碎片数据存储在树外,以减少写放大,类似于 WiscKey。上图显示了 LSM 树如何在磁盘上存储对象数据,LSM 树将shard identifiers映射到一个指向分块的指针的分块列表,每个分块存储在一个extent内。extent是磁盘上物理存储的连续区域;一个磁盘有数万个extent。ShardStore 要求在每个范围内的写入都是连续的,由定义了下一个有效写入位置的写入指针进行跟踪,因此一个范围内的数据不能被立即覆盖。每个extent都有一个reset操作,用于将写指针重置到extent的起始位置并允许覆盖。
ShardStore 并未将所有shard data 集中到磁盘上的单个文件中中,而是将shard数据分散到各个extent中。这种方法让我们可以灵活地将每个分片的数据放在磁盘上,以优化预期热键和访问模式(最大限度地减少寻道延迟),毕竟作为对象存储的存储层,用的都是HDD,磁带等存储介质,定制化管理访问模式确实有好处。
Chunk storage and chunk reclamation
所有持久化数据都以chunks为单位存储,包括 LSM 树本身的数据存储。chunk store 就是把chunks映射到 extents
chunk store 提供的接口为:
- PUT(data) → locator
- GET(locator) → data interfaces
locators 是一个不透明的chunk identifiers,被用作指针。
extents是append only的,因此删除shard后无法立即释放该shard的chunks所占用的可用空间。为了恢复和重新利用空闲空间, chunk store有一个reclamation background task来执行垃圾回收。Reclamation 选择一个范围并对其进行扫描,以找到其存储的所有chunks。对于每个chunk,reclamation background task 都会在LSM 树中执行reverse lookup,LSM树中仍被引用的chunk会被转移到到新的extent,并在LSM树中更新其指针,而未被引用的chunks则会被直接丢弃。
一旦整个extent被扫描完毕,其写指针就会被重置,并可重新使用。重置一个范围的写指针会导致该范围内的所有数据都不可读。
其次ShardStore提供了Append-only语义,其实现了extent append operation写入系统调用,它通过在内存中跟踪每个extent的写入指针,在内部转化extent的appends操作为写系统调用,并定期持久化每个extent的写指针在superblock。
因此,chunk store 必须保证chunk evacuations, index updates, extent resets, Append-only的crash-consistent。
soft updates保证元数据一致性
ShardStore 使用一种类似于soft updates的crash consistency方法 [7]。其通过定义写入磁盘的依赖顺序,确保磁盘的崩溃状态是一致的。soft updates避免了写一个共享文件(我理解是memtable),并允许在磁盘上灵活地放置数据。soft updates需要对全局写盘顺序进行定义。ShardStore’s implementation specifies crash-consistent orderings declaratively, using a Dependency type to construct dependency graphs at run time that dictate valid write orderings. ShardStore’s extent append operation, which is the only way to write to disk, has the type signature:
fn append(&self, …, dep: Dependency) -> Dependency
both taking as input and returning a dependency. The contract for the append API is that the append will not be issued to disk until the input dependency has been persisted. ShardStore’s IO scheduler ensures that writebacks respect these dependencies. The dependency returned from append can be passed back into subsequent append operations, or first combined with other dependencies (e.g., dep1.and(dep2)) to construct more complex dependency graphs. Dependencies also have an is_persistent operation that clients can use to poll the persistence of an operation.
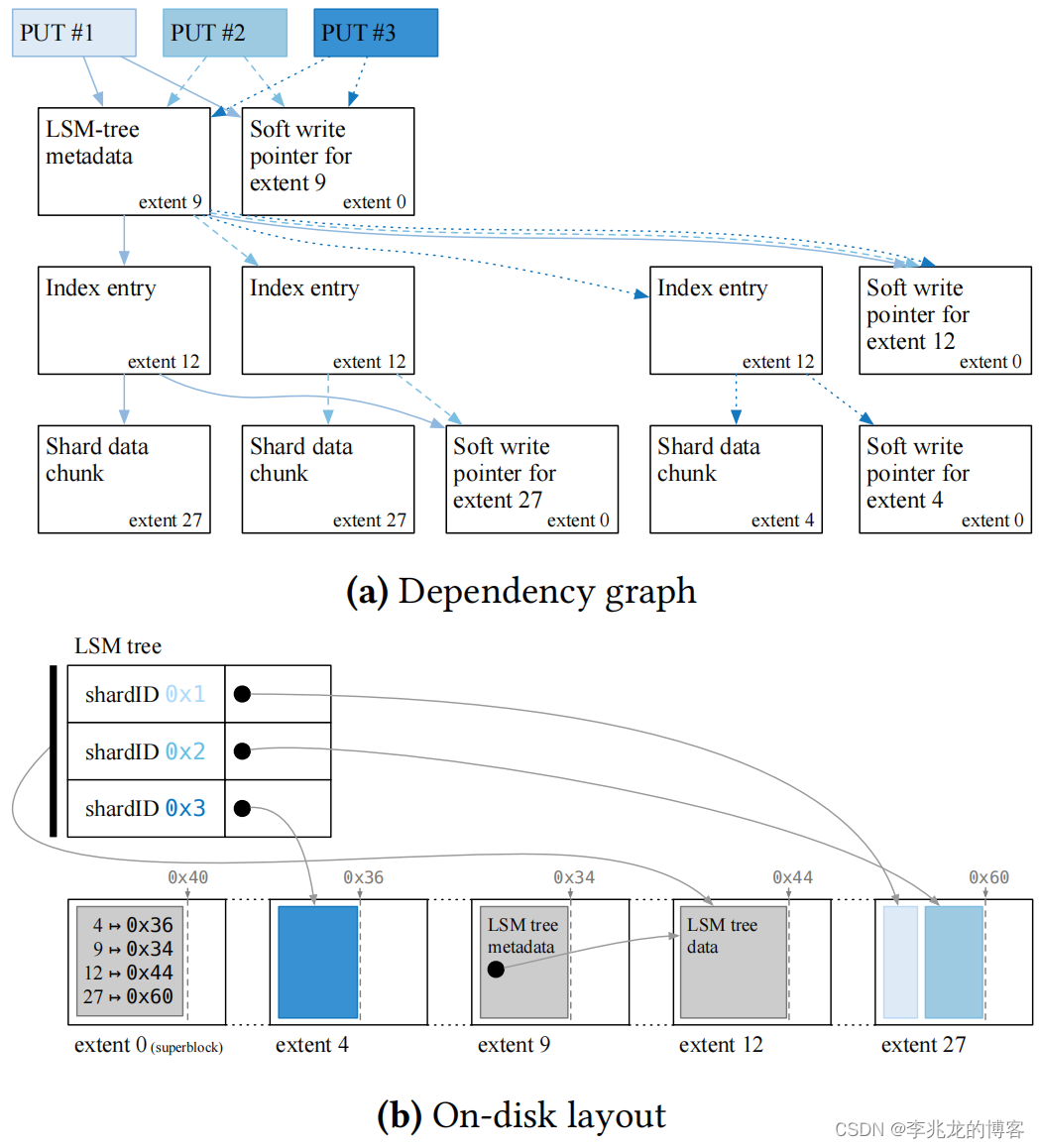
上图展示了 ShardStore 的三个 put 操作的依赖图:
- the shard data is chunked and written to an extent。value
- the index entry for the put is flushed in the LSM tree。locator->point
- the metadata for the LSM tree is updated to point to the new on-disk index data。meta data,比如索引块的分布
除了这些写入之外,每次ShardStore append一个extent时,它还会更新superblock的soft write pointer。
可以看到这种方式可以因为每一次Put都把依赖关系定义为了一个有向无环图,在出现故障时如果一个操作没有操作完成,可以基于已经存在的依赖回退指针把磁盘恢复到一致状态,保证不会出现index和data不一致的情况。
实现逻辑还是比较复杂的,不愧是AWS,一般团队不敢玩这种项目。也不清楚这种直接写盘的方法带来的允许在磁盘上灵活地放置数据的优势有多大的性能/成本提升,能让AWS下定决心搞这个项目。看起来磁盘利用率这样做会非常高,但是写吞吐会很低,也符合对象存储数据层的特征(正常的LSM写完WAL就可以返回了,chunkstore需要至少三次IO操作,这也是chunkstore需要如此谨慎的验证正确性的原因,因为这些IO操作不是原子的,需要保证崩溃一致性)。但是数据恢复和正确性验证真的会非常复杂。
有一个疑问,不知道这里的依赖是如何持久化的,需要有时间看下[7]。
验证ShardStore
首先是分解验证的优先级,对于S3这样一个世界顶级的存储系统,每个模块都一个复杂的独立系统,而全局的测试无法测试到单独模块的细节,比如:
- functional correctness of API-level calls
- crash consistency of on-disk data structures
- correctness of concurrent executions including API calls
- maintenance tasks like garbage collection,compact
而系统又处于不断的迭代,所以建立独立模块的可迭代形式化验证方案至关重要。(这个磁盘操作太复杂了,和一般的LSM Tree不是一个级别)。
生产系统的行为符合预期可以分为以下方面:
- durable in the absence of crashes
- consistent in the presence of crashes and concurrency
- highly available during normal operation
- performance goals
在文章中聚焦于durable,consistent与API correctness。
具体的思路是定义一个Reference Models,其在非crash和非并发的情况下预期模型与meta store保持同样的输出,而在crash可能导致参考模型不允许的数据丢失,而并发允许操作重叠,这意味着当我们在每次 API 调用后检查等效性时,并发操作可能正在进行中。所以S3团队将验证分为如下三个阶段。
注意这里并没有验证可用性和性能,本质是因为S3系统验证模块已经足够成熟,这些指标可以通过已有的验证来取得结论,当然放到平时的验证也没问题,只是文中列举的是正确性相关的必要条件,可以用形式化验证做,而性能和可用性不能归属到正确性。
sequential crash-free
上文提到chunk store的正确性校验使用Property-Based Testing,其为测试用例生成输入
伪码相对好理解,即从定义的行为中生成操作序列,并保证模型和chunk store在每个操作成功后校验输出是否等价。这里文中提到了一些实践经验值得学习:
- Argument bias:需要达成的一致是不可能测试到所有情况,所以操作的参数是可以倾向于随机的,但是部分参数也需要定义一个偏差范围,类似于读写接近磁盘页面大小的情况,
- Coverage metrics:随着功能的迭代困难会出现新的API,可能会出现缓存之类的组件影响现有的测试,所以需要为形式化测试添加覆盖率检查
- Minimization:在出现错误序列时需要最小化序列,以减轻排查问题的负担,通常是通过减少序列中的操作数,直到不再失败。
sequential crashing
之前提到chunk store因为soft update的复杂性导致宕机重启的一致性很难保证(单个操作多次IO不是原子的),chunk store的 crash consistency 属性如下:
- persistence:如果dependency表明某个操作在宕机之前已经持久化,则在启动后该操作应该可读(除非被后续持久化操作取代)
- forward progress: 在正常关闭后,每个操作的dependency都应表明它是持久化的
为了实现上述检查,在操作表中引入了DirtyReboot(RebootType)操作,RebootType 可以选择是否flush the in-memory section of the LSM-tree,或者 flush buffer cache。
concurrent crash-free
程序的并发正确性在不引入工具的情况下是个非常复杂的工程问题。chunk store使用stateless model checking来对并发下的一致性和死锁做校验。chunk store使用Loom和Shuttle作为stateless model checking,文中提到这两个工具是CDSchecker[8]算法的开源实现。
CDSchecker建模的大体思路如下:
- 线程建模: CDSchecker 将每个线程视为一个执行序列,其中包含对共享变量的操作和同步原语的使用。
- 共享变量: 它跟踪所有线程共享的变量,以及对这些变量的读写操作。
- 同步原语: CDSchecker 理解并模拟了各种同步原语(如互斥锁、条件变量、原子操作等)的行为。
- 执行轨迹: 它通过生成线程的所有可能执行轨迹来模拟并发执行。
可以看到当程序复杂后模拟全部的执行路径几乎是不现实的。CDSchecker引入 Bounded Partial-Order Reduction减少并发程序状态空间,从[9]的介绍章节可以看到这是一种结合以下两种现有技术的方法:
partial-order reduction:,利用了并发程序中操作的可交换性。在并发程序中某些操作可能与其他操作无关,可以在不影响程序最终结果的情况下以不同的顺序执行,POR通过识别这些独立的操作来减少不必要的状态探索。bounded search:通过控制控制上下文切换的数量来减少状态空间。
Loom是校验全量的状态(使用了bounded partial-order reduction的技术减少状态),而Shuttle是AWS专为chunk store开发的,只校验全量状态的一部分,虽然无法保证每次校验的绝对正确性,但是可以把这样的技术应用到更大范围的测试。
结束语
令人羡慕的是这样的形式化验证方法由三位形式化验证专家共消耗7月/人完成,并处于持续维护的状态,一个非常乌托邦式的软件工程实践,不愧为SOSP 2021最佳论文,也怪不得S3如此领先,这样的管理模式在搭建起来以后强调组织大于个人,可以保证产品的质量下限不随人员流动而改变,也更容易延长产品寿命,不至于后来者不敢动代码导致烂尾。
参考:
- 关于产品质量的思考 - UT in TiDB
- Using Lightweight Formal Methods to Validate a Key-Value Storage Node in Amazon S3 sosp2021
- TLA+官网
- 关于产品质量的思考 - 我的基本认知
- 关于产品质量的思考 - 测试的窘境
- 关于产品质量的思考 - 如何评估质量
- Metadata Update Performance in File Systems OSDI 1994
- CDSchecker: checking concurrent data structures written with C/C++ atomics OOPSLA '13
- Bounded partial-order reduction